멱법칙 Hawkes 과정의 구조적 비식별성
Spock 캐스케이드 재현 검증과 그 함의
Structural Non-Identifiability of Power-Law Hawkes Processes: A Reproduction Audit of the Spock Retweet Cascade
Abstract (English). We attempt to reproduce the marked power-law Hawkes fit reported for the "Spock" retweet cascade (Rizoiu et al., 2017) and find that an unconstrained maximum-likelihood estimate (MLE) does not recover the reported parameters: the free fit reaches a supercritical plug-in branching ratio (n* ≈ 1.19) by moving along a flat likelihood ridge to a parameter vector unrelated to the reported one, whereas applying the closed-form branching-ratio relation of Mishra et al. (2016) as an estimation constraint recovers n* = 0.92, matching the literature. Rather than treating this as a failed reproduction, we trace its cause. A three-phase synthetic recovery study shows that our likelihood code is correct — it recovers the exponential-kernel branching ratio to within gate tolerance at n* = 0.7 and 0.9 — yet fails to identify the power-law kernel parameters (α, δ, η) even on synthetic data of 400–1900 events with known ground truth, with the failure worsening as the process approaches criticality. A direct test of the marked kernel across three branching-ratio regimes confirms the same pathology and locates its mechanism: the mark exponent β is systematically over-estimated — increasingly so toward criticality (median β̂ 1.14 → 1.65 → 1.63 against a true 1.3) — inflating the mark moment E[m^β] and driving median n* estimates from 0.16 to 18.4 against true values of 0.3 to 0.9. On the real cascade, the five best fits span six orders of magnitude in the kernel scale κ while differing in negative log-likelihood by only ~0.04 — the direct signature of a flat likelihood ridge; κ is not identified, and the implied branching ratios stay supercritical (1.19–1.24) across the ridge. An independent Hardiman–Bouchaud estimator places the cascade firmly subcritical (n̂ = 0.51–0.88). Extending beyond the single case to 80 cascades from the ACTIVE dataset, we find that faithfully reproducing the authors' n* < 1 constraint keeps 91% subcritical, yet ~46% pile up exactly at the constraint boundary (n* ≈ 0.92), and the closed-form depends on a mark-distribution exponent α = 2.016 that mismatches the empirical median of 1.18 — voiding the formula in 55% of cascades. We conclude that the power-law Hawkes kernel — both unmarked and marked — is structurally non-identifiable in the regime relevant to social-media cascades, and that the reported subcritical branching ratio is determined jointly by the estimation constraint and the mark-distribution assumption rather than by the data alone.
초록 (국문). 본 연구는 Rizoiu et al.(2017)[2]이 "Spock" 리트윗 캐스케이드(retweet cascade)에 대해 보고한 표시 멱법칙 Hawkes 적합을 재현하려는 시도에서 출발한다. 제약 없는 최대우도추정(maximum likelihood estimation, 이하 MLE)은 보고된 모수를 복원하지 못한다 — 자유 적합은 평탄한 우도 능선을 따라 보고값과 무관한 모수 벡터로 이동해 초임계 분기율(n* ≈ 1.19)에 도달하는 반면, Mishra et al.(2016)[3]의 닫힌형 분기율 관계식을 추정 제약으로 부과하면 문헌값 n* = 0.92가 복원된다. 우리는 이 불일치를 단순한 재현 실패로 두지 않고 그 원인을 규명한다. 3단계 합성 복원 실험은 우리 우도 코드가 정당함을 보인다(지수 커널에서 n* = 0.7, 0.9를 허용오차 기준 내로 복원). 그럼에도 멱법칙 커널의 (α, δ, η)는 참값을 아는 4001900 이벤트 합성 데이터에서조차 식별되지 않으며, 임계점에 가까워질수록 악화된다. 표시(marked) 커널을 세 분기율 설정에서 직접 시험하면 같은 비식별이 확인되고 그 메커니즘이 드러난다 — 표식 지수 β가 체계적으로 과대추정되며 임계로 갈수록 심해지고(β̂ 중앙값 1.14→1.65→1.63, 참값 1.3), 이것이 표식 모멘트 E[m^β]를 부풀려 n* 중앙값을 참값 0.30.9에 대해 0.1618.4로 발산시킨다. 실데이터에서 상위 5개 적합은 커널 스케일 κ에서 6자릿수에 걸쳐 분포하면서 음의 로그우도(negative log-likelihood, 이하 NLL)는 약 0.04밖에 차이 나지 않는다 — 평탄한 우도 능선(ridge)의 직접적 징표다. κ는 식별되지 않으며, 능선 위 모든 점에서 함의 분기율은 초임계(1.191.24)로 유지된다. 독립적 Hardiman–Bouchaud 추정량은 캐스케이드를 명확히 아임계(subcritical)로 둔다(n̂ = 0.51~0.88). 단일 사례를 넘어 ACTIVE 데이터셋의 캐스케이드 80개로 확장하면, Mishra et al.(2016)[3]의 n* < 1 제약을 충실히 재현할 때 91%가 아임계로 묶이나 그중 약 46%가 제약 경계(n* ≈ 0.92)에 정확히 부착되며, 닫힌형이 가정하는 표식 분포 지수 α = 2.016은 실측 중앙값 1.18과 어긋나 표본의 55%에서 공식이 무효가 된다. 결론적으로, 멱법칙 Hawkes 커널은 표시·비표시 모두 소셜미디어 캐스케이드에 해당하는 영역에서 **구조적으로 비식별(structurally non-identifiable)**이며, 보고되는 아임계 분기율은 데이터 단독이 아니라 추정 제약과 표식 분포 가정이 함께 결정하는 산물이다.
Keywords. Hawkes process, branching ratio, structural non-identifiability, likelihood ridge, retweet cascade, reproduction audit
1. 서론 (Introduction)
자기여기 Hawkes 과정(self-exciting Hawkes process)은 과거 이벤트가 미래 이벤트의 발생률을 끌어올리는 점과정(point process)으로, 지진 여진, 고빈도 금융 거래, 소셜미디어 정보확산을 같은 수리 틀로 다룬다. 그 핵심 요약 통계량이 분기율 n이며, 이는 한 이벤트가 평균적으로 유발하는 후속 이벤트 수다. n < 1이면 캐스케이드가 유한하게 소멸(아임계)하고, n* → 1이면 임계, n* ≥ 1이면 폭발(초임계)한다. 따라서 n*은 "이 확산이 외생적으로 주도되는가, 내생적으로 자기증폭되는가"를 정량화하는 지표로 널리 쓰인다.
분기율 추정이 함정에 빠질 수 있다는 사실은 금융 Hawkes 문헌에서 오래 축적되어 왔다. Filimonov & Sornette(2015)[1]는 고빈도 금융 데이터에서 멱법칙 메모리 커널을 쓸 때 분기율 추정에 네 가지 내재적 편향(이상치에 의한 상향 편향, 커널 정규화 형태의 영향, edge effect, 복잡한 우도면으로 인한 전역 최댓값 탐색의 필요)이 있음을, 특히 생성 과정에 레짐 변화가 섞이면 참값이 n=0인데도 추정값이 임계(n≈1)로 허위 수렴함을 보였다. Hardiman & Bouchaud(2014)[4]는 바로 이 우도면 병리(국소 대 전역 최소값) 때문에 우도가 아닌 카운트 모멘트(평균·분산)에서 분기율을 추정하는 추정량을 제안했고, Wheatley, Wehrli & Sornette(2019)[7]는 더 정밀한 endo–exo 분석으로 금융 데이터의 임계성 주장을 반박했다.
그러나 이 경고는 소셜미디어 Hawkes 문헌과 거의 연결되지 않았다. 우리가 조사한 범위에서, Rizoiu, Mishra, Xie 계열의 소셜미디어 확산 모델링 연구(Mishra et al. 2016; Rizoiu et al. 2017, 2018, 2022)는 동일한 멱법칙 커널과 우도 기반 추정 절차를 사용하면서도 Filimonov–Sornette(2015)[1]나 Hardiman–Bouchaud(2014)[4]를 인용하지 않는다. 여기서 핵심은 이 단절을 메우는 것이 아니라, 그 단절이 가린 사실 — 분기율 추정의 불안정성은 데이터가 금융이냐 소셜이냐의 문제가 아니라 멱법칙 커널이라는 수학적 대상 자체의 성질이라는 점 — 을 소셜 데이터에서 직접 측정하는 것이다. 금융 문헌은 같은 커널의 같은 병리가 다른 도메인에서도 독립적으로 보고됨을 보이는 수렴 증거(converging evidence)로만 참조한다.
대상은 Rizoiu et al.(2017, "A Tutorial on Hawkes Processes for Events in Social Media", arXiv:1708.06401)이 단일 수치 예제로 사용한, New York Times의 트윗(레너드 니모이 사망 보도)에서 비롯된 "Spock" 리트윗 캐스케이드다. 그들은 표시 멱법칙 Hawkes를 적합해 n* = 0.92를 보고했다. 그런데 이 0.92는 자유 최대우도 추정값이 아니다 — 그들의 절차는 n < 1을 비선형 제약으로 명시적으로 부과*하며(Ipopt 사용; 공개 R 코드 marked_hawkes.R의 constraint_ub <- log(1 − ε)), 이는 초임계 해를 추정 공간에서 원천 배제한다. 논문 본문은 0.92를 점추정처럼 제시하지만, 제약이 그 식별을 떠받치고 있다.
우리의 출발 질문은 두 갈래다. (Q1) 이 제약을 풀면 커널 모수는 식별되는가? (Q2) 라는 식별성은 데이터에서 오는가, 아니면 제약에서 오는가? 본 논문은 (i) 자유 MLE가 무엇을 내는지, (ii) 그 결과의 비식별이 우리 구현의 결함인지 모델의 성질인지, (iii) 그것이 표본 크기 탓인지 커널 구조 탓인지, (iv) 그럼에도 캐스케이드의 아임계 여부에 대한 결론이 추정 방법과 무관하게 유지되는지를 차례로 가른다. 본 연구의 기여는 새로운 분기율 값을 보고하는 것이 아니다 — 제약 MLE와 H-B 추정량이 가리키는 Spock의 아임계 결론은 Rizoiu et al.(2017)[2]의 와 정합적이다. 기여는 세 가지다. 첫째, 보고된 분기율을 떠받치는 추정 절차의 제약을 명시적으로 드러낸다. 둘째, 멱법칙 커널의 비식별성을 — 금융 결과의 이식이 아니라 — 참값을 아는 합성 데이터와 소셜 실데이터에서 직접 측정한다(§4.3–§4.7). 셋째, 그 측정을 통해 보고되는 아임계 분기율이 데이터 단독이 아니라 추정 가정에 의해 결정됨을 보인다.
1.1 관련 연구와 본 연구의 위치 (Related Work)
금융 Hawkes 임계성 문헌. Hardiman, Bercot & Bouchaud(2013)[5]는 E-mini S&P 데이터에서 멱법칙 커널이 분기율 1에 가깝게 적분됨(near-critical)을 보고했고, Filimonov & Sornette(2015)[1]는 그 "겉보기 임계성(apparent criticality)"의 상당 부분이 추정 편향임을 네 가지 기전으로 분해했다. Hardiman & Bouchaud(2014)[4]는 우도면의 국소/전역 최소값 문제를 우회하는 모멘트 추정량을 제시했고, Wheatley, Wehrli & Sornette(2019)[7]는 임계성 주장을 더 보수적으로 재평가했다. 일반 Hawkes MLE의 우도면 병리도 별도로 보고되어 있다 — Lemonnier & Vayatis(2014)[8]는 지수 커널에서 감쇠율을 고정해야 효율적 추정이 가능함을, Santos, Lemmerich & Helic(2021)[9]은 지수 커널 감쇠 모수의 우도면이 평탄·비볼록한 분지(basin)를 가짐을 실증했다.
소셜미디어 Hawkes 문헌. Mishra, Rizoiu & Xie(2016)[3]는 표시 멱법칙 Hawkes로 트윗 인기를 예측하며 분기율의 닫힌형 식과 n* < 1 제약을 도입했고, Rizoiu et al.(2017)[2]은 이를 교육 튜토리얼로 정식화했다(Spock 예제). 이후 SIR-Hawkes(Rizoiu et al. 2018)[10]는 HawkesN의 모집단 크기 N에 대한 비식별을, interval-censored Hawkes(Rizoiu et al. 2022)는 관측 구조를 다뤘다.
선행 연구와 본 연구의 위치. 위 두 계열은 동일한 멱법칙 커널과 우도 기반 추정 절차를 공유한다. 그럼에도 우리가 조사한 주요 문헌 범위에서는 소셜미디어 계열이 금융 계열의 편향·비식별 논의를 인용한 사례를 확인하지 못했다(이는 절대적 부재의 증명이 아니라 조사 범위 내의 관찰이다). 또한 Hardiman–Bouchaud 모멘트 추정량의 비금융 적용으로 우리가 확인한 사례는 분쟁 사건·지진학에 국한되며, 리트윗 캐스케이드에 적용된 사례는 발견하지 못했다. 비식별성이라는 현상 자체는 새롭지 않다 — Lemonnier & Vayatis(2014)[8]와 Santos et al.(2021)[9]이 이미 Hawkes 우도면의 평탄성을 보고했다. 본 연구의 기여는 (1) 그 비식별성을 표시 멱법칙 커널에서 — 즉 소셜미디어 모델링에 실제로 쓰이는 구체적 커널에서 — 참값을 아는 합성 데이터로 측정하고, (2) 그것을 Spock 실데이터 및 ACTIVE 캐스케이드에서 추정 방법 의존성으로 연결하며, (3) 비식별성이 데이터 도메인이 아니라 커널의 수학적 성질임을 보여 금융 문헌의 독립적 보고와 수렴함을 확인한 데 있다.
2. 배경 (Background)
2.1 커널과 분기율
이벤트 시각 에 대한 조건부 강도(conditional intensity, 과거가 주어졌을 때 시각 에서 단위시간당 이벤트 발생률)는
로 쓰며, 는 배경 강도(외생적으로 발생하는 기저율), 는 *트리거링 커널(triggering kernel)_이다. 커널이란 과거의 한 이벤트가 그 이후 시각의 발생률에 더하는 기여의 시간적 모양을 나타내는 함수로, 보통 시간이 지날수록 감소한다. 분기율은 커널의 전체 적분 로, 한 이벤트가 평균적으로 직접 유발하는 후속 이벤트 수에 해당한다. 본 연구가 다루는 세 커널은 다음과 같다.
- 지수 커널 (exponential kernel): , . 모수 2개. 본 연구에서 식별성이 양호한 기준 커널로 사용한다 — 즉 서로 다른 가 데이터에 충분히 다른 우도를 주어, 참값을 아는 합성 데이터에서 추정이 그 값을 안정적으로 되찾는다(§4.3에서 확인).
- 비표시 멱법칙 (unmarked power-law): , . 모수 3개. 모든 이벤트가 동일한 영향력을 갖는다.
- 표시 멱법칙 (marked power-law): , . 모수 . 각 이벤트에 크기 표식(mark) 이 붙고(는 그 표식이 영향력을 키우는 강도), 합성 실험에서 표식 분포는 로 둔다.
여기서 비표시와 표시의 차이는 영향력의 이질성에 있다. 비표시 모형에서는 모든 이벤트가 동일한 후속 영향력을 갖는 반면, 표시 모형에서는 각 이벤트가 자신의 표식 (예: 그 트윗을 올린 사용자의 팔로워 수)에 비례()하는 영향력을 갖는다 — 팔로워가 많은 사용자의 리트윗이 더 큰 2차 확산을 일으킨다는 직관을 반영한다.
정의에 관한 주의. 표시 모형의 분기율은 표식 모멘트 를 통해 에 초지수적으로 의존한다. 위 합성 표식 분포 가정(, 즉 표식의 확률분포에 대한 가정이며 사람 이름이 아니다)에서 이므로, 가 커질수록 가 급격히 증가한다 — 예컨대 가 일 때와 §4.6의 자유 적합에서 관측된 일 때를 비교하면 는 여러 자릿수 차이가 난다. 따라서 표시 은 뿐 아니라 와 표식 분포 가정에 극도로 민감하다. 본 논문에서 Spock 자유 적합의 분기율은 표식 공식으로 일관되게 계산하며, 적합된 에서 평가한 실측 표식 모멘트 를 사용한다(다중 시작점 중 음의 로그우도가 최소인 적합을 이하 fit_best라 한다). 에 대한 이 초지수적 의존성은 §4.6의 표시 합성 실험에서 이 발산하는 메커니즘이다. 다만 본 연구에서 얻은 특정 실데이터 적합에서는 이 발산이 나타나지 않는다(§4.2).
2.2 비식별성이란 무엇인가
비식별성(non-identifiability)은 서로 다른 모수 조합이 데이터에 대해 (거의) 동일한 우도를 주어, 데이터만으로는 둘을 구별할 수 없는 상태를 말한다. 모수 인데 모든 가능한 관측에서 우도가 같으면 그 모형은 식별 불가능하다(Lehmann & Casella 1998[13]의 표준 정의). 우도 표면이 어느 방향으로 평탄한 "능선(ridge)"을 가지면, MLE는 그 능선 위 어디로든 이동할 수 있다. 이는 표본이 적어 생기는 분산(추정값이 참값 주위로 흩어지되 중심은 맞는 경우)과 구별된다 — 구조적 비식별성은 표본을 무한히 늘려도 사라지지 않는다(Rothenberg 1971[12], 식별성의 고전적 정식화). 본 연구는 이 구분을, 표본 크기를 수백~수천으로 늘린 합성 실험(§4.4)에서 비식별이 해소되지 않음을 보여 실증한다.
3. 데이터와 방법 (Data & Methods)
3.1 Spock 캐스케이드
분석 대상 데이터는 Rizoiu et al.(2017)[2]이 사용한, New York Times의 트윗(레너드 니모이 사망 보도)에서 비롯된 "Spock" 리트윗 캐스케이드다. 여기서 **이벤트(event)**란 하나의 트윗 또는 리트윗 발생을 말하며, 각 이벤트는 발생 시각과 표식(=게시 사용자의 팔로워 수)을 갖는다. 전체 219개 이벤트가 약 241,072초($\approx$2.8일)에 걸쳐 발생하나, 대부분이 초반에 집중된다(그림 1 왼쪽, 로그 스케일).
**관측창(observation window)**이란 캐스케이드 전체 중 모형 적합에 사용하는 초기 구간을 말한다. Rizoiu et al.(2017)[2]이 Spock 예제에서 사용한 설정을 따라 관측창을 초로 두면, 그 안에 개 이벤트가 들어온다(그림 1 오른쪽). 관측창을 두는 이유는, 인기 예측 과제가 "초기 일부만 보고 최종 캐스케이드 크기를 예측"하는 설정이기 때문이다.
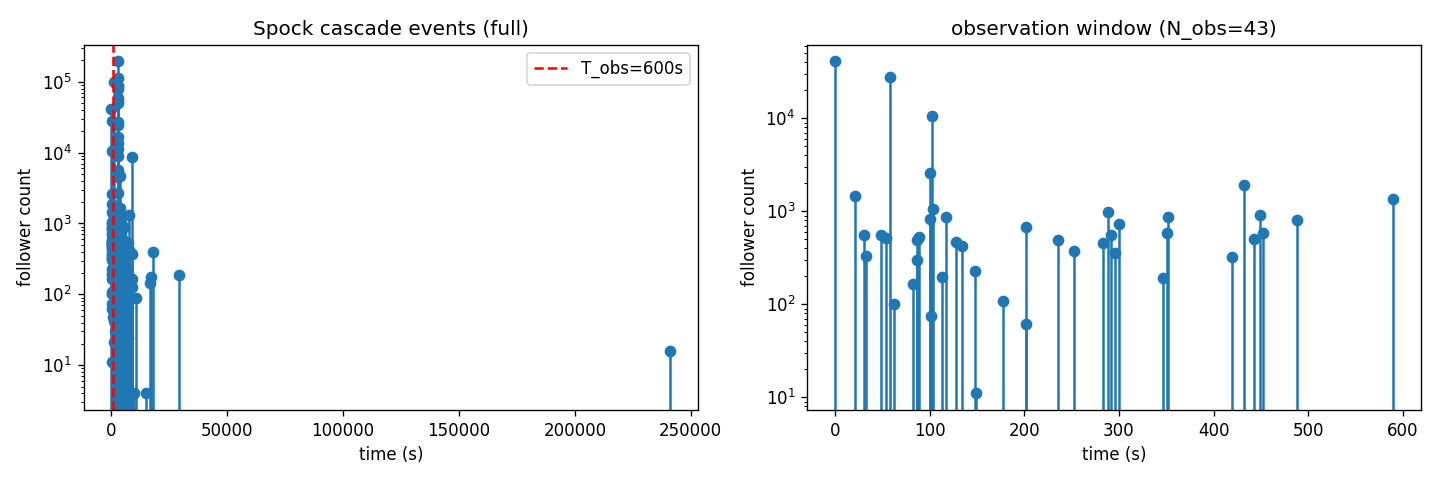
그림 1. Spock 캐스케이드의 전체 분포(좌)와 600초 관측창 내 43개 이벤트(우). 활동은 초기에 강하게 집중되며, 약 24만 초 지점의 고립 이벤트가 꼬리에 존재한다.
3.2 추정 절차
우도는 점과정의 표준 로그우도
를 사용한다(Daley & Vere-Jones 2003[11]의 표준 형식). 우변 둘째 항의 적분 를 **보상자(compensator)**라 하며, 이는 구간 에서 기대되는 누적 이벤트 수에 해당한다. 본 연구는 이 우도와 보상자를 멱법칙(표시·비표시)에 대해 Python으로 독립 구현했다. 그 이유는 Rizoiu et al.(2017)[2]이 공개한 R 코드(marked_hawkes.R)에는 다중 시작점 래퍼·시뮬레이터·커널의 분기율 닫힌형은 포함되나, 우리 분석 파이프라인이 Python 기반이어서 우도 본체를 재구현할 필요가 있었기 때문이다. 이 독립 우도의 정당성은 §4.3·§4.4의 합성 복원으로 직접 검증된다 — 지수 커널에서 참값을 정확히 복원하고, 비표시 멱법칙에서 식별 실패 패턴(개별 모수의 경계 고착, 의 광범위한 분산)을 재현한다.
최적화는 다중 시작점(multi-start) L-BFGS-B로 수행한다. L-BFGS-B는 박스 경계 제약 하에서 함수를 최소화하는 준-뉴턴(quasi-Newton) 최적화법이며, 여기서 최소화 대상은 음의 로그우도(negative log-likelihood, 이하 NLL )다. 비볼록한 우도면에서 단일 시작점은 국소 최소값에 갇힐 수 있으므로, 이를 완화하기 위해 모수별 로그균등 분포에서 시작점을 표집하고(합성 실험은 회당 10~20개), 유한차분 기울기로 각 시작점을 수렴시킨 뒤 NLL이 최소인 적합을 선택한다.
이 절차는 Rizoiu et al.(2017)[2]의 단일 시작점 IPOPT(Interior Point OPTimizer, 내부점 최적화기) 절차와 다르다. 두 절차의 차이가 결과에 영향을 주는지 검증하기 위해, 단일 시작점에서 비롯될 수 있는 국소 최소값 문제를 다중 시작점으로 통제한다. §4의 결과는 다중 시작점(회당 최대 20회)에서도 우도 능선이 해소되지 않음을 보여, 관측된 비식별이 최적화 방법의 차이가 아니라 커널 구조에서 비롯됨을 가리킨다.
닫힌형 분기율 제약. §4.1에서 n* = 0.92를 복원하는 "닫힌형(closed-form)" 제약은 Mishra, Rizoiu & Xie(2016, CIKM)의 닫힌형 분기율 관계식에서 유래한다. 표식이 멱법칙 영향 분포 P(m) = (a−1)m^(−a)에서 i.i.d.로 추출된다고 가정하면 분기율은 n* = κ·(a−1)/(a−β−1)·1/(θ·c^θ) (단 β < a−1, θ > 0)로 닫힌형으로 표현되며, 이를 MLE에 제약으로 부과한다(Mishra et al. 2016, Eq. 4; Rizoiu et al. 2017이 Eq. 1.37로 재수록하며 출처를 Mishra et al. 2016에 위임). 자유 적합은 이 제약 없이 κ를 독립 모수로 두어 능선 위를 미끄러진다. 이 관계식의 해석적 모수 소거 발상은 Filimonov & Sornette(2015)[1]의 배경 강도 μ 소거 기법과 계보를 공유하나, 소거 대상 모수가 다르므로(F-S는 μ, 본 연구는 커널 스케일 κ) 동일한 식은 아니다.
3.3 3단계 합성 복원 실험과 H-B 교차검증
코드 구현의 타당성과 모델 자체의 식별성은 별개의 문제다. 전자가 잘못이면 어떤 커널에서도 참값을 못 찾을 것이고, 후자가 문제면 구현이 옳아도 특정 커널에서만 실패할 것이다. 둘을 분리하기 위해, 참값을 아는 합성 데이터(우리가 모수를 지정해 시뮬레이션한 데이터)로 복원을 시도한다 — 추정이 그 지정값(ground truth)을 되찾는지 보는 것이다. 이는 추정기·구현의 타당성을 검증하는 표준 기법이며, 실데이터에는 참값이 없어 불가능한 검증을 가능케 한다.
- Phase 0 (지수 커널): 식별성이 양호한 지수 커널로 합성·복원. 구현이 옳다면 통과해야 한다. 세 설정 E1/E2/E3 (), 각 20회 반복.
- Phase 1 (비표시 멱법칙 커널): 동일 절차를 멱법칙 커널에 적용. 세 설정 R1/R2/R3 (), 각 20회 반복.
- Phase 2 (표시 멱법칙 커널): Spock 실데이터 적합과 동일한 표시(자유-) 모형으로 합성·복원하여 표시 비식별을 직접 측정한다. 세 설정(, 각 ), 각 10회 반복. 이 단계는 §3.2의 독립 구현 우도로 수행되므로, 결과는 그 전제 하에 해석한다(§4.6, §5.3).
복원 성공 여부의 **허용오차 기준(tolerance criterion)**은 다음으로 설정한다: 오차 , 개별 커널 모수 오차 , 배경 강도 오차 , 그리고 시간재척도(time-rescaling) 변환 후 잔차의 KS(Kolmogorov–Smirnov) 적합도 검정 통과. 이 기준값은 결과를 보기 전에 고정했다.
독립 교차검증으로 Hardiman–Bouchaud(H-B) 추정량을 사용한다. 이는 우도가 아니라 길이 인 시간창 안의 이벤트 개수(카운트, count)의 평균과 분산의 비(Fano 인자)에서 분기율을 추정하므로, MLE의 우도 능선 문제와 독립적인 경로다(Hardiman & Bouchaud 2014). 추정값이 창 폭 에 의존하는 것은 이 추정량의 알려진 성질이며(Hardiman & Bouchaud 2014), 를 60초부터 1800초까지 바꿔가며 각각 추정한다(이하 " 스윕").
마지막으로, 단일 사례를 넘어 추정 의존성을 검증하기 위해 ACTIVE 데이터셋(Rizoiu 그룹이 공개한 23,032개 리트윗 캐스케이드, 표식 = 팔로워 수)을 사용한다(§4.7). Spock과 동일 규모(이벤트 30~400개)의 캐스케이드 80개를 크기대별로 표집하고, Mishra et al.(2016)[3]의 추정 절차 — 닫힌형 분기율 식, 제약, 및 의 박스 경계 — 를 충실히 재현한다. Mishra et al.(2016)[3]은 이 제약 최적화를 ipopt(내부점 solver)로 수행했으나, 본 환경에서는 동일한 부등식 제약을 다룰 수 있는 SLSQP(순차 최소제곱 계획법) 제약 최적화로 대체했다 — 두 방법 모두 부등식 제약 하의 비선형 최적화를 푸는 solver이며, 알고리즘은 다르나 부과하는 제약은 동일하다. 또한 각 캐스케이드에서 표식(=팔로워 수)이 멱법칙 분포 를 따른다고 볼 때 그 지수 를 Hill 추정량으로 측정해, 닫힌형이 가정하는 과 실측값이 정합하는지 점검한다.
4. 결과 (Results)
4.1 실데이터 적합: 보고값의 복원은 추정 방법에 의존한다
자유 멱법칙 MLE는 보고된 모수를 복원하지 못한다. 모든 점검 항목(가 보고값의 10% 이내)이 어긋난다: 자유 적합은 커널 스케일 를 상한()까지 밀어붙이고 지수 로 큰 값을 택하는데, 이는 보고된 과 무관한 점이다. 이 점에서 함의되는 표시 분기율은 — 초임계로, 자유 적합이 보고값을 복원하지 못하고 능선을 따라 임계선을 넘는다. 대신 Mishra et al.(2016)[3]의 닫힌형 분기율 관계식(§3.2)을 제약으로 부과하면 가 복원되어 문헌과 일치한다. 즉 자유 적합은 본질적으로 같은 우도에서 보고값과 완전히 다른 모수 벡터(초임계)에 안착하며, 보고된 아임계 식별은 제약이 부여한 것이다(§4.2).
| 추정 경로 | |||
|---|---|---|---|
| Rizoiu 보고값 | 1.00 | 1.33 | 0.92 |
| 우리 MLE — Mishra(2016) 닫힌형 제약 | 1.00 | 1.35 | 0.92 |
| 우리 MLE — 자유 적합 (제약 없음) | (상한) | 4.47 | 1.19 |
제약 적합은 보고된 을 복원하는 반면, 자유 적합은 완전히 다른 모수 벡터(가 상한에 고정, 가 세 배 이상 큼)에 안착하면서도 제약 적합과 사실상 구별 불가능한 우도를 갖는다. 두 적합의 분기율은 한쪽은 초임계(), 다른 쪽은 아임계()로 갈리며 — 자유 적합은 커널을 식별한 것이 아니라 평탄한 능선 위 임의의 한 점을 택한 것이다(§4.2).
적합 자체의 강도(그림 2)와 잔차의 시간재척도 Q–Q(그림 3, KS p = 0.305)는 양호하다. 즉 모형은 데이터를 잘 설명하지만, 모수가 유일하게 정해지지 않는다 — 적합도와 비식별의 공존이야말로 비식별의 교과서적 증상이다.
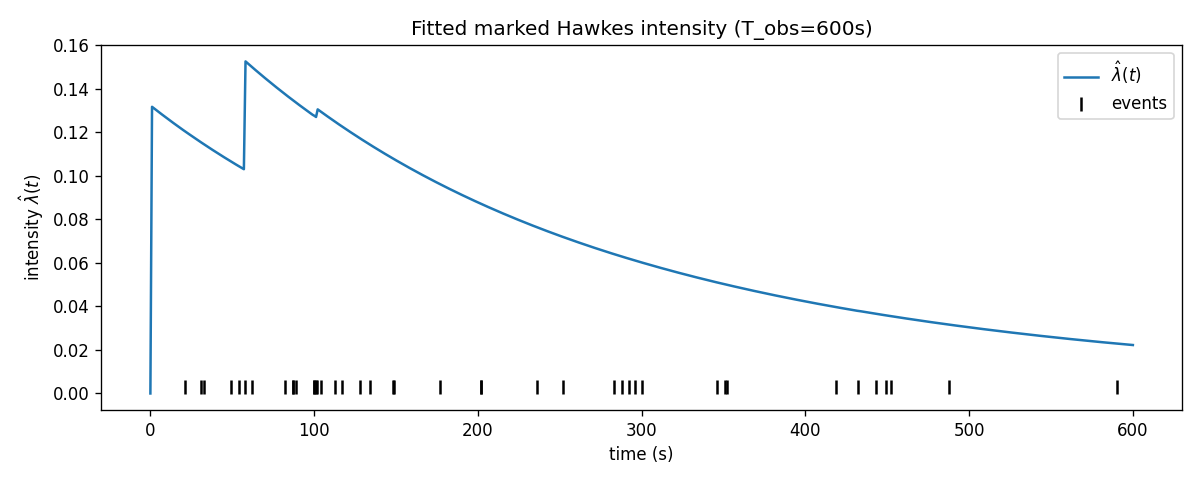
그림 2. 적합된 표시 Hawkes 강도. 강도 곡선이 이벤트 군집을 따라가며, 적합 자체는 데이터를 잘 기술한다.
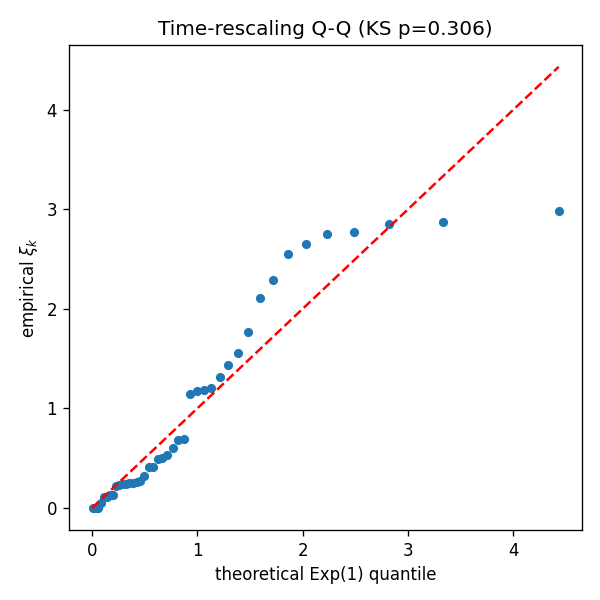
그림 3. 시간재척도 잔차의 Q–Q 플롯. 점들이 대체로 대각선을 따라 KS 검정에서 기각되지 않으나(), 상단 꼬리(이론 분위수 2 이상)에서 점들이 대각선 위로 체계적으로 이탈해 큰 잔차가 과소예측됨을 보인다. 적합도가 완벽해서가 아니라, 능선 위 서로 다른 모수들이 모두 이와 유사한(불완전한) 적합도를 준다는 점이 요지다.
4.2 능선의 직접 관측
상위 5개 적합은 이 비식별을 실데이터에서 직접 드러낸다(그림 4). 커널 스케일 는 약 에서 까지 여섯 자릿수에 걸쳐 분포하는데, 다섯 적합의 NLL은 약 밖에 차이 나지 않는다. 평면에서 같은 적합들이 하나의 능선(그림 4 우의 회색 점선 방향)을 그린다. 자유 MLE는 우도를 사실상 일정하게 유지한 채 이 능선을 따라 이동한다 — 는 데이터에 의해 식별되지 않는다.
결정적으로, 이 다섯 적합이 함의하는 표시 분기율은 모두 초임계(–)이며, 어느 것도 보고값 를 복원하지 않는다. 즉 데이터는 우도상 이 적합들을 사실상 구별하지 못하는데(가 여섯 자릿수만큼 어긋나도 NLL은 거의 동일), 그것들이 가리키는 커널 모수는 전혀 다르고 분기율은 일관되게 임계선 위에 있다. 커널 모수는 데이터에 의해 식별되지 않으며, 자유 적합은 능선 위 한 점을 임의로 택할 뿐이다. §4.6의 표시 합성 실험은 참값을 아는 환경에서 동일한 비식별이 추정을 발산시킴을 보여, 이 능선 병리가 단순한 수치 우연이 아님을 확인한다.
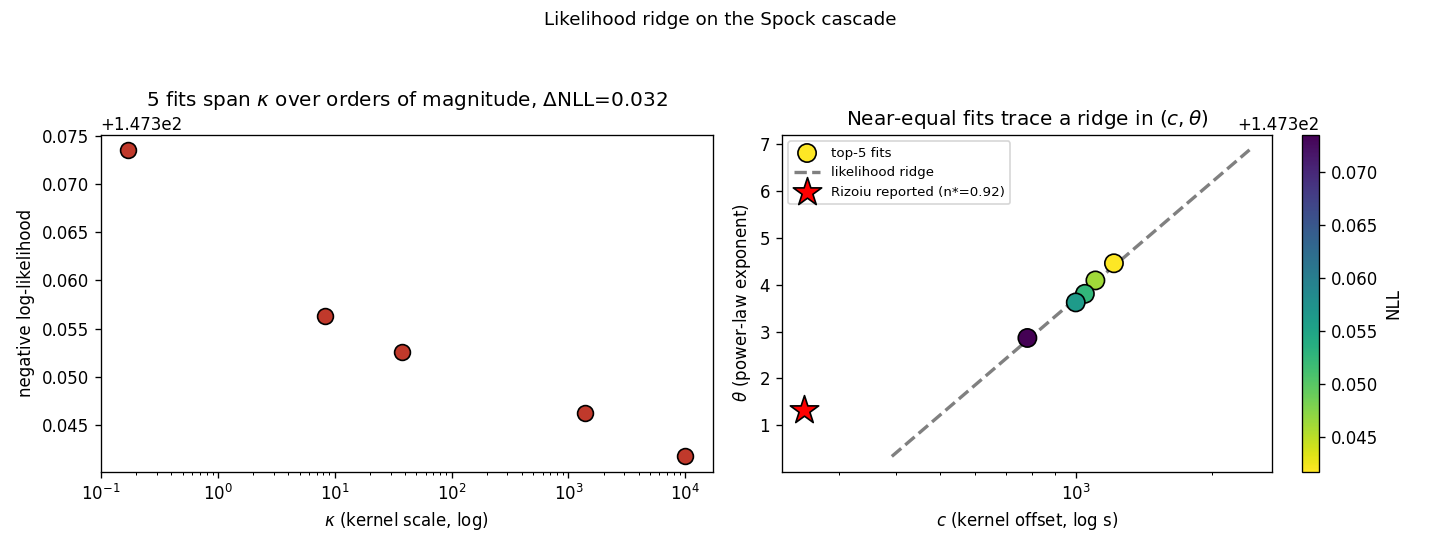
그림 4. Spock 실데이터에서 관측된 비식별 능선. (좌) 다섯 적합의 는 약 에 걸치나 NLL은 사실상 동일하다(). (우) 동일 적합들이 평면에서 능선을 형성하며(회색 점선=능선 방향), Rizoiu 보고점(★, )은 능선 위에 놓인다.
4.3 구현 타당성 검증 — 지수 커널에서의 모수 복원 (Phase 0)
같은 구현으로 지수 커널 합성 데이터를 복원하면, 임계에 가까운 두 설정에서 검증 기준을 만족한다(그림 5). 세 설정 모두 은 약 1200~3800 규모다. ( 오차 허용 기준은 §3.3에서 고정한 다.)
| 설정 | 참 | 범위 | 평균 | 중앙값 | 표준편차 | 중앙값 오차 | 기준() |
|---|---|---|---|---|---|---|---|
| E1 | 0.3 | 1696–1917 | 0.301 | 0.299 | 0.048 | 0.3% | 분산이 기준 초과* |
| E2 | 0.7 | 1583–2046 | 0.681 | 0.677 | 0.033 | 3.3% | 만족 |
| E3 | 0.9 | 1247–3806 | 0.890 | 0.888 | 0.032 | 1.3% | 만족 |
참 은 합성 데이터 생성 시 우리가 지정한 값(ground truth)이다. 표의 평균·중앙값·표준편차는 각 설정 20회 반복의 분포에서 계산했다. * E1의 중앙값 오차는 0.3%로 사실상 무편향이나, 개별 추정값의 표준편차(0.048)가 참값 대비 16%로 기준을 넘는다 — 즉 편향이 아니라 분산의 문제이며, 관측 길이 를 늘리면 해소될 성질이다. KS 적합도 검정은 세 설정 모두 20/20 통과한다.
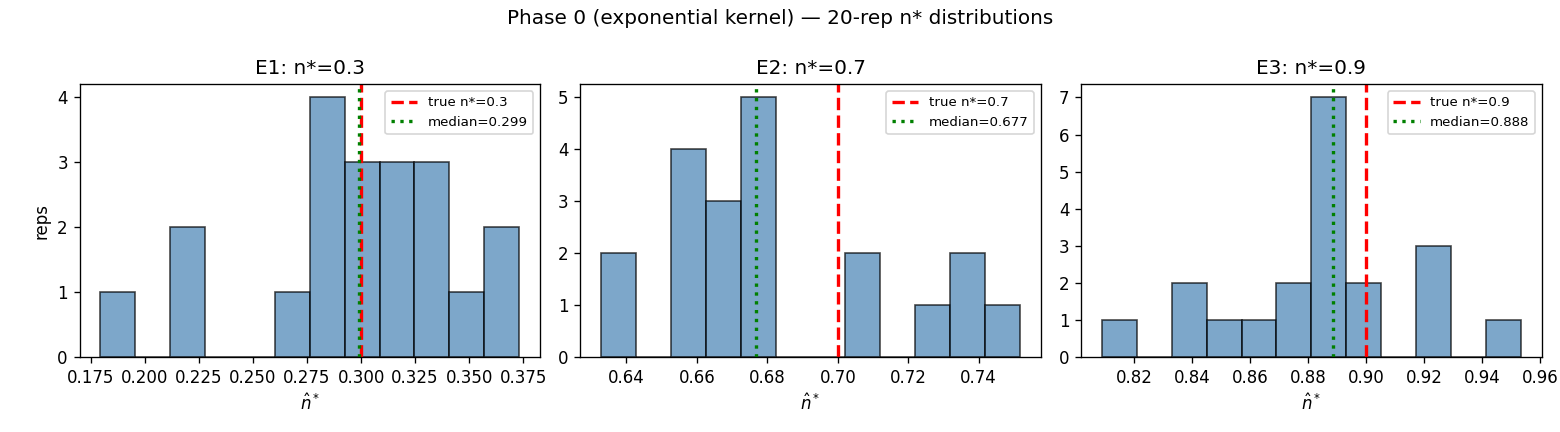
그림 5. Phase 0 지수 커널의 분포(각 설정 20회). E2·E3는 참값(빨강 선) 주위로 좁게 모여( 표준편차 0.033·0.032) 기준을 만족하고, E1은 중앙값(0.299)은 참값 0.3에 일치하나 분산(표준편차 0.048)이 기준을 넘는다. 이로써 우도·최적화·진단 구현이 지수 커널에서 참값을 복원함을 확인한다(이 검증은 지수 커널에 대한 것이며, 멱법칙으로의 일반화는 §4.4에서 별도로 다룬다).
4.4 멱법칙 커널의 비식별 — 표본을 늘려도 해소되지 않는다 (Phase 1)
동일 구현을 멱법칙 커널에 적용하면 세 설정 모두 복원에 실패한다(그림 6). 결정적으로, 은 414~1926으로 충분히 크다 — 소표본 문제가 아니다. 표의 배수는 개별 모수 의 중앙값 추정값이 참값의 몇 배인지를 나타낸다.
| 설정 | 참 | 범위 | 중앙값 | 최대 | 표준편차 | 배수 | 상한 고착 | KS 통과 |
|---|---|---|---|---|---|---|---|---|
| R1 | 0.3 | 1687–1926 | 0.281 | 0.38 | 0.08 | ~700배 | 12/20 | 20/20 |
| R2 | 0.7 | 1406–1724 | 0.510 | 74.3 | 21.2 | ~34배 | 10/20 | 20/20 |
| R3 | 0.9 | 414–648 | 96.6 | 9503 | 3463 | (상한 고착) | 7/20 | 20/20 |
세 가지가 표와 그림에서 함께 확인된다.
- 개별 모수의 붕괴. R1에서 중앙값(0.281)은 그나마 참값에 가깝지만, 는 참값의 약 700배이고 20회 중 12회가 상한()에 고착된다(표의 " 배수"·" 상한 고착" 열). 은 모수들의 특정 결합이라 우연히 보존될 수 있어도, 각각은 식별되지 않는다.
- 임계 접근 시 폭주. R1()→R3()로 갈수록 악화가 가속된다(표의 중앙값·표준편차 열). R3의 중앙값은 96.6, 표준편차 3463, 최대 9503으로 참값 0.9와 무관하게 발산한다. 같은 규모에서 지수 커널(표 E1
E3)의 표준편차가 0.030.05에 머무는 것과 대비하면, 분산의 폭발이 표본이 아니라 커널에서 온다. - 적합도와 비식별의 공존. 멱법칙 합성에서 시간재척도 KS 적합도는 세 설정 모두 20/20 통과한다(표의 KS 열, 최소 ). 추정된 모형이 데이터의 시간 구조를 통계적으로 흠 없이 재현하는데도 모수는 참값과 무관하게 흩어진다 — 적합은 양호하나 모수는 정해지지 않는, 비식별의 정의 그대로다. (적합 우도가 참값 우도보다 낮다는 사실 자체는 유한표본 MLE에서 식별 여부와 무관하게 성립하므로 — 식별이 양호한 Phase 0에서도 동일하게 관측된다 — 비식별의 증거로 사용하지 않는다.)
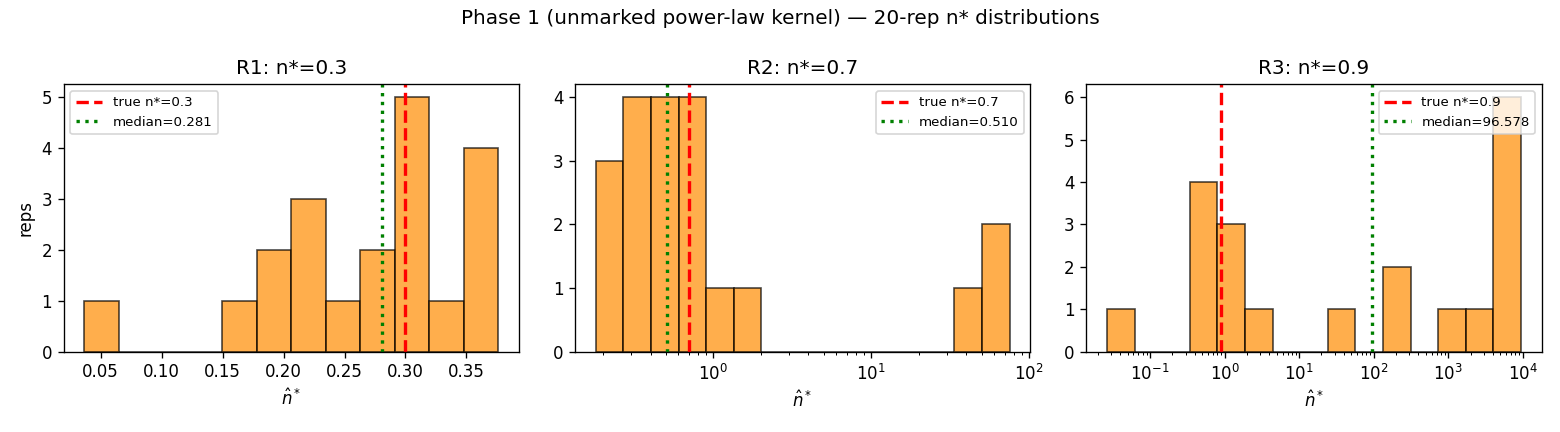
그림 6. Phase 1 멱법칙 커널의 분포(각 설정 20회). R1은 참값 부근에 분산되나( 중앙값 0.281), R2는 1을 넘는 꼬리가 생기고( 최대 74.3), R3은 추정값이 수천 대로 폭주한다( 중앙값 96.6, 최대 9503). 같은 규모의 그림 5(지수, 표준편차 0.03~0.05)와 대비하면, 비식별의 원인이 표본이 아니라 커널임이 드러난다.
4.5 우도 독립 교차검증 — H-B 추정량 (Spock)
우도와 독립적인 경로인 H-B 추정량으로 Spock을 추정하면, 관측된 모든 창 폭에서 분기율이 1 미만으로 나온다(그림 7). 여기서 은 §3.3에서 정의한 대로 길이 시간창 내 이벤트 개수(카운트)의 평균·분산에서 도출한 추정값이다.
| (s) | Fano 인자 | |
|---|---|---|
| 60 | 0.510 | 4.16 |
| 120 | 0.636 | 7.54 |
| 300 | 0.750 | 15.95 |
| 600 | 0.806 | 26.62 |
| 1800 | 0.876 | 64.90 |
관측된 다섯 창 폭에서 은 모두 1 미만이다 — 우도면과 독립적인 경로가 아임계를 가리킨다. 그 값들(~)은 제약 MLE·Rizoiu 보고값 와 같은 영역에 있다. 반면 비제약 자유 적합은 능선을 따라 초임계()로 이탈한다. 제약·H-B 경로는 아임계로 수렴하지만 자유 적합은 그렇지 않다는 이 불일치 자체가 — 데이터가 분기율을 한 점으로 고정하지 못한다는 — 비식별의 징표다(§4.2).
Spock 데이터에 H-B를 적용할 때의 한계. 이 에 따라 단조 증가하는 것(0.51→0.88)은 추정량과 데이터 사이의 가정 불일치를 반영한다. Hardiman & Bouchaud(2014)[4]의 모멘트 추정량은 정상(stationary, 통계적 성질이 시간에 불변인) 과정을 전제하나, Spock은 외생 트리거(NYT 트윗 게시)에서 시작해 급격히 소멸하는 약 10분 규모의 과도기(transient) 캐스케이드로 정상성을 만족하지 않는다. 따라서 어느 단일 값도 "참 분기율"로 특권화할 수 없다. 본 추정의 목적은 정밀한 점추정이 아니라, 우도 능선과 독립적인 경로에서 아임계 여부를 교차 확인하는 것이다.
다만 이 교차검증의 사정거리를 정직하게 한정한다. "관측된 구간에서 모두 1 미만"이라는 것은 정성적 사실이며, 극한에서 이 어떤 값으로 수렴하는지에 대한 점근적 보장은 본 연구가 제시하지 않는다(과도기 데이터에서 그 극한 자체가 잘 정의되지 않는다). 따라서 우리는 이 결과를 "아임계의 결정적 증명"이 아니라 "능선과 독립적인 경로에서 얻은 정성적 정합 증거"로만 사용한다.
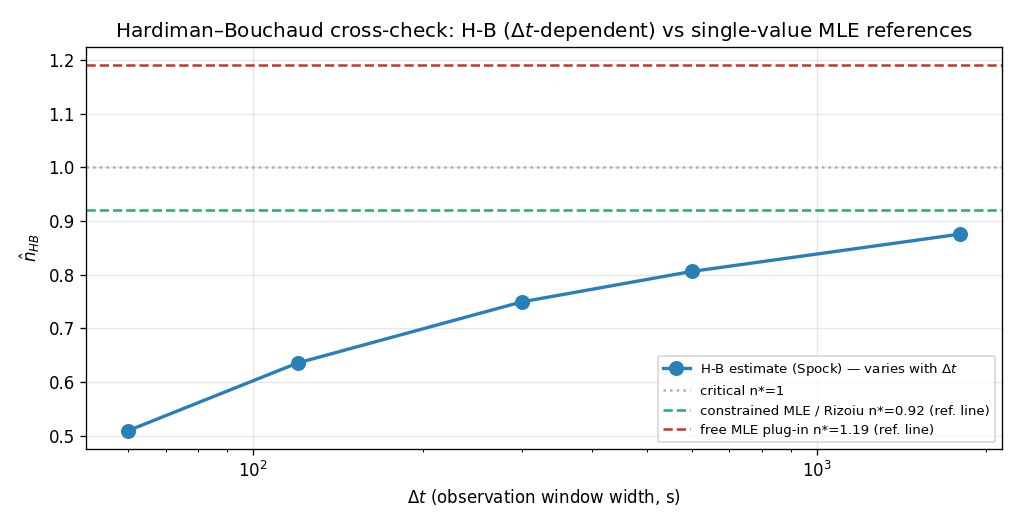
_그림 7. H-B 추정량의 스윕(가로축=창 폭, 세로축=). 다섯 창 폭의 추정값(곡선)이 모두 임계선() 아래에 있다. 참고로 표시한 기준선(자유 MLE plug-in, 제약 MLE/Rizoiu 0.92)은 단일 추정값이므로 에 의존하지 않는 수평선으로 그렸다 — H-B 곡선과의 비교를 위한 참조선이며 의 함수가 아니다.*
4.6 표시 멱법칙 커널의 비식별과 그 메커니즘 (Phase 2)
§4.4의 비식별은 비표시 커널에서 측정했으나, Spock 실데이터 적합(§4.1~4.2)은 표식이 있는 자유- 표시 모형을 사용한다(이는 §3.1·§3.2에서 명시한 분석 설정이다). 두 경우를 잇기 위해, 실데이터 적합과 동일한 표시 모형으로 참값을 아는 합성 데이터를 세 설정(P1: , P2: , P3: ; 각 )에서 복원한다 — §3.3의 합성 복원 방법(우리가 모수를 지정해 시뮬레이션한 뒤 추정이 그 값을 되찾는지 검사)을 표시 모형에 적용한 것이다. 이 단계는 §3.2의 독립 구현 우도로 수행되며, 그 우도의 정당성은 지수·비표시 복원으로 교차검증되었다(§4.3, §4.4).
| 설정 | 참 | 중앙값 | 범위 | 참 | 중앙값 |
|---|---|---|---|---|---|
| P1 | 0.3 | 0.16 | ~ | 1.3 | 1.14 |
| P2 | 0.7 | 2.69 | 0.27 ~ | 1.3 | 1.65 |
| P3 | 0.9 | 18.4 | ~ | 1.3 | 1.63 |
표시 모형은 Phase 1(비표시)과 같은 임계 악화 패턴을 보인다 — 중앙값이 0.16→2.69→18.4로 임계 접근 시 폭주하고, 범위는 모든 설정에서 여러 자릿수에 걸친다. 그 메커니즘도 표에서 드러난다: 중앙값이 1.14→1.65→1.63으로, 참값 1.3 대비 임계 구간(P2·P3)에서 과대추정된다. §2.1에서 본 대로 분기율은 를 통해 에 초지수적으로 의존하므로, 임계 영역에서 커지는 상향 오차가 의 발산으로 증폭된다. 주목할 점은 아임계 P1에서도 중앙값(1.14)은 참값 근처지만 은 여전히 으로 발산한다는 것 — 즉 능선 자체가 와 무관하게 분기율을 비식별로 만들고, 여기에 임계 영역의 과대추정이 추가로 얹힌다.
이는 §4.2의 실데이터 능선이 시사만 할 수 있었던 것을 참값을 아는 환경에서 명시적으로 드러낸 것이다: Spock에서 본 의 여섯 자릿수 비식별은, 참값을 알 때 자체를 발산시키는 바로 그 평탄 능선 병리와 동일하다. 실데이터에서는 커널이 비식별이어도 함의 분기율이 초임계 영역에 머물렀지만, 참값을 아는 여기서는 동일한 비식별이 추정을 광범위하게 발산시켜 직접 표면화된다.
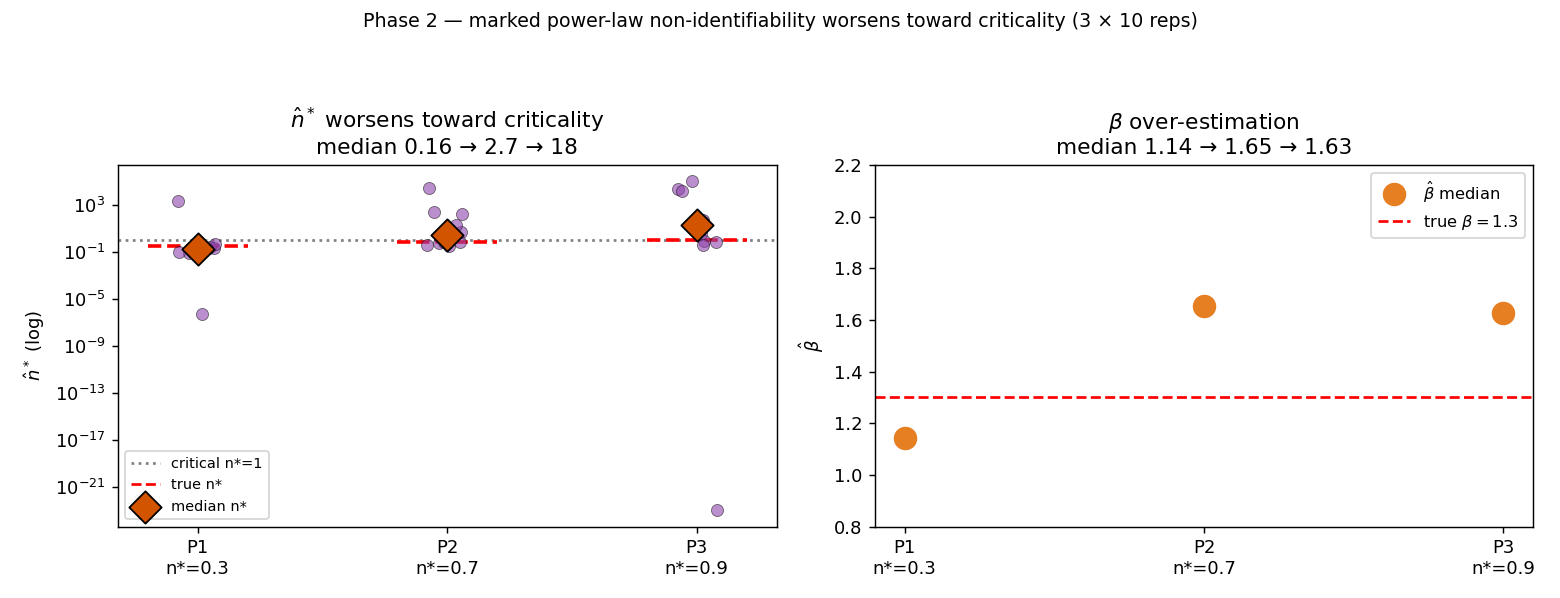
그림 8. 표시 멱법칙 Hawkes 합성 복원(참 , , 각 10회). (좌) (보라 점, 주황 다이아=중앙값)이 임계로 갈수록 폭주하며 중앙값이 0.16→2.69→18.4로 상승한다. (우) 중앙값(1.14→1.65→1.63)이 참값 1.3 대비 임계 구간에서 과대추정된다. 본 단계는 §3.2의 독립 구현 우도로 수행되었다.
4.7 단일 사례를 넘어 — ACTIVE 캐스케이드에서의 검증
지금까지의 결과는 Spock 단일 캐스케이드에 근거한다. 추정 의존성이 Spock의 특수성이 아닌지 확인하기 위해, Rizoiu 그룹의 ACTIVE 데이터셋(23,032개 리트윗 캐스케이드, 표식 m=팔로워 수)에서 Spock과 동일 규모(이벤트 30~400개)의 캐스케이드 80개를 크기대별로 표집해, Mishra et al.(2016)의 추정 절차를 충실히 재현했다 — Mishra et al.(2016)[3]의 닫힌형 분기율 식, n* < 1 부등식 제약, K ≤ 1·β ≤ α−1 박스 경계, 그리고 Mishra et al.(2016)의 ipopt을 등가의 SLSQP 제약 최적화로 대체했다.
세 가지가 확인된다(그림 9).
- 제약은 작동한다. Mishra et al.(2016)의 n* < 1 제약을 충실히 부과하면 80개 중 91%가 아임계로 추정된다. 제약 추정은 대부분의 캐스케이드를 1 미만으로 묶는다 — 그 아임계가 데이터가 부여한 것인지 제약이 부여한 것인지가 §4.2가 제기한 질문이며, 다음 두 항이 이를 다룬다.
- 그러나 다수가 제약 경계에 부착된다. 아임계로 묶인 것 중 약 46%가 n ≈ 0.92, 즉 제약 상한(1) 직전에 정확히 멈춘다*(그림 9 좌). 이는 비제약 우도의 최대점이 임계 영역 밖에 있어, 보고되는 아임계 값이 데이터가 아니라 제약 경계에 의해 결정됨을 시사한다 — Spock에서 관측된 "0.92는 데이터가 아니라 제약이 만든 값"이라는 현상이 단일 사례가 아님을 보인다.
- 닫힌형은 표식 분포 가정에 이중으로 의존한다. Mishra et al.(2016) 닫힌형 n* = K·(α−1)/(α−1−β)·1/(θc^θ)는 표식 m이 Pareto(α=2.016)를 따른다고 가정하나, ACTIVE 캐스케이드의 실측 α(Hill 추정)는 중앙값 1.18로 가정과 크게 어긋난다(99%가 2.016 미만, 그림 9 중). 캐스케이드별 실측 α를 식에 대입하면 적합된 β가 α−1을 넘어 표본의 55%에서 닫힌형 공식이 무효가 된다(Mishra et al.(2016)의 R 코드도 이 영역에서 Inf를 반환하며 "공식이 성립하지 않는다"고 경고; 그림 9 우). 따라서 §2.2 이후의 모든 닫힌형 분기율 값은 α=2.016 가정에 조건부다.
종합하면, ACTIVE 검증은 명확한 결론을 준다: Mishra–Rizoiu 절차가 산출하는 아임계 분기율은 두 가정 — (i) n < 1 제약, (ii) 표식 분포 α — 이 함께 부과하는 산물이며, 데이터만으로 분기율이 식별된다고 보기 어렵다.*(i)은 91%를 1 미만으로 묶되 거의 절반을 경계에 부착시키고, (ii)는 실측값과 어긋나 55%의 표본에서 공식 자체를 무효화한다. 요점은 모든 캐스케이드가 초임계라는 것이 아니다 — Spock의 비제약 자유 적합은 초임계로 이탈하지만, ACTIVE 표본의 더 흔한 양상은 제약이 다수를 아임계로 끌어내리되 그 절반 가까이를 경계에 붙이는 것이다. 공통점은 커널이 비식별인 상태에서 보고되는 분기율이 데이터가 아니라 추정 가정에 의해 결정된다는 점이다.
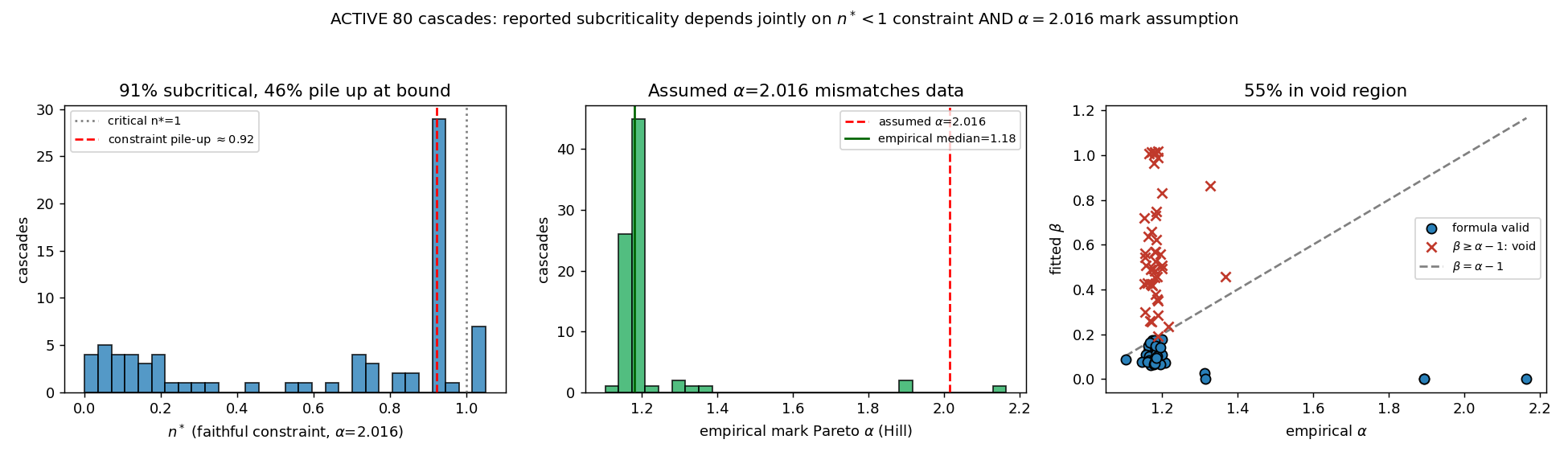
그림 9. ACTIVE 캐스케이드 80개(Spock 동일 600초 창)의 Mishra et al.(2016) 절차 충실 재현. (좌) 충실 제약 하 n̂* 분포 — 91%가 1 미만이나 46%가 상한 ≈0.92에 부착. (중) 캐스케이드별 실측 표식 Pareto α 분포 — 중앙값 1.18로 가정값 2.016과 어긋남. (우) 적합 β 대 실측 α−1 경계 — 55%가 β ≥ α−1의 공식 무효 영역(붉은 ×)에 위치.
5. 논의 (Discussion)
5.1 추정 방법 의존성의 해부
자유 MLE가 Rizoiu et al.(2017)[2]의 보고 적합을 복원하지 않는 현상은 세 가지 관찰로 분해된다. 첫째, 자유 멱법칙 MLE는 우도 능선 위를 이동해 보고값과 전혀 무관한 모수 벡터(가 상한, )에, 사실상 같은 우도에서 안착한다 — 커널은 식별되지 않는다. 둘째, Mishra et al.(2016)[3]의 닫힌형 분기율 제약을 부과하면 보고값 가 복원된다 — 보고된 식별성은 데이터가 아니라 추정 제약이 부여한 것이다. 셋째, 비제약 자유 적합은 초임계()로 이탈하는 반면, 제약 적합과 우도에 무관한 H-B 추정량은 아임계()로 수렴한다. 즉 분기율의 임계성 결론 자체가 추정 경로에 따라 갈린다. "커널 모수를 데이터와 우도만으로 유일하게 추정할 수 있는가"라는 통계적 질문의 답은 부정이다 — 모수는 능선 위에서 비유일하며, 보고된 아임계 값은 제약이 선택한 한 점이다. §4.6은 참값을 아는 합성에서 동일한 비식별이 을 발산시킴을 보여, 자유 적합의 초임계 이탈이 우연이 아니라 능선 병리의 발현임을 확인한다.
비식별성은 도메인이 아니라 커널의 성질이다. 여기서 예상되는 반론은, 금융 고빈도 데이터에서 얻은 진단을 소셜 캐스케이드에 적용하는 것이 본질적으로 다른 두 대상을 무리하게 연결하는 것 아니냐는 것이다. 이 반론에 대한 답은 본 연구의 주 증거가 금융 결과의 이식이 아니라는 데 있다. 우도 능선과 그로 인한 비식별성은 멱법칙 커널 의 함수 형태에서 대수적으로 따라 나오는 성질이며, 데이터가 금융이냐 소셜이냐와 무관하다. 본 연구가 이를 입증하는 핵심 증거(§4.4, §4.6)는 어느 도메인의 실데이터도 아닌, 참값을 아는 합성 데이터에서의 측정이다 — 거기에는 커널과 우도만 있을 뿐 도메인이 없다. Filimonov & Sornette(2015)[1]와 Hardiman & Bouchaud(2014)[4]는 동일한 커널의 동일한 병리가 금융 도메인에서도 독립적으로 관측되었다는 수렴 증거로 인용되는 것이지, 그들의 진단을 소셜 데이터에 전이시키는 것이 아니다. 비유하자면, 본 연구는 "특정 차체에서 출력이 낮다"를 주장하는 것이 아니라 "이 엔진(멱법칙 커널)을 시험대(합성 데이터)에 올리면 차체와 무관하게 특정 영역에서 불안정하다"를 보이며, 그 불안정성이 엔진의 설계 특성임을 가리킨다. 금융 문헌은 "같은 엔진을 다른 차체에 얹었을 때도 같은 불안정이 보고되었다"는 선례에 해당한다.
소셜 도메인에서의 함의. 이 관찰은 금융 Hawkes 문헌이 보고해 온 분기율의 겉보기 임계성·우도면 병리가 소셜미디어 모델링에서도 나타남을 보이는 구체적 증거다. 어느 편향 기전이 작동하는지도 도메인에 따라 갈린다 — Filimonov & Sornette(2015)[1]가 분해한 네 기전 중, 레짐 변화에 의한 허위 임계성은 약 10분의 단일 관측창인 Spock에는 해당하기 어려운 반면, 커널 정규화 형태와 절단(censoring), 그리고 복잡한 우도면(§4.2, §5.2)은 직접 작동한다. 소셜미디어 계열이 제약을 부과해 온 관행은 예측 안정성 측면에서 합리적이나, 그 제약이 없으면 커널이 비식별이고 보고값이 평탄 능선 위 임의의 한 점이라는 사실을 가린다. 본 논문은 그 사실을 Spock에서 드러내고, ACTIVE 23,032개 캐스케이드 중 표집한 80개에서 그것이 단일 사례가 아님을 보인다(§4.7). ACTIVE 검증은 두 가지를 한정한다. 첫째, Spock의 비제약 자유 적합은 초임계로 이탈하지만, 이것이 ACTIVE 전반의 보편 패턴은 아니다 — 더 흔한 양상은 제약이 캐스케이드를 아임계로 묶되 그 거의 절반을 제약 경계()에 부착시키는 것이다. 둘째, 이 추정 의존성은 제약 하나가 아니라 제약과 표식 분포 가정()의 결합이며, 실측 가 가정값과 어긋나 닫힌형 자체가 표집 표본의 55%에서 무효가 된다. 따라서 본 논문의 일반화 주장은 "보고되는 분기율이 데이터 단독이 아니라 추정 가정들에 의해 결정된다"는 것이지, "모든 캐스케이드가 초임계다"가 아니다.
5.2 구현 타당성과 모델 식별성의 분리
이 분리가 본 연구의 방법론적 핵심이다. 지수 커널(Phase 0)에서 우리 구현이 참값()을 복원하므로 우도·최적화·진단 구현은 타당하다. 같은 구현이 멱법칙(Phase 1)에서 복원에 실패하므로, 비식별의 원인은 구현이 아니라 커널 구조에 있다. 그리고 Phase 1의 이 수백~수천임에도 실패가 지속되고 임계 접근 시 악화되므로, 이 비식별은 표본 부족이 아니라 구조적이다. §3.2에서 통제한 단일 시작점 IPOPT 대 다중 시작점의 차이 가설 — 즉 재현 불일치가 최적화기의 차이에서 비롯될 가능성 — 은, 다중 시작점 20회로도 우도 능선이 해소되지 않는다는 점에서 원인에서 배제된다.
5.3 적용 범위 — 무엇이 검증되었고 무엇이 아닌가
결론의 사정거리를 분명히 한다. 직접 검증된 것은 두 가지다. (1) 비표시 멱법칙 커널 의 구조적 비식별 — , 영역에서 확인했으며 near-critical에서 악화된다(§4.4). (2) 표시 멱법칙 커널 의 비식별 — 실데이터 적합과 동일한 표시 자유- 모형으로 합성 복원하여, 의 체계적 과대추정을 통해 이 발산함을 측정했다(§4.6). 표시 경우는 Phase 2를 실행하기 전에는 비표시 결과로부터의 예상에 불과했으나, §4.6의 합성 복원으로 측정된 사실이 되었다.
다만 두 가지 한계를 명시한다. 첫째, §4.6의 표시 복원은 Rizoiu et al.(2017)[2] 공개 코드에 없던 독립 구현 우도로 수행되었다(§3.2). 이 우도는 지수·비표시 복원으로 교차검증되었으나, 표시 복원 결과를 Rizoiu et al.(2017)·Mishra et al.(2016)의 우도로 재현한 것은 아니다. 둘째, §4.6은 세 설정() 각 10회로, 비표시 Phase 1의 20회보다 반복 수가 적고 합성 길이도 짧다(표시 우도의 계산량이 에 비례하는 제약). 그럼에도 임계 악화 패턴( 중앙값 0.16→2.69→18.4)과 그 메커니즘( 증폭)이 세 곳 — 비표시 Phase 1(표의 · 열), 표시 합성 §4.6(표의 열), 실데이터 §4.2(fit_top5의 분산) — 에서 일관되게 관측되므로, 우리는 결론의 방향에 대해 이 세 증거의 수렴을 근거로 제시한다.
비식별이 추정 정밀도를 신뢰 불가능하게 만드는 구체적 영역은 near-critical()이며, 아임계 깊숙한 영역(예: )에서는 자체는 부분적으로 식별될 수 있으나 개별 또는 는 여전히 식별되지 않는다.
§4.7의 ACTIVE 검증에도 두 한계가 있다. 첫째, Mishra et al.(2016)[3]의 ipopt 내부점 solver를 등가의 SLSQP 제약 최적화로 대체했다 — 동일한 부등식 제약을 부과하나 수치 알고리즘이 다르며, 80개 중 6%는 SLSQP가 제약을 완전히 지키지 못했다(수치 실패). 둘째, ACTIVE 표식 분포의 실측 (중앙값 1.18)가 닫힌형의 가정값 과 어긋나므로, " 경계 부착 46%"는 가정 하의 결과다 — 실측값으로 바꾸면 표본의 55%에서 공식이 무효가 되어 단일 수치로 요약할 수 없다. 이 가정 의존성 자체가 §4.7의 핵심 발견이므로, 우리는 이를 한계가 아니라 결과로 보고하되 어떤 특정 분기율 분포도 가정 독립적으로 주장하지 않는다.
5.4 실무적 함의
멱법칙 커널로 소셜 캐스케이드의 분기율을 자유 추정하려는 후속 작업은 다음 중 하나를 택해야 한다: (i) 식별성이 보장된 지수 커널 사용, (ii) 멱법칙을 유지하되 (n*, c, θ) 등 의미 있는 재모수화와 닫힌형 제약 부과, (iii) 우도와 독립적인 H-B류 추정량으로 교차검증. 멱법칙 + 자유 (α, δ, η) MLE 조합은 near-critical에서 신뢰할 수 없다.
6. 결론 (Conclusion)
Spock 캐스케이드에 대한 멱법칙 Hawkes 적합은 자유 MLE 기준으로 보고된 모수를 복원하지 못한다: 자유 적합은 보고값과 무관한 모수 벡터에 사실상 같은 우도에서 안착한다. 그러나 이는 구현의 결함이 아니라 모델의 구조적 비식별성에서 비롯되며, 참값을 아는 합성 데이터로 구현과 모델을 분리함으로써 확인된다(§4.3, §4.4). 멱법칙 커널은 비표시 와 표시 양쪽에서 수백~수천 이벤트 규모에서도 식별되지 않고 임계 접근 시 폭주하며, 표시의 경우 그 메커니즘은 의 체계적 과대추정을 통한 표식 모멘트 의 증폭이다(§4.6). 보고된 는 Mishra et al.(2016)[3]의 닫힌형 제약 하에서만 복원되는, 데이터가 아니라 추정 절차가 부여한 식별이다(§4.1). 한편 우도와 독립적인 H-B 추정량은 관측된 모든 창 폭에서 1 미만을 주어, "Spock이 아임계"라는 결론을 능선과 다른 경로에서 정성적으로 지지한다(§4.5) — 다만 §4.5에서 한정했듯 이는 결정적 증명이 아니라 정합 증거다. ACTIVE에서 표집한 80개 캐스케이드의 검증은 이 추정 의존성이 단일 사례가 아님을, 그러나 단순한 초임계 발산이 아니라 제약과 표식 분포 가정의 결합 의존의 형태임을 보인다(§4.7). 요컨대 본 사례는 재현의 불일치가 어떻게 모델 식별성에 대한 측정 가능한 발견으로 전환되는지를 보여주며, 그 발견의 핵심은 보고되는 분기율이 데이터 단독이 아니라 추정 가정들에 의해 결정된다는 점이다.
7. 데이터·코드 가용성 (Data & Code Availability)
- 실데이터 적합:
a1_pass_result.json - 최종 판정:
a1_final_judgment.json - Phase 0 (지수):
phase0_E1_results.json,phase0_E2_results.json,phase0_E3_results.json - Phase 1 (비표시 멱법칙):
phase1_R1_results.json,phase1_R2_results.json,phase1_R3_results.json - Phase 2 (표시 멱법칙):
phase2_marked.json(본 검증에서 신규 생성) - ACTIVE 검증 (§4.7):
active80_faithful.json(충실 제약 적합),diag2_alpha.json(캐스케이드별 실측 α), 원데이터는 Rizoiu 그룹 ACTIVE 공개 데이터셋data.csv(23,032 캐스케이드) - H-B 교차검증:
hb_spock.json - 코드:
kernels.py(커널·분기율 닫힌형),simulate.py(Ogata thinning 시뮬레이터),mle.py(다중 시작점 L-BFGS-B). 멱법칙 표시·비표시 로그우도(likelihood.py)와 ACTIVE 충실 제약 적합(faithful_constraint.py, SLSQP n*<1 제약)은 본 검증을 위한 독립 구현이며, 그 정당성은 §4.3·§4.4의 복원으로 교차검증됨. - 그림:
fig01_spock_cascade.png,fig02_intensity_fit.png,fig03_residual_qq.png,fig04_likelihood_ridge.png,fig05_phase0_distribution.png,fig06_phase1_distribution.png,fig07_hb_spock.png,fig08_phase2_marked.png,fig09_active_constraint.png - 동결일(frozen): 본 분석 실행 2026-06-10 (Spock 실데이터·Phase 0/1/2·ACTIVE·H-B 전체 재실행)
8. 참고문헌 (References)
- V. Filimonov and D. Sornette, "Apparent criticality and calibration issues in the Hawkes self-excited point process model: application to high-frequency financial data," Quantitative Finance 15(8):1293–1314 (2015), DOI:10.1080/14697688.2015.1032544; arXiv:1308.6756 (2013, rev. 2014).
- M.-A. Rizoiu, Y. Lee, S. Mishra, and L. Xie, "A Tutorial on Hawkes Processes for Events in Social Media," arXiv:1708.06401 (2017). [닫힌형 분기율 식 Eq. 1.37, 출처를 Mishra et al. 2016에 위임]
- S. Mishra, M.-A. Rizoiu, and L. Xie, "Feature Driven and Point Process Approaches for Popularity Prediction," in Proc. 25th ACM Int. Conf. on Information and Knowledge Management (CIKM '16), pp. 1069–1078 (2016), DOI:10.1145/2983323.2983812; arXiv:1608.04862. [닫힌형 분기율 제약 Eq. 4의 1차 출처]
- S. J. Hardiman and J.-P. Bouchaud, "Branching-ratio approximation for the self-exciting Hawkes process," Physical Review E 90(6):062807 (2014), DOI:10.1103/PhysRevE.90.062807; arXiv:1403.5227. [Fano-factor 기반 분기율 추정량의 원전]
- S. J. Hardiman, N. Bercot, and J.-P. Bouchaud, "Critical reflexivity in financial markets: a Hawkes process analysis," European Physical Journal B 86:442 (2013), DOI:10.1140/epjb/e2013-40107-3; arXiv:1302.1405. [4의 선행 연구; 동일 저자군의 멱법칙 Hawkes 분기율 분석]
- Y. Ogata, "On Lewis' simulation method for point processes," IEEE Transactions on Information Theory 27(1):23–31 (1981). [Ogata thinning 시뮬레이터]
- S. Wheatley, A. Wehrli, and D. Sornette, "The endo-exo problem in high-frequency financial price fluctuations and rejecting criticality," Quantitative Finance 19(7):1165–1178 (2019). [금융 임계성 주장의 보수적 재평가]
- R. Lemonnier and N. Vayatis, "Nonparametric Markovian learning of triggering kernels for mutually exciting and mutually inhibiting multivariate Hawkes processes," ECML-PKDD (2014); arXiv:1405.4175. [지수 커널 감쇠율 고정 필요성]
- T. Santos, F. Lemmerich, and M. Helic, "Caveats in fitting the Hawkes process to social media data," arXiv:2104.01029 (2021). [지수 커널 감쇠 모수 우도면의 평탄·비볼록 분지 실증; 소셜미디어 인접 맥락의 식별성 진단 선례]
- M.-A. Rizoiu, S. Mishra, Q. Kong, M. Carman, and L. Xie, "SIR-Hawkes: Linking Epidemic Models and Hawkes Processes to Model Diffusions in Finite Populations," WWW '18 (2018); arXiv:1711.01679. [HawkesN 모집단 크기 N의 비식별 — 본 연구와 구별되는 동일 저자군의 식별성 논의]
- D. J. Daley and D. Vere-Jones, An Introduction to the Theory of Point Processes, 2nd ed., Springer (2003). [점과정 로그우도·보상자의 표준 정식화]
- T. J. Rothenberg, "Identification in Parametric Models," Econometrica 39(3):577–591 (1971). [모수 식별성의 고전적 정의]
- E. L. Lehmann and G. Casella, Theory of Point Estimation, 2nd ed., Springer (1998). [추정·식별성의 표준 참고서]
If this writing helped, fuel the next one
