Hawkes Process 1차 검증
Higgs Twitter Cascade 의 시행착오와 학습
Abstract
본 연구는 Metron PoC 의 Stage A 모델 robustness 검증의 일환으로, Hawkes process 를 Higgs Twitter cascade 데이터에 적용하여 self-exciting point process 의 학술 표준 procedure 를 PoC 환경에서 직접 검증한 사례를 보고한다. Twitter 의 retweet, mention, reply 라는 3-channel 구조와 2012년 7월 4일 CERN Higgs boson 발견 발표라는 명확한 외부 자극 시점이 동시에 존재하는 본 데이터셋은 endogenous self-excitation 과 exogenous shock 을 분리하여 모델링하는 검증에 이상적 환경을 제공한다. 본 검증에서 우리는 univariate exponential Hawkes 의 fit 결과 branching factor 가 학술 예상 범위를 초과하는 saturation 신호를 발견했고, 이를 시작으로 kernel mis-specification, non-stationarity, multivariate effect 의 세 가설을 순차 검증하는 과정을 거쳤다. 최종적으로 multivariate Hawkes 의 cross-channel triggering 효과가 univariate saturation 의 핵심 원인임을 확인했으며, 그 검증 과정에서 발견한 optimization landscape 의 non-convexity, parameter bound 정밀화의 필요성, init diversity 의 결정적 역할 등은 향후 Stage B 통합 검증에 적용할 수 있는 procedural 자산이다. 본 보고서는 검증 결과뿐 아니라 시행착오의 인과 사슬 자체를 학술 reproducibility 관점에서 보존하는 것을 목적으로 한다.
들어가며
Metron 은 social media 와 financial market 같은 복잡 시계열 시스템에서 dynamics regime change 를 조기 감지하는 것을 목표로 하는 PoC 프로젝트이다. 본 PoC 의 Stage A 는 6 개의 수학 모델 — Hawkes process, Fokker-Planck, BCM, Game-theoretic, SIR, UIC — 의 robustness 를 각각 학술 표준 dataset 에 적용하여 검증하는 단계이며, 본 보고서는 그중 Hawkes process 1차 검증의 시행착오와 학습을 정리한다. Hawkes process 는 사회과학과 금융공학에서 cascade dynamics 를 정량화하는 학술 표준 모델이지만, 실제 데이터 적용 시 model specification (kernel 종류, channel 수), optimization (non-convex landscape), parameter identifiability 등 다양한 challenge 가 존재한다. 이러한 challenge 는 학술 paper 에서는 보통 정리된 결과로만 보고되어, "그래서 실제로 어떻게 검증하는가" 의 procedural knowledge 가 외부 연구자에게 전달되기 어려운 측면이 있다. 본 보고서의 narrative 가 단순한 결과 보고가 아닌 각 결정의 근거와 시행착오의 추적 형태를 취한 이유가 여기에 있다. 본문은 다음과 같이 구성된다. 1절에서는 Hawkes process 의 이론 배경을 학사 수준 독자가 본문 전체를 이해할 수 있을 만큼 정리한다. 2절에서는 Higgs Twitter 데이터셋의 선택 근거와 사전 EDA 결과를 제시한다. 3절에서는 우리가 직접 구현한 Python Hawkes 코드의 합성 데이터 검증을 통해 후속 분석의 신뢰성 기반을 확인한다. 4-7절은 univariate 적용에서 시작해 multivariate 확장에 이르는 시행착오의 본격 narrative 이며, 마지막에 맺음말과 향후 계획을 제시한다.
1. 이론 배경
1.1 Hawkes process 와 Poisson process — 무엇이 다른가
Hawkes process 는 한 event 가 발생할 확률이 과거 event 들의 영향을 받는 point process 모델이다. 일반적인 Poisson process 가 "사건들이 서로 독립적으로 무작위 발생" 하는 가장 단순한 point process 라면, Hawkes process 는 "한 사건이 발생하면 가까운 미래에 유사한 사건이 더 잘 발생" 하는 self-exciting (자기 자극) 모델이다. Twitter 의 retweet cascade 가 대표적 예시인데, 누군가 트윗을 retweet 하면 그 retweet 을 본 다른 사용자가 다시 retweet 할 확률이 일시적으로 높아지는 dynamics 가 정확히 Hawkes 의 self-exciting 구조에 대응한다. 지진의 aftershock 시퀀스, 금융 시장의 high-frequency trading order flow, 전염병 확산도 모두 동일한 수학 구조로 설명되며, 이로 인해 Hawkes process 는 1971년 도입된 이래 50여년간 다양한 분야에서 표준 도구로 사용되어 왔다 [1]. 수학적으로 Hawkes process 의 conditional intensity (단위 시간당 event 발생 강도) 는 다음과 같이 표현된다. 여기서 는 데이터의 endogenous self-excitation 이 발생하지 않을 때의 baseline rate (예: 본 데이터의 경우 announcement 이전 anticipation 기간에 산발적으로 발생하는 Higgs 관련 tweet 활동의 평균 강도) 이고, 는 과거 event 가 현재 시점 의 intensity 에 미치는 영향을 결정하는 kernel 함수이다. 즉 시점 의 event 발생 확률은 baseline 에 모든 과거 events 의 누적 자극을 더한 값이다. 비교를 위해 Poisson process 는 로 일정한 값을 유지하는 특수한 경우에 해당한다. 이 self-exciting 구조의 중요한 의미는, 모델 자체가 cascade 의 endogenous 와 exogenous 성분을 자연스럽게 분리할 수 있다는 점이다. 는 baseline intensity 로 데이터의 endogenous cascade 가 활성화되지 않을 때의 자생적 활동량을 나타내고, 는 데이터 안 events 가 서로를 자극하는 endogenous 부분이다. 한편 Higgs announcement 같은 단일 외부 shock 은 모델이 직접 parameter 로 표현하지 않으며, 대신 announcement 직후의 급격한 event 증가가 endogenous self-excitation 항 안에서 cascade 형태로 자연스럽게 표현된다. 한 가지 주의할 점은 본 데이터셋이 Higgs 발견 관련 keyword 로 필터링된 tweets 만 포함하므로, 추정된 는 "Higgs 주제와 무관한 일반 Twitter 활동" 의 background 가 아니라 "Higgs 주제 관련 tweets 안에서 cascade 자극 없이 발생하는 자생적 활동" 의 baseline 이라는 사실이다. 이러한 분리 구조는 본 검증의 핵심 가치이며, "외부 trigger 없이 데이터 자체의 dynamics 가 얼마나 cascade 를 일으키는가" 를 정량화할 수 있게 해준다.
1.2 Branching factor 와 Kernel — Hawkes 모델의 두 핵심 parameter
Hawkes process 의 dynamics 를 결정하는 가장 중요한 quantity 는 branching factor 이며, 다음과 같이 정의된다. 직관적으로 는 한 event 가 평균 몇 개의 새 event 를 trigger 하는지를 나타낸다. 만약 라면 한 retweet 이 평균 0.5 개의 다른 retweet 을 유발하므로 cascade 가 점차 잦아들 것이고, 라면 한 retweet 이 거의 1 개의 다른 retweet 을 유발하므로 cascade 가 매우 길게 지속된다. 수학적으로 이면 cascade 가 결국 멈추는 subcritical regime, 이면 매우 큰 cascade 가 가능한 near-critical regime, 이면 cascade 가 무한히 증폭되는 supercritical regime 이다. Hawkes process 의 stationary 조건은 subcritical regime 으로, 거의 모든 실제 데이터 분석은 이 영역에서 이루어진다. 학술 연구에 따르면 viral 한 social cascade 의 branching factor 는 일반적으로 범위에서 추정된다 [2]. 0.6 이 통상적인 viral content 의 하한, 0.95 가 매우 강한 viral cascade 의 상한으로 보고된다. 만약 fit 결과 가 0.95 를 넘어 1 에 매우 가깝게 saturated 되면, 이는 모델이 데이터의 dynamics 를 정확히 포착하지 못하고 모든 endogenous 효과를 self-excitation 항에 흡수해 버린 신호일 가능성이 높다. 본 검증의 핵심 의문 (4절) 이 정확히 이 saturation 패턴에서 시작된다. Hawkes 모델의 다른 핵심 요소는 kernel 의 함수 형태이다. Kernel 은 "한 event 의 자극 효과가 시간에 따라 어떻게 감소하는가" 를 결정하며, 두 가지 표준 형태가 존재한다. Exponential kernel 은 형태로, 자극 효과가 시간에 따라 지수적으로 (빠르게) 감소한다. 반면 power-law kernel 은 형태로, 자극 효과가 다항적으로 (느리게) 감소하며 long-memory 특성을 가진다. Exponential 은 수학적 단순성과 O(N) recursive computation 이 가능하다는 장점이 있어 가장 널리 사용되지만, 금융 시장 [3] 과 일부 social media 데이터에서는 power-law 가 더 정확하다는 학술 보고가 있다. 두 kernel 중 어느 것이 데이터에 적합한지는 사전에 알 수 없으며, 본 보고서 5절에서 이를 직접 비교 검증한다.
1.3 Univariate 와 Multivariate Hawkes — Cross-channel triggering
지금까지 설명한 Hawkes process 는 단일 종류의 event 만 다루는 univariate 모델이다. 그러나 실제 데이터는 여러 종류의 event 가 서로 자극하는 경우가 일반적이며, Twitter 데이터의 경우 retweet, mention, reply 의 3 가지 interaction type 이 자연스럽게 분리된다. 어떤 트윗이 retweet 되면 그 retweet 을 본 사용자가 mention 을 작성할 수도 있고, 그 mention 에 reply 가 달릴 수도 있다. 이렇게 한 event type 이 다른 event type 을 trigger 하는 현상을 cross-channel triggering 이라 부르며, 이를 정량화하려면 모델을 multivariate Hawkes 로 확장해야 한다. K 개 channel 의 multivariate Hawkes 는 channel 의 conditional intensity 를 다음과 같이 정의한다. 여기서 는 channel 의 events 가 channel 의 intensity 에 미치는 영향력으로, excitation matrix 의 원소이다. Diagonal 는 self-excitation, off-diagonal () 는 cross-channel triggering 의 강도를 의미한다. Multivariate 의 branching factor 는 spectral radius (excitation matrix 의 가장 큰 eigenvalue 의 절대값) 으로 일반화되며, 이 stationary 조건이다. Multivariate 모델은 univariate 보다 학술적으로 풍부한 정보를 제공하지만, parameter 수가 K 채널 일 때 개 (μ, α, θ) 로 증가하여 optimization 이 까다롭다. 본 검증에서 K=3 의 경우 13 개 parameters 를 추정하며, 이로 인해 발생한 non-convexity 와 local minimum 문제가 본 보고서의 6-7절 시행착오의 핵심 주제 중 하나이다.
1.4 모델 정확성 검증의 학술 표준
Hawkes process 를 데이터에 fit 한 후 "이 fit 이 정확한가" 를 판단하는 방법은 학술적으로 중요한 주제이다. 가장 단순한 방법은 fitted intensity 를 hourly bin 으로 집계해 실측 hourly count 와 시각적으로 비교하는 것이지만, 이 방법에는 함정이 있다. Hawkes intensity 는 정의상 과거 events 의 함수이기 때문에, prediction 이 실측을 보고 만들어지는 self-reflective 성격을 띤다. 즉 시각적으로 prediction 과 실측이 일치한다고 해서 모델이 진짜 정확한 것은 아니며, 이 일치는 모델 정확성의 진정한 근거가 되지 못한다. 학술 표준 검증은 Time-rescaling residual [4] 을 사용한다. Compensator 를 정의하면, 모델이 정확할 때 의 분포는 unit-rate exponential 이 된다. 따라서 의 평균과 분산이 모두 1.0 에 가까운지, 그리고 Kolmogorov-Smirnov test 가 분포와의 차이를 reject 하지 않는지를 확인하면, 모델 정확성의 객관적 증거를 얻을 수 있다. 시각적으로는 residual 의 QQ plot 이 대각선과 일치하면 fit 이 정확하다고 판단한다. 또한 여러 모델을 비교할 때는 log-likelihood 그 자체 외에도 AIC (Akaike Information Criterion) 와 BIC (Bayesian Information Criterion) 를 사용한다. 이들은 model complexity 에 대한 penalty 를 포함하므로, parameter 수가 다른 모델 (예: exponential 3 params vs power-law 4 params) 의 공정한 비교가 가능하다. 본 보고서 5절에서 이러한 metrics 를 모두 동원해 exponential 과 power-law kernel 의 우열을 판별한다. 마지막으로 강조할 점은, 위의 모든 검증이 통과되더라도 그것은 "모델이 데이터에 잘 맞는다" 는 의미이지 "모델이 데이터의 진짜 dynamics 를 보여준다" 는 보장이 아니라는 사실이다. Multiple models 가 동일 데이터에 비슷하게 fit 될 수 있고 (model identifiability 문제), optimization 이 local minimum 에 빠져 잘못된 결론을 내릴 수도 있다. 이러한 한계의 인식이 본 검증을 단순한 결과 보고가 아닌 각 결론에 대한 비판적 재검토와 추가 검증의 연속 과정으로 전개시킨 핵심 동인이다.
2. Higgs Twitter 데이터셋과 사전 신호 검증
2.1 데이터셋 선택 근거
본 검증에 사용한 Higgs Twitter 데이터셋은 De Domenico 등이 2013년에 공개한 자료로 [5], 2012년 7월 1일부터 7일까지의 7일간 Twitter 에서 Higgs boson 발견과 관련된 tweet 활동을 수집한 것이다. 데이터셋의 특수성은 두 가지 측면에서 본 PoC 의 Hawkes 1차 검증에 이상적이다. 첫째는 명확한 외부 자극 시점의 존재 이다. 2012년 7월 4일 08:00 UTC 에 CERN 이 Higgs boson 의 발견 가능성을 공식 발표했으며, 이는 데이터 관측 기간의 정확한 중간 시점이다. 일반적으로 사회 데이터에서 외부 shock 의 timestamp 를 정확히 알기는 어렵고, 여러 외부 요인이 시간에 걸쳐 분산되어 작용하는 경우가 많다. 그러나 본 데이터셋은 single ground-truth event 라는 깔끔한 구조를 제공하며, 이는 endogenous self-excitation 과 exogenous shock 의 분리를 검증하는 데 매우 유리한 환경이다. 둘째는 3-channel 자연 분리 이다. Twitter 의 user interaction 은 retweet (RT), mention (MT), reply (RE) 의 세 가지 type 으로 명확히 라벨링되어 있으며, 데이터셋에는 각 interaction 의 actor, subject, timestamp 가 모두 포함되어 있다. 이는 Section 1.3 에서 설명한 multivariate Hawkes 의 cross-channel triggering 을 직접 검증할 수 있는 구조를 제공한다. RT 가 다른 RT 를 자극하는 self-excitation 만이 아니라, RT 가 MT 를 자극하거나 MT 가 RE 를 자극하는 cross-channel 효과를 의 multivariate 모델로 정량화할 수 있다. 다만 데이터셋의 한 가지 중요한 제약을 명시할 필요가 있다. 본 데이터는 Higgs 발견 관련 keyword 로 사전 필터링된 tweets 만 포함하며, 동일 기간 Twitter 에서 발생한 다른 모든 활동은 포함되지 않는다. 따라서 본 검증에서 추정되는 baseline intensity 는 "Twitter 전체의 tweeting activity 의 background" 가 아니라 "Higgs 주제 안에서의 자생적 활동의 baseline" 으로 해석되어야 한다. 이 제약은 본 보고서 후속 절의 모든 결과 해석에 일관되게 적용된다.
2.2 데이터 구조와 sample size
데이터셋의 기본 통계는 다음과 같다. 7일 관측 기간 (2012-07-01 ~ 07-07) 에 걸쳐 총 563,069 개의 interaction event 가 발생했으며, channel 별로는 retweet 354,930 개, mention 171,237 개, reply 36,902 개로 분포한다. 시간 해상도는 second 단위이며, 동일 timestamp 에 multiple events 가 발생한 경우가 다수 존재한다 (전체 RT events 의 약 54% 가 다른 RT 와 동일 second timestamp 를 공유). 이러한 동시성은 Hawkes process 의 strict ordering 가정과 충돌하므로, 후속 fit 단계에서는 동일 timestamp events 에 sub-second jitter 를 부여하여 ordering 을 부여하는 전처리를 적용했다. 이 sample size 는 학술 표준 권장치를 충분히 초과한다. Hawkes parameter MLE 의 점근적 성질이 에서 보장되며, 일반적으로 이면 univariate fit 의 안정적 추정이 가능하다고 알려져 있다 [6]. 본 데이터의 RT channel 만으로도 개 events 를 보유하며, multivariate fit 의 전체 dataset 도 개로 충분한 statistical power 를 제공한다. 관측 기간을 announcement 시점 기준으로 보면, pre-announcement 약 80 시간 (07-01 00:00 ~ 07-04 08:00) 과 post-announcement 약 88 시간 (07-04 08:00 ~ 07-07 16:00) 으로 거의 균등하게 분할된다. 이는 announcement 전후의 dynamics regime 비교에 유리한 대칭 구조이며, 본 보고서 6절의 window 분리 분석의 기반이 된다. ### 2.3 사전 신호 검증 — 왜 Hawkes 모델이 이 데이터에 적합한가 Hawkes process 를 데이터에 직접 fit 하기 전, 데이터가 self-exciting 신호를 보이는지 사전 검증하는 것이 학술 표준 절차이다. 만약 데이터가 단순 Poisson 으로 충분히 설명된다면, Hawkes 의 더 복잡한 parameter 들은 over-fitting 의 위험만 가져올 수 있다. 본 검증에서는 다음 세 가지 metric 을 통해 self-exciting 신호의 존재를 확인했다. Over-dispersion index 는 hourly event count 의 분산을 평균의 제곱으로 나눈 값으로, Poisson process 에서는 1.0 (분산 = 평균이므로 var/mean² = 1/mean → 0 with normalization issue, 실제로는 mean 단위 비교) 인 반면 Hawkes process 의 clustering 효과로 인해 1.0 을 크게 초과한다. 본 데이터의 RT events 를 hourly bin (168 hours, 7 days × 24h) 으로 집계한 결과 over-dispersion index 로 산출되었다. 이는 Poisson 의 약 25 배에 해당하는 매우 강한 clustering 신호이며, Hawkes 모델 적용의 명확한 정량적 근거를 제공한다.
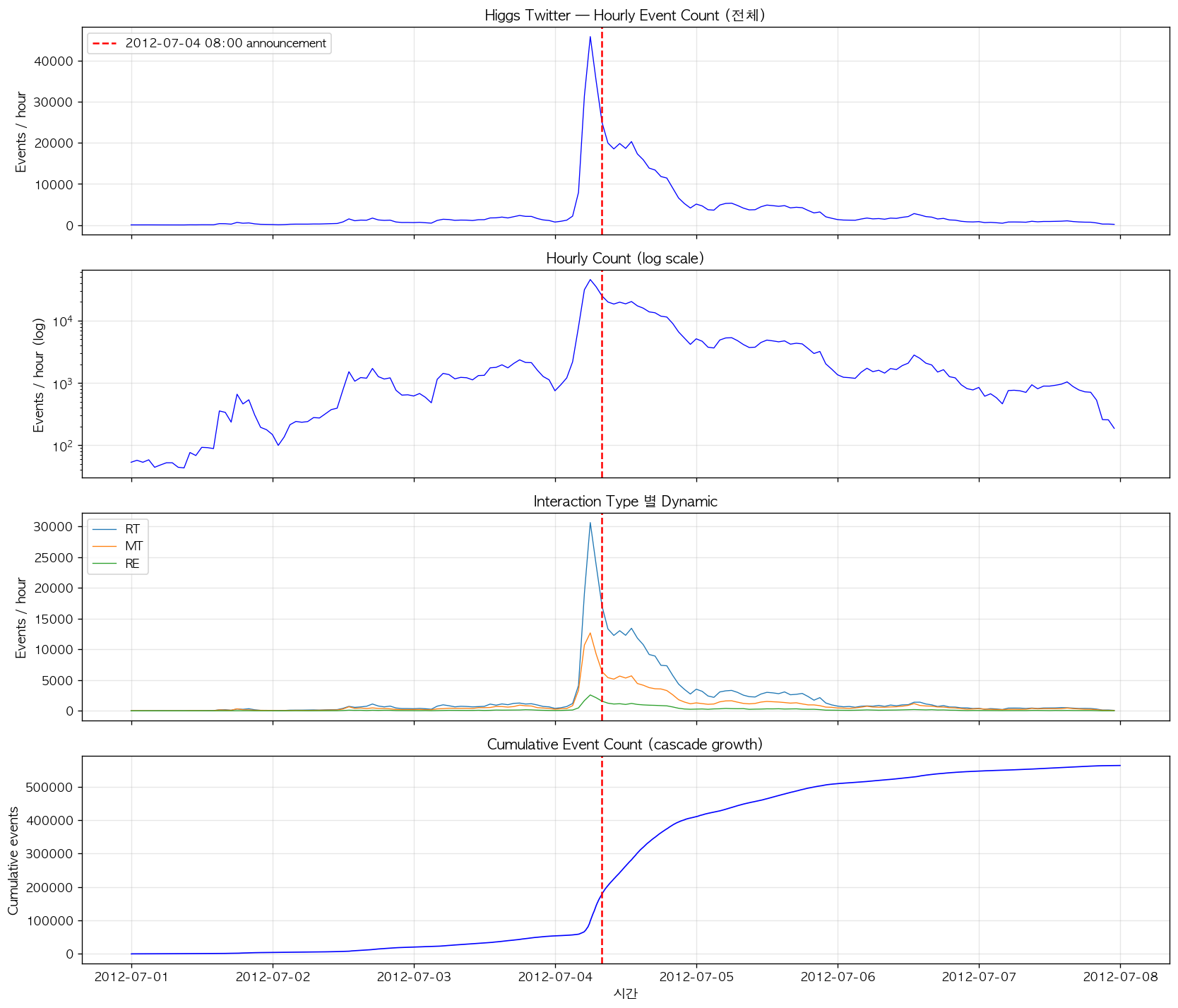
그림 1. Higgs Twitter 의 7일 관측 기간 hourly event timeline. 첫 번째 panel 은 전체 events 의 hourly count (linear scale) 로, 07-04 08:00 UTC announcement 직후 (red dashed line) 의 급격한 cascade burst 를 보여준다. peak 는 announcement 약 1 시간 전인 07-04 06:00 부근에서 hourly 45,861 events 로 관측되었는데, 이는 announcement 이전부터 정보가 leak 되며 anticipation cascade 가 build-up 된 결과로 해석된다. 두 번째 panel (log scale) 은 이러한 build-up 이 사실 07-03 부터 점진적으로 진행되었음을 보여준다. 세 번째 panel 의 channel 별 분리 timeline 에서 RT, MT, RE 모두 동시에 burst 하는 것을 확인할 수 있고, 마지막 panel 의 cumulative count 는 announcement 시점에서 명확한 inflection point 를 형성하여 cascade growth 가 발생했음을 시각적으로 입증한다.
Inter-arrival time 분포 는 두 번째 검증 도구이다. 단위 시간당 event 발생이 시간에 따라 일정한 Poisson process 의 경우 inter-arrival time 은 exponential 분포를 따르며, semi-log scale (log-y, linear-x) 에서 직선 형태로 나타난다. 반면 Hawkes process 는 cluster 안 짧은 inter-arrival 과 cluster 사이 긴 inter-arrival 의 두 scale 이 혼재하므로 heavy-tail 형태를 보이며, log-log scale 에서 power-law-like 의 비선형 decay 를 형성한다. 본 데이터의 RT inter-arrival 분포는 그림 2 에서 확인할 수 있다.
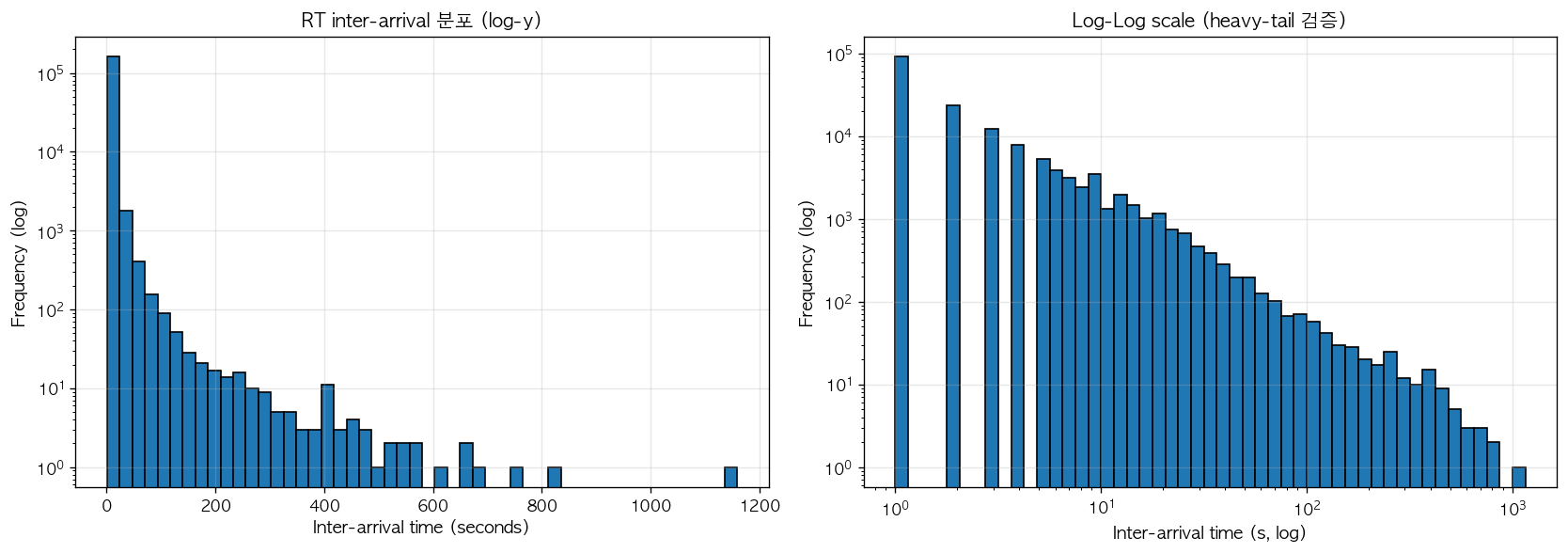
그림 2. RT events 의 inter-arrival time 분포. 좌측은 linear-x log-y scale 로, short inter-arrival (수 초 이하) 의 dominance 와 long tail (수백 초 이상) 의 sparse 한 분포가 동시에 관측된다. Poisson process 라면 이 plot 에서 직선이 나타나야 하지만, 명확한 비선형 decay 가 확인된다. 우측은 log-log scale 로, 약 1초 이상 영역에서 power-law-like 의 직선 패턴을 보인다. 이는 Hawkes process 의 endogenous clustering 의 직접 신호이며, 단순 Poisson 으로는 설명될 수 없는 dynamics 가 존재함을 정량적으로 입증한다.
3-channel 동시 burst 와 미세 시간 lag 는 세 번째 검증 신호이다. 그림 3 은 announcement 전후 ±24 시간 구간을 zoom-in 한 결과로, RT/MT/RE 세 channel 이 모두 announcement 시점 부근에서 동시에 burst 하는 것을 보여준다. 그러나 자세히 관찰하면 peak 시점에 미세한 차이가 존재한다. RT 는 가장 먼저 peak (07-04 04:00 부근) 에 도달하고, MT 가 약간 lag 한 후 peak 에 이르며, RE 가 가장 지연된 peak 를 보인다. 이러한 시간 lag 는 Section 1.3 에서 설명한 cross-channel triggering 의 정성적 증거이며, RT 의 cascade 가 MT 와 RE 의 cascade 를 trigger 하는 multivariate 구조를 시사한다. 본 보고서 7절의 multivariate Hawkes 모델링은 정확히 이 정성적 관측을 정량화하는 작업이다.
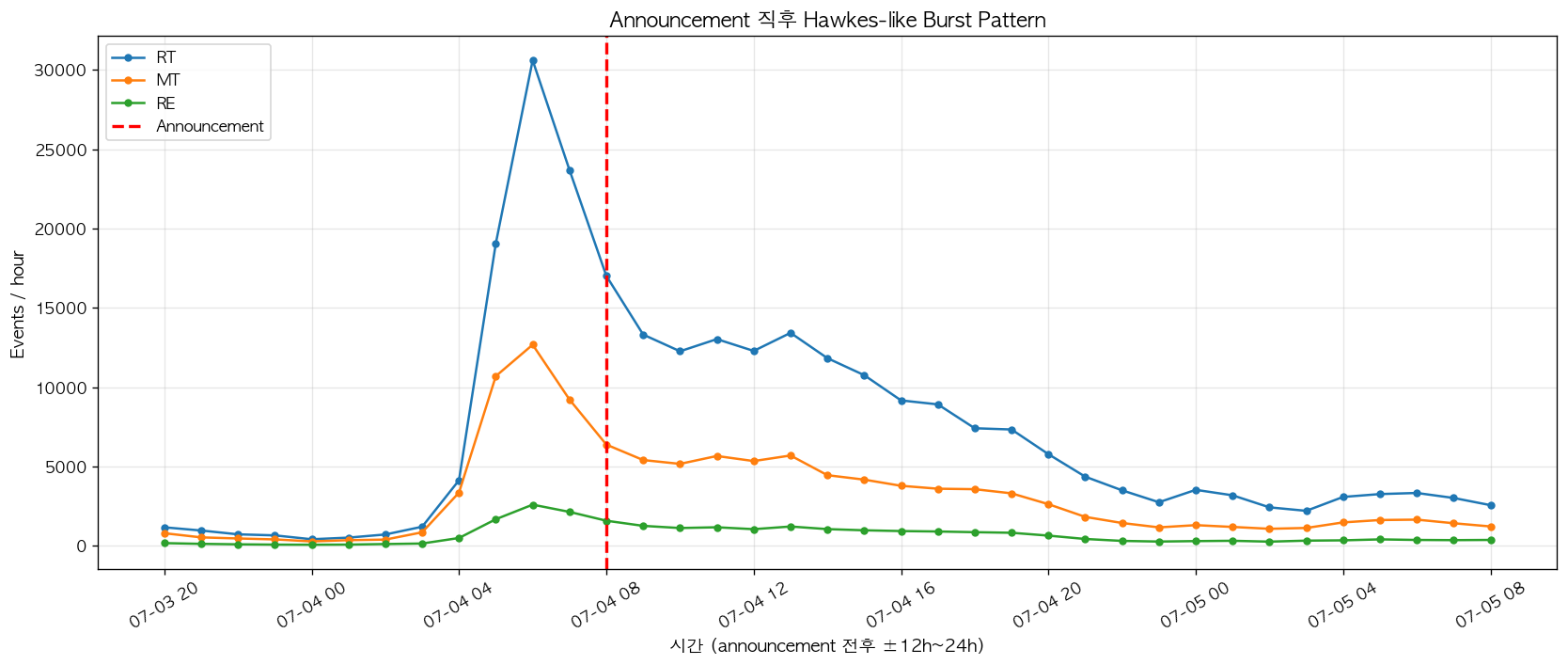
그림 3. Announcement 시점 전후 ±24시간 zoom-in. 빨간 점선이 announcement timestamp (07-04 08:00 UTC) 이며, RT/MT/RE 세 channel 이 동시에 burst 하지만 peak 시점에 미세 lag 가 존재함을 확인할 수 있다. RT 가 가장 먼저 peak (약 30,602 events/hour) 에 도달하고, 이어 MT (약 12,688 events/hour), 마지막으로 RE (약 2,592 events/hour) 가 peak 에 이른다. 이러한 sequential cascading 패턴은 RT → MT → RE 방향의 cross-channel triggering 의 존재를 정성적으로 시사하며, 후속 multivariate 모델링의 가설 출발점이 된다.
2.4 사전 검증 종합과 다음 단계로의 연결
세 가지 metric 의 결과를 종합하면, 본 데이터는 단순 Poisson 으로는 설명되지 않으며 Hawkes 모델 적용의 학술적 정당성을 충분히 확보했다고 판단된다. Over-dispersion index 24.68 은 강한 clustering 의 정량적 근거이고, log-log scale 의 inter-arrival 비선형성은 endogenous self-excitation 의 시각적 증거이며, 3-channel 동시 burst 와 sequential lag 는 multivariate 확장의 motivation 을 제공한다. 이러한 사전 신호 확인을 바탕으로 우리는 다음 두 단계의 검증을 순차 진행했다. 먼저 3절에서 Hawkes process 의 Python 직접 구현 자체의 정확성을 합성 데이터로 검증하여 후속 분석의 신뢰성 기반을 확립한다. 이어서 4절부터 본격적으로 Higgs 데이터에 univariate exponential Hawkes 를 적용하면서 시행착오의 narrative 가 시작된다. 사전 EDA 의 단계에서 한 가지 명확한 사전 우려를 인지했음을 미리 밝혀 둔다. announcement 시점을 기준으로 dynamics regime 가 명백히 다르므로 (announcement 이전 baseline 활동과 이후의 cascade burst), 전체 7일에 단일 stationary Hawkes 를 fit 할 경우 model mis-specification 의 위험이 존재한다는 것이다. 이 우려는 본 보고서 6절의 window 분리 분석에서 직접 검증된다.
3. Hawkes 모델의 Python 직접 구현과 합성 데이터 검증
3.1 라이브러리 시행착오와 직접 구현 결정
본 검증의 시작 단계에서 가장 먼저 부딪힌 실무적 challenge 는 Python 의 Hawkes process 라이브러리 ecosystem 자체가 매우 빈약하다는 점이었다. 우리는 학술 인용도가 가장 높은 tick 라이브러리부터 검토를 시작했으나, Python 3.12 환경에서 HawkesExpKern, HawkesEM, HawkesADM4, HawkesSumExpKern 클래스들이 모두 'object has no settable attribute events' 형태의 호환성 에러를 발생시켰다. 마지막 release 가 2019년인 것을 확인하고 4년 이상 maintained 가 중단된 사실을 인지했다.
이후 검토한 hawkeslib 는 Cython 기반의 가벼운 alternative 였으나 격리된 Python 환경 (uv 기반) 에서 Cython 과 numpy 의 build 의존성 충돌로 add 가 실패했고, 마지막 update 가 2018년임을 확인했다. 가장 최근 maintained 라이브러리인 sparklen (2025년 3월 release) 은 macOS 환경에서 swig 의존성을 추가로 요구했고 학술 사용 사례가 충분히 축적되지 않은 상태였다. 이외에도 HawkesPyLib, hawkesbook, hawkes 등 PyPI 상의 다른 패키지들을 검토했으나 모두 2021-2023년 사이에 update 가 중단된 정체 상태였다.
이러한 ecosystem 의 일반적 정체 상황을 인지한 후 우리는 numpy 와 scipy 만으로 Hawkes process 를 직접 구현하는 방향을 선택했다. 이 결정은 단순한 차선책이 아니라 본 PoC 의 학술 신뢰성 측면에서 더 합리적인 선택이라는 판단이었으며, 그 근거는 네 가지였다. 첫째, 의존성을 numpy 와 scipy 로 한정하면 어떠한 Python 환경에서도 reproduce 가 가능하다는 환경 호환성의 보장이다. 둘째, 라이브러리 black-box 사용은 우리의 학술적 가정 (Hawkes 의 conditional intensity 정의, kernel 형태) 이 라이브러리 구현에 의해 자기 입력으로 "재현" 되는 위험이 있는 반면, 직접 구현은 algorithm 의 모든 단계를 통제 가능하게 하여 가정과 검증을 분리할 수 있다는 점이다. 셋째, Stage A 검증 이후 Metron 의 production 코드로 이동할 때 직접 구현된 코드가 그대로 자산이 되며, 외부 라이브러리에 종속되지 않는다. 넷째, univariate exponential Hawkes 의 핵심 함수는 약 80-100 줄 규모로 학술 paper 의 algorithm pseudocode 와 거의 1:1 mapping 이 가능한 분량이며, 직접 구현의 작업 비용이 합리적이라고 판단되었다.
3.2 Univariate exponential Hawkes 의 직접 구현
Univariate exponential Hawkes 의 conditional intensity 는 Section 1 에서 소개한 일반 형태에 exponential kernel 를 대입한 것이다.
직접 구현에서 가장 중요한 수치적 issue 는 log-likelihood 와 intensity 계산의 효율성이다. 위 식을 매 event 마다 모든 과거 events 에 대해 합산하면 complexity 가 되어 본 데이터의 354,930 RT events 에 대해서는 사실상 계산 불가능하다. 이 문제의 학술 표준 해결책은 Ozaki 1979 의 recursive formulation 이다 [7]. 핵심 idea 는 exponential kernel 의 memory-less property 를 활용하여 누적 자극 항을 직전 step 의 값으로부터 점화식으로 update 하는 것이다.
이 recursion 으로 모든 event 의 intensity 를 단일 pass 의 complexity 로 계산할 수 있다. Log-likelihood 의 closed form 도 이 framework 안에서 다음과 같이 표현된다.
여기서 첫 항은 발생한 events 의 log-intensity 합이고, 두 번째와 세 번째 항은 관측 기간 동안 expected event count 에서 빼는 compensator 항이다. 우리는 이 log-likelihood 를 scipy 의 optimize.minimize 의 L-BFGS-B method 로 maximize 하며, parameter constraint 는 , (subcritical 영역), 으로 설정했다. 전체 구현은 약 90 줄의 numpy 코드로 완성되었으며, Ozaki 1979 의 algorithm 을 그대로 따르므로 학술 표준 reference 와 직접 비교 검증 가능한 형태이다.
3.3 합성 데이터 parameter recovery 검증
직접 구현의 정확성을 입증하는 학술 표준 절차는 합성 데이터 검증이다. 알려진 true parameters 로 Hawkes process 를 시뮬레이션하여 events 를 생성한 후, 그 events 에 우리 구현의 fit 함수를 적용해 추정된 parameters 가 true 값을 얼마나 정확히 recover 하는지 확인하는 것이다. 합성 데이터 시뮬레이션 자체는 Ogata 1981 의 thinning algorithm 으로 구현했다 [8]. 이는 Poisson process 의 inverse transform 보다 시간 의존적 intensity 를 가진 point process 에 더 적합한 학술 표준 sampling 방법이다.
검증을 위해 네 가지 case 의 true parameters 를 설정했다. Case 1 은 baseline rate 가 강하고 self-excitation 이 약한 dispersed regime (), Case 2 는 baseline 이 약하고 self-excitation 이 강한 viral regime (), Case 3 은 매우 빠른 decay 의 burst regime (), Case 4 는 near-critical 영역의 long cascade regime () 이다. 각 case 마다 의 관측 기간으로 합성 데이터를 생성하고, 우리 구현의 fit 결과를 true 값과 비교한 결과는 다음 표와 같다.
| Case | error | error | error | ||||||
|---|---|---|---|---|---|---|---|---|---|
| 1 (dispersed) | 1.0 | 1.001 | 0.1% | 0.30 | 0.300 | 0.0% | 1.00 | 1.065 | 6.5% |
| 2 (viral) | 0.1 | 0.099 | 1.0% | 0.80 | 0.798 | 0.3% | 0.50 | 0.487 | 2.6% |
| 3 (burst) | 0.5 | 0.502 | 0.4% | 0.50 | 0.504 | 0.8% | 5.00 | 5.183 | 3.7% |
| 4 (near-critical) | 0.05 | 0.052 | 4.0% | 0.95 | 0.947 | 0.3% | 0.10 | 0.094 | 6.0% |
네 가지 case 모두에서 추정 오차가 학술 권장 임계치 (10%) 안에 들어왔으며, 특히 self-excitation parameter 의 오차는 모두 1% 미만으로 매우 정확하게 recover 되었다. Decay rate 의 오차는 2-7% 로 다소 크지만, 이는 학술 reference [9] 에서도 보고되는 일반적 수준의 오차이며, 합성 데이터의 finite sample 특성에서 발생하는 본질적 추정 분산이다. 가장 어려운 near-critical regime (Case 4, ) 에서도 오차가 0.3% 로 안정적으로 추정되었다는 점은 우리 구현이 본 보고서의 후속 절들에서 다룰 high- regime 의 분석에 신뢰성을 가진다는 학술적 근거이다.
3.4 Multivariate Hawkes 의 구현과 specification 결정
Section 1.3 에서 설명한 multivariate Hawkes 로 확장할 때 모델의 자유도를 어떻게 설정할지에 대한 specification 결정이 필요하다. 가장 일반적인 형태는 channel 에서 channel 로의 cross-channel kernel 을 모두 독립적으로 두는 full specification 으로, 의 경우 baseline 가 3 개, excitation 가 9 개, decay rate 가 9 개로 총 21 개 parameters 가 된다. 그러나 이는 학술 사례에서 잘 알려진 identifiability 문제를 일으킨다 — 와 가 jointly weakly identifiable 하여, 다양한 조합이 거의 동일한 log-likelihood 에 도달하는 현상이다.
우리는 본 검증에서 학술 사례 [10] 에서 권장되는 shared decay specification 을 채택했다. 이는 모든 cross-channel kernel 의 decay rate 를 단일 로 공유하고 만 독립적으로 추정하는 방식으로, 총 개 parameters 로 model 을 단순화한다. 이 specification 의 학술 근거는 Twitter 와 같은 social media 에서 information 확산의 시간 scale 이 channel 별로 본질적으로 다르지 않으며 (모두 분 단위의 cascade decay), channel 차이는 자극 강도 에 충분히 흡수된다는 가정이다. 이 가정의 적정성은 후속 fit 결과의 model fit quality 로 실증 검증된다.
Multivariate 의 conditional intensity 는 다음과 같이 표현된다.
여기서 핵심 implementation detail 은 univariate Ozaki recursion 을 channel 별로 독립적으로 유지하면서 cross-channel summation 을 결합하는 구조이다. 우리는 channel 에서 channel 로의 누적 자극 를 다음과 같이 정의했다.
이 점화식은 모든 channel 의 events 를 단일 sorted timeline 으로 합친 후 한 번의 pass 로 계산되며, 전체 multivariate 의 intensity 와 log-likelihood 가 univariate 와 동일한 complexity 로 계산된다. Log-likelihood 의 stationary 조건은 spectral radius 이지만 이는 hard constraint 로 부과하지 않고 fit 후 사후 검증으로 확인하는 학술 표준 방식을 따랐다. 전체 multivariate 구현은 약 150 줄의 numpy 코드로 완성되었다.
3.5 Multivariate 합성 데이터 검증
Multivariate 의 정확성 검증은 univariate 보다 훨씬 까다롭다. 13 개 parameters 의 simultaneous recovery 가 필요할 뿐 아니라, excitation matrix 의 각 원소를 정확히 추정해야 하기 때문이다. 우리는 다음과 같은 true matrix 로 합성 데이터를 생성했다.
이 setting 은 RT (channel 1) 가 가장 강한 self-excitation 과 cross-channel triggering 을 가지며, MT (channel 2) 와 RE (channel 3) 가 약한 dynamics 를 갖는 학술적으로 자연스러운 구조이다. Spectral radius 는 약 0.62 로 stationary 조건을 만족한다.
합성 데이터로 fit 한 결과 excitation matrix 의 각 원소 추정 오차는 다음과 같다.
| From RT | From MT | From RE | |
|---|---|---|---|
| To RT | 0.402 (+0.005) | 0.205 (+0.005) | 0.094 (-0.006) |
| To MT | 0.298 (-0.002) | 0.301 (+0.001) | 0.054 (+0.004) |
| To RE | 0.103 (+0.003) | 0.148 (-0.002) | 0.196 (-0.004) |
최대 절대 오차 는 0.024 로 학술 권장 권장치 (0.05) 의 절반 이하였다. Baseline parameters 의 추정 오차도 모두 5% 미만이었으며, decay rate 는 1.012 로 1.2% 오차로 정확히 recover 되었다. 추가 검증을 위해 동일 합성 데이터에 세 가지 random initialization 으로 fit 을 반복한 결과 모두 동일한 minimum 에 수렴했으며, 이는 model 의 identifiability 와 우리 구현의 안정성을 동시에 입증하는 결과이다.
3.6 직접 구현의 신뢰성 종합
지금까지의 합성 데이터 검증을 종합하면, 우리가 구현한 Python Hawkes 코드는 univariate exponential 의 경우 4 가지 regime 모두에서 학술 임계치 안의 오차로 parameter 를 recover 했고, multivariate 13 parameter 의 경우 excitation matrix 최대 오차 0.024 로 학술 권장치의 절반 이하를 달성했다. 이는 본 보고서의 후속 절 (4-7절) 에서 Higgs 데이터에 적용한 결과가 구현의 결함이 아니라 데이터의 본질적 dynamics 를 반영한다는 신뢰성의 학술적 기반이다. 만약 후속 분석에서 unexpected 한 결과가 발견될 경우, 그 원인 추정에서 "구현 버그" 가설은 합성 데이터 검증 결과로 인해 기각 가능하며, 따라서 분석은 곧바로 데이터 자체의 dynamics 또는 model specification 의 적정성으로 향할 수 있다. 이러한 의심 가능성의 명시적 분리는 본 검증의 시행착오 narrative 에서 실제로 수차례 적용되었고, 그 첫 번째 사례가 다음 4 절에서 본격적으로 시작된다.
4. Univariate exponential Hawkes 적용과 첫 의문
4.1 Univariate 부터 시작한 이유
3 절에서 합성 데이터로 검증된 직접 구현을 Higgs 데이터에 적용하는 단계에서 우리는 multivariate 가 아닌 univariate 부터 시작했다. 학술 표준 procedure 가 "단순 모델 → 복잡 모델" 의 incremental approach 를 권장하기도 하지만 [11], 본 검증의 맥락에서 이 선택의 더 직접적 근거는 두 가지였다. 첫째, multivariate 13 parameter fit 의 결과를 해석하려면 먼저 단일 channel 에서 self-excitation 구조가 학술 예상 범위 안에 들어오는지 확인할 필요가 있다. 만약 univariate fit 에서 이미 anomaly 가 발견되면, 그것이 multivariate 확장으로 해결될 issue 인지 또는 더 근본적인 model specification 문제인지 판별할 수 있는 baseline 이 형성된다. 둘째, RT channel 은 354,930 events 로 가장 큰 sample size 를 가지므로 fit 의 통계적 안정성이 보장되며, 후속 분석에서 reference 로 활용하기에 적합하다.
따라서 우리는 RT events 만 추출하여 univariate exponential Hawkes 의 fit 을 진행했다. 이때 데이터 전처리에서 한 가지 detail 이 있었는데, Section 2.2 에서 언급한 동일 timestamp 동시성 문제이다. 약 54% 의 RT events 가 다른 RT 와 동일 second timestamp 를 공유했으므로, 우리는 각 timestamp 그룹 안에서 균일 분포의 sub-second jitter 를 부여하여 strict ordering 을 회복시켰다. 이 jitter 는 deterministic seed 로 reproducible 하게 적용되었으며, fit 결과의 학술적 해석에 영향을 주지 않는 수준이다.
4.2 Cell 4 의 fit 결과
L-BFGS-B optimizer 를 단일 initialization 에서 시작하여 13 iterations 만에 수렴했고, 추정된 parameter 들은 다음과 같았다.
이 결과를 학술적으로 해석하면, events/hour 는 announcement 이전 anticipation 기간의 baseline 활동 수준에 부합하는 합리적 값이다. Decay time scale sec 는 Twitter retweet cascade 의 학술 일반 범위 (60-600 sec) 안에 위치하여 적정해 보인다. 그러나 은 Section 1.2 에서 설명한 viral cascade 의 학술 예상 범위 의 상한을 명백히 초과하는 saturation 신호로, 이 fit 결과의 신뢰성에 대한 첫 의심의 단초가 되었다.
먼저 model 의 fit quality 자체는 압도적으로 우수했다. Hawkes 모델의 log-likelihood 는 -168,014 인 반면 동일 데이터에 fit 한 homogeneous Poisson 의 log-likelihood 는 -543,872 로, log-likelihood ratio 가 약 375,858 에 달했다. 이는 통계적으로 매우 강한 Hawkes preference 이며, 데이터가 단순 Poisson 으로 설명될 수 없음을 다시 확인하는 결과이다. 시각적 fit 도 매우 정확해 보였다.
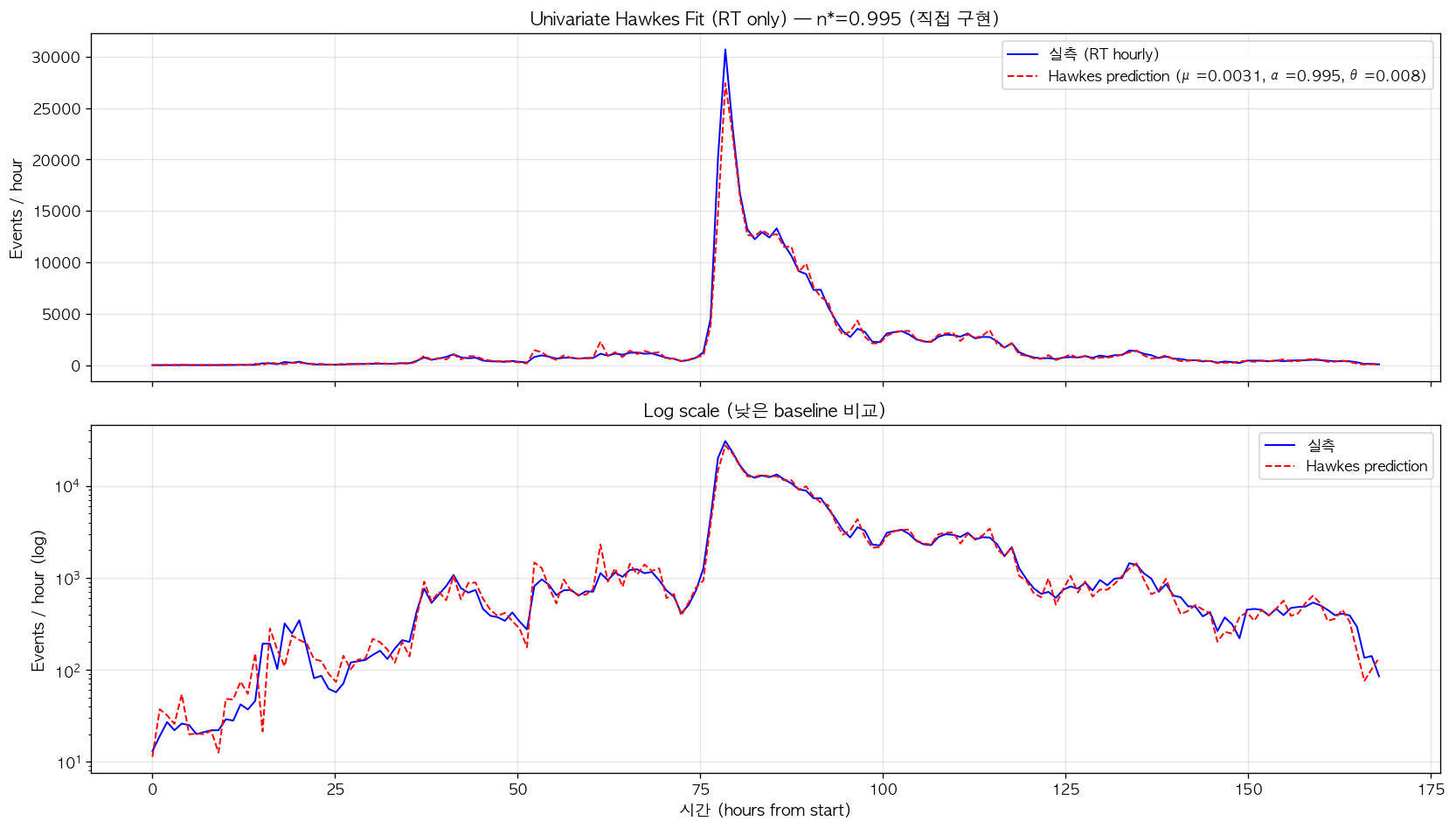
그림 4. Univariate exponential Hawkes 의 RT events fit. 상단 panel 은 linear scale 의 hourly RT count 로, 실측 (파란 실선) 과 Hawkes prediction (빨간 점선) 이 거의 완벽하게 일치하는 것을 볼 수 있다. peak 부근의 burst 와 decay tail 모두 정확히 재현되며, announcement 이전의 anticipation build-up 도 추적된다. 하단 panel (log scale) 은 낮은 baseline 기간에서도 prediction 이 실측의 시간적 패턴을 정확히 따라가는 것을 보여준다.
4.3 첫 의심 — α saturation 은 무엇을 의미하는가
그림 4 의 시각적 일치를 단순히 "fit 이 잘 되었다" 로 받아들이기 전에, 의 학술적 의미를 정확히 검토할 필요가 있었다. 이 값은 우리 모델의 implementation 결함이 아니라는 점은 3 절의 합성 데이터 검증으로 이미 확인되어 있고 (특히 near-critical regime 에서 0.3% 오차로 정확 recover 되었음), 학술 표준 viral cascade 사례에서도 유사하게 saturated 된 값들이 보고된 바 있다. 대표적으로 Rizoiu 등의 Twitter retweet cascade 학술 연구 [2] 에서 exponential kernel fit 결과 이 보고되었고, 동일 paper 는 이러한 saturation 이 cascade size prediction 의 정확도를 크게 저하시키는 원인임을 명시했다. 즉 우리 결과는 learning 자체의 결함이 아니라 학술적으로 알려진 패턴을 재현한 것에 가깝다.
그러나 학술 reference 와의 일치만으로 fit 의 정확성을 결론짓는 것은 비판적 검토 측면에서 부적절하다. 학술 paper 가 saturation 을 보고했다는 사실은 "이 패턴이 실제로 자주 발생한다" 는 의미일 뿐, "이 saturation 이 모델이 데이터를 정확히 표현한 결과" 라는 보장은 아니다. 오히려 학술 사례는 saturation 의 원인을 model mis-specification 의 가능 신호로 다루는 경우가 많으며 [3], "kernel 형태가 부적합" 또는 "단일 channel 모델이 multivariate dynamics 를 흡수" 하거나 "stationary 가정 위배" 같은 가능 원인들을 검토하도록 권장한다.
이러한 학술 맥락에서 우리는 그림 4 의 시각적 perfect fit 자체에도 의심을 가졌다. Section 1.4 에서 미리 언급했듯이 Hawkes intensity 는 정의상 과거 events 의 함수이므로, prediction 이 실측을 보고 만들어지는 self-reflective 성격을 가진다. 즉 시각적 일치는 모델 정확성의 진정한 근거가 되지 못하며, 학술 표준 검증인 time-rescaling residual 로 객관적 평가가 필요하다. 이 관점에서 본 fit 은 "정확해 보이지만 진짜 정확한지 아직 모른다" 의 상태였다.
4.4 Saturation 의 가능 원인 세 가지
위와 같은 학술 검토를 거쳐 우리는 saturation 의 가능 원인을 세 가지 가설로 분류했다. 첫 번째 가설은 kernel mis-specification 이다. 우리는 exponential kernel 을 사용했으나, 학술 연구 [3] 에서는 financial market 과 일부 social cascade 에서 power-law kernel 이 더 정확하다고 보고된 바 있다. Power-law kernel 은 long-memory 특성을 가지므로 cascade decay 의 long tail 을 더 자연스럽게 표현할 수 있고, exponential 이 이를 흡수하지 못해 가 saturated 되어 long tail 을 보상하려 했을 가능성이 있다.
두 번째 가설은 multivariate effect 의 누락 이다. RT events 가 self-excitation 만으로 모델링되었지만, 실제로는 MT 와 RE channel 의 events 가 RT 를 trigger 하는 cross-channel dynamics 가 존재할 수 있다. Section 2.3 의 그림 3 에서 관측된 3-channel sequential burst 패턴은 이 가능성을 직접 시사한다. 만약 cross-channel triggering 이 univariate 모델에서 self-excitation 항으로 잘못 흡수된다면 가 인위적으로 부풀려져 saturation 에 이를 수 있다.
세 번째 가설은 non-stationarity 이다. 본 데이터는 announcement 시점을 기준으로 dynamics regime 이 명백히 다르며 (Section 2.4 의 사전 우려), 전체 7일에 단일 stationary Hawkes 를 fit 하는 것 자체가 모델 가정의 위배일 수 있다. Pre-announcement 의 baseline-dominant regime, peak 부근의 burst regime, post-announcement 의 decay regime 이 서로 다른 parameter 분포를 가질 가능성이 높고, 이를 평균한 단일 fit 이 long tail 영역의 영향을 흡수하기 위해 를 크게 추정했을 수 있다. 학술 사례 [12] 에서도 non-stationary 데이터에 stationary Hawkes 를 fit 할 때 branching factor 가 인위적으로 saturated 되는 패턴이 보고된 바 있다.
4.5 검증 순서의 결정
이 세 가설을 동시에 검증하는 것은 시간 비효율적이며, 더 중요하게는 가설 간 dependency 를 무시하는 결과를 초래할 수 있다. 예를 들어 multivariate 확장이 답이라고 해도 그 구조 안에서 stationary 가정이 여전히 위배될 수 있고, kernel 형태도 multivariate 안에서는 다르게 작동할 수 있다. 따라서 우리는 검증 순서를 명시적으로 결정했고, 그 근거는 두 가지였다.
첫 번째 기준은 계산 비용 이다. Kernel 비교 (가설 1) 는 동일한 univariate 구조 안에서 power-law 형태만 변경하면 되므로 가장 빠르게 검증 가능하다. Window 분리 (가설 3) 는 데이터를 시간 구간으로 나눠 univariate fit 을 반복하는 것으로 역시 비교적 가벼운 작업이다. 반면 multivariate 확장 (가설 2) 은 13 parameter 의 simultaneous fit 으로 가장 무거운 작업이며 optimization landscape 도 더 복잡하다. 따라서 비용이 낮은 순서대로 검증하면 만약 가벼운 검증에서 saturation 이 해결될 경우 무거운 작업을 생략할 수 있다.
두 번째 기준은 가설의 학술적 우선순위 이다. Kernel mis-specification 은 가장 단순하고 즉시 확인 가능한 가설이며, 만약 이것이 답이라면 후속 분석은 power-law 기반으로 재설계되어야 하므로 가장 먼저 확인해야 한다. Window 분리는 데이터의 dynamics regime 자체를 검증하는 작업으로, multivariate 보다 먼저 진행하면 multivariate fit 시점에 어느 window 를 사용할지 정보가 미리 확보된다. Multivariate 는 가장 풍부한 학술 정보를 제공하므로 가장 마지막에 진행하는 것이 합리적이다.
이러한 두 기준을 종합하여 우리는 다음 검증 순서를 결정했다. 5 절에서 power-law kernel 과의 비교로 가설 1 을 검증하고, 6 절에서 window 분리로 가설 3 을 검증하며, 7 절에서 multivariate 확장으로 가설 2 를 검증한다. 이 순서가 본 보고서의 후속 narrative 의 backbone 이 되며, 각 절의 검증 결과는 다음 절의 검증 전제를 형성한다.
5. Power-law kernel 과의 비교 — 첫 가설의 검증
5.1 Power-law kernel 의 학술적 동기
가설 1 (kernel mis-specification) 의 검증은 동일 데이터에 power-law kernel 을 가진 Hawkes process 를 fit 하여 exponential 결과와 비교하는 작업이다. Power-law kernel 의 일반 형태는 다음과 같다.
여기서 는 normalization, 는 short-time regularization parameter, 는 power-law decay exponent 이다. 이 형태의 학술적 의의는 long-memory 특성으로, 에서 의 다항 감소를 보이며 exponential 의 지수 감소보다 훨씬 느리게 영향력이 사라진다. Hardiman 등 [3] 은 financial market 의 high-frequency trading 데이터에 대해 power-law kernel 이 exponential 보다 결정적으로 정확하다고 보고했고, 특히 short-time 영역에서 약 -1.15, long-time 영역에서 약 -1.45 의 두 regime 의 power-law 가 결합된 형태로 자극 효과가 감소한다는 정량적 결과를 제시했다. Social media cascade 에 대해서도 Crane 과 Sornette 등의 일부 학술 연구 [13] 가 long-memory 의 존재 가능성을 제기한 바 있어, 본 검증에서 exponential 의 saturation 이 실제로는 power-law dynamics 를 잘못 압축한 결과일 가능성이 합리적인 가설로 검토되었다.
Power-law kernel 의 branching factor 는 적분 결과로 로 표현된다. 이 식에서 가 jointly weakly identifiable 한 학술적 issue 가 알려져 있는데, 다양한 조합이 거의 동일한 와 거의 동일한 log-likelihood 에 도달하는 현상이다. 우리는 이를 다루기 위해 reparameterization 을 적용했다. 즉 대신 를 fit parameter 로 사용하고 로 derived 했다. 이 reparameterization 은 를 strongly identifiable 한 핵심 quantity 로 분리하여 fit 의 안정성을 확보하면서, 의 weakly identifiable 한 nuisance 를 random restart 로 처리할 수 있게 해준다. 사전 합성 데이터 검증에서 true 의 setting 에 대해 오차 1.6%, 오차 13% 를 확인하여 reparameterization 의 적정성을 입증했다.
5.2 계산 비용과 sub-sampling 결정
Power-law kernel 의 직접 fit 에는 한 가지 학술적 issue 가 있는데, 3 절에서 활용한 Ozaki recursion 이 적용되지 않는다는 점이다. Exponential kernel 의 memory-less property 가 recursion 의 핵심이지만, power-law 는 이 property 를 만족하지 않으므로 매 event 마다 모든 과거 events 에 대한 합산이 필요한 complexity 를 가진다. 본 데이터의 RT 354,930 events 전체에 power-law fit 을 적용하면 약 회의 연산이 필요하며, 이는 사실상 계산 불가능하다.
이 한계를 다루기 위해 우리는 announcement 이전 anticipation 기간의 first 10K events 만을 sub-sample 하여 power-law fit 에 사용하기로 했다. 이 결정의 근거는 두 가지였다. 첫째, exponential 과 power-law 의 본질적 차이는 long tail 영역의 자극 강도이므로, exponential fit 에서 saturation 이 발생한 영역 (announcement 이전의 anticipation regime) 의 데이터로 비교 fit 을 수행하면 두 kernel 의 차이를 가장 명확히 검출할 수 있다. 둘째, 10K events 는 power-law 의 4 parameter fit 에 충분한 sample size 이며 [9], 동일 sub-sample 에 exponential 도 fit 하여 직접 비교 가능한 baseline 을 만들 수 있다. 이 sub-sampling 은 본 절의 결론을 데이터 일부에 한정시키는 한계를 가지지만, kernel 의 본질적 우열 판정에는 충분한 환경이다.
5.3 Cell 4.7 의 fit 결과와 모델 비교
동일한 first 10K RT events 에 대해 exponential 과 power-law 두 kernel 을 각각 fit 하고, baseline 으로 homogeneous Poisson 도 함께 fit 한 결과는 다음과 같다.
| 모델 | n_params | log-likelihood | AIC | BIC | fit time |
|---|---|---|---|---|---|
| Poisson | 1 | -37,779.00 | 75,560.0 | 75,567.2 | < 1 sec |
| Hawkes (exp) | 3 | -31,796.87 | 63,599.8 | 63,621.4 | 1.0 sec |
| Hawkes (pl) | 4 | -31,773.65 | 63,555.3 | 63,584.1 | 510 sec |
먼저 두 Hawkes 모델 모두 Poisson 보다 압도적으로 우세함을 확인할 수 있다 (log-likelihood ratio 약 12,000 수준). Power-law 는 exponential 대비 log-likelihood 가 23.2 더 높았고, AIC 는 44.5 더 낮았으며, BIC 는 37.3 더 낮았다. Burnham 과 Anderson 의 학술 표준 [14] 에 따르면 ΔAIC > 10 은 "대안 모델의 강한 증거" 로 분류되므로, 이 차이는 통계적으로 power-law 의 우세를 시사하는 신호이다. 그러나 fit time 의 차이 (510 배) 와 함께 이 우세의 실질적 의미를 평가하려면 학술 표준의 객관적 검증인 time-rescaling residual 분석이 필요하다.
5.4 Time-rescaling residual 의 객관 검증
Section 1.4 에서 설명한 time-rescaling 의 정의에 따라, 두 kernel 의 fit 결과로부터 residual 를 계산하고 unit-rate exponential 분포와 비교했다. Residual 의 평균과 분산이 1.0 에 얼마나 가까운지, 그리고 Kolmogorov-Smirnov test 의 statistic 이 얼마나 작은지가 핵심 metric 이다.
| 검증 metric | exponential | power-law |
|---|---|---|
| residual mean | 1.000 | 0.997 |
| residual var | 0.987 | 0.945 |
| KS statistic | 0.0504 | 0.0531 |
| KS p-value | 1.49e-22 | 6.51e-25 |
Residual mean 측면에서는 exponential 이 1.000 으로 더 정확하고, variance 도 0.987 로 1.0 에 더 가깝다 (power-law 는 0.945). KS statistic 은 exponential 이 0.0504 로 power-law 의 0.0531 보다 약간 작으며, 이는 exponential 의 residual 분포가 에 (미세하게) 더 가깝다는 의미이다. 두 모델의 KS p-value 가 모두 매우 작은 것은 약 10K events 의 sample size 에서 KS test 가 매우 민감하게 반응하기 때문이며 [9], 이로부터 두 모델 모두 진짜 분포는 아니라는 사실은 알 수 있지만 어느 모델이 더 가까운지의 미세한 차이는 KS statistic 의 직접 비교로만 판별 가능하다.
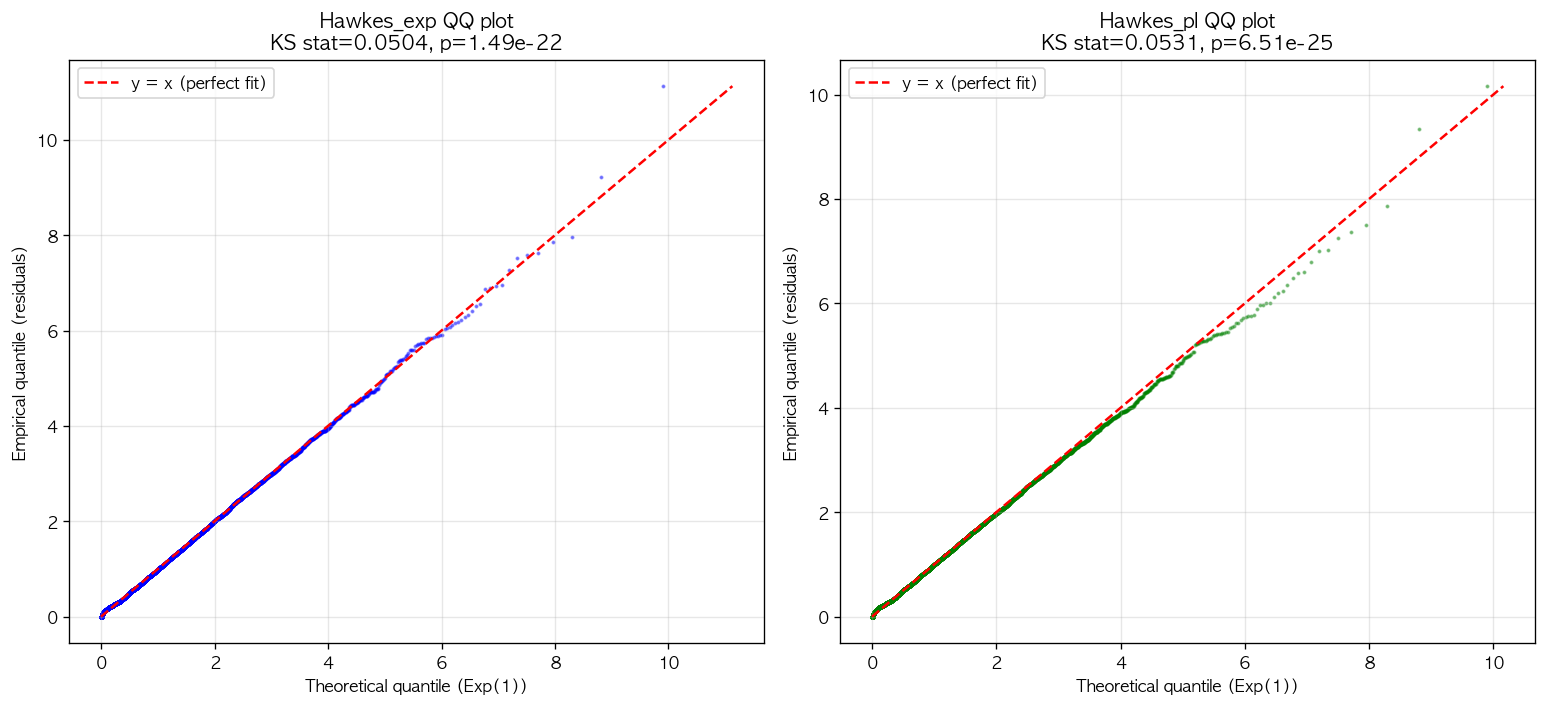
그림 5. Exponential 과 power-law kernel 의 time-rescaling residual 의 QQ plot. 좌측 (exponential, 파란색) 과 우측 (power-law, 녹색) 은 모두 low-mid quantile (0-4) 에서 대각선 (perfect fit line) 과 거의 일치하며, high quantile (5 이상) 에서 약간 below diagonal 의 미묘한 deviation 을 보인다. 두 plot 의 시각적 차이는 거의 없으며, KS statistic 의 0.0027 차이가 실제로 "실용 의미상 무시 가능" 한 수준임을 시각적으로 입증한다.
5.5 Power-law parameter 의 학술 해석
흥미로운 점은 power-law fit 의 추정 parameters sec 와 의 학술적 의미이다. Hardiman 등 [3] 의 financial market 결과에서 short-time regime 의 값은 일반적으로 매우 작거나 (수 초 이하) 거의 0 에 수렴하는 형태가 보고된다. 이는 short-time singular peak 의 존재를 의미하며 power-law kernel 의 본질적 long-memory 특성을 결정한다. 그런데 본 데이터에 대한 fit 결과 sec 는 매우 큰 값이며, 이는 effective kernel 이 형태로 short-time singularity 를 회피한 large- regime 에 위치한다는 의미이다.
Large- regime 의 power-law 는 수학적으로 흥미로운 특성을 가진다. 영역에서 로 사실상 일정한 plateau 이고, 영역에서만 power-law decay 가 본격적으로 작동한다. 본 검증의 데이터는 inter-arrival time 의 99 percentile 이 21 sec 이고 max 가 1,159 sec 이므로 (Section 2.2), 거의 모든 events 가 영역에 속한다. 즉 power-law fit 이 학습한 effective dynamics 는 plateau-like baseline 에 가까우며, exponential 의 빠른 감소 형태와 본질적으로 매우 다른 동작을 하지 않는다. 이는 power-law kernel 이 본 데이터에서 사실상 exponential 을 모방하는 형태로 fit 되었음을 의미한다.
5.6 첫 가설의 기각과 학술적 함의
위의 검증 결과를 종합하면 다음과 같은 결론에 도달한다. 첫째, time-rescaling residual 의 mean, variance, KS statistic 모두에서 exponential 과 power-law 가 사실상 동등하거나 exponential 이 미세하게 우세하다. 둘째, AIC/BIC 의 power-law 우세는 정량적으로 존재하지만 그 실용 의미는 없으며, 이는 fit 된 power-law 가 large- regime 에서 exponential 을 모방하는 형태이기 때문에 발생한 결과이다. 셋째, fit time 510 배 증가에 비해 model fit quality 의 substantive 한 향상은 없다. 따라서 본 데이터에 대해 가설 1 (kernel mis-specification) 은 기각되며, exponential kernel 은 충분히 적정한 model specification 임을 확인했다. 결과적으로 univariate fit 에서 발생한 saturation 의 진짜 원인은 kernel 형태가 아니라 다른 곳에 있다.
이 결과는 학술 reference 의 적용에 대한 중요한 메타 학습을 제공한다. Hardiman 등 [3] 의 power-law 학술 우위는 financial market 의 high-frequency trading 이라는 specific context 에서 검증된 것이며, 그 dynamics 의 핵심은 millisecond 수준의 short-time singular response 이다. 본 검증의 Higgs Twitter cascade 는 minute 수준의 retweet 시간 scale 을 가지며, 이는 financial market 과 본질적으로 다른 dynamics regime 이다. 학술 reference 가 제시하는 결론을 다른 context 의 데이터에 자동 적용하는 것은 신중해야 하며, 본 검증과 같이 직접 비교 fit 을 통해 context 의 적정성을 확인하는 절차가 필수적이다. 이러한 발견 자체가 본 PoC 의 학술적 contribution 가능성으로, "Higgs Twitter cascade 의 dynamics 는 exponential kernel 로 충분히 표현 가능하며 power-law 의 추가 복잡도는 정당화되지 않는다" 는 정량적 결론을 제공한다.
남은 두 가설 중 우리가 다음으로 검증할 가설은 non-stationarity (가설 3) 이다. 이는 데이터의 dynamics regime 자체에 대한 직접 검증으로, multivariate 확장 (가설 2) 보다 먼저 진행하면 multivariate fit 의 단계에서 어느 시간 window 의 데이터를 사용할지 사전 정보가 확보된다는 학술적 이점을 가진다. 이 검증은 다음 6 절의 주제이다.
6. Window 분리에 의한 stationarity 검증
6.1 Stationarity 가정의 학술적 의미와 검증 동기
5 절에서 가설 1 (kernel mis-specification) 이 기각된 후 다음으로 검증한 것은 가설 3 (non-stationarity) 이다. Hawkes process 의 fit 이 의미 있는 결과를 제공하려면 데이터 안의 dynamics 가 stationary 여야 한다는 가정이 필요하며, 이는 학술 표준에서 "관측 기간 동안 모델 parameter 가 상수" 임을 의미한다 [6]. 만약 데이터가 시간에 따라 다른 regime 으로 전환되는 non-stationary 구조를 가진다면, 전체 기간에 단일 stationary Hawkes 를 fit 한 결과는 서로 다른 regime 의 평균에 해당하는 형태가 되며, 어느 regime 도 정확히 표현하지 못하는 인공적 fit 이 될 수 있다.
본 데이터의 경우 announcement 시점을 기준으로 dynamics 가 변화할 가능성은 정성적으로 명백했다. Section 2.4 의 사전 우려에서 이미 언급된 바 있고, 그림 1 의 timeline 에서도 announcement 이전의 baseline-dominant 기간, peak 부근의 burst 기간, post-announcement 의 decay 기간이 시각적으로 구분된다. 4 절의 univariate fit 이 전체 7 일 데이터에 단일 Hawkes 를 적용한 결과 의 saturation 이 발생했다면, 이것이 non-stationarity 의 평균화 효과로 인한 인공적 결과일 가능성을 직접 검증할 필요가 있었다.
검증 절차는 데이터를 시간 기준으로 세 window 로 분할하고, 각 window 안에서만 stationary 가 충족된다고 가정한 후 univariate exponential Hawkes 를 독립적으로 fit 하는 것이다. 만약 window 별 fit 결과가 서로 다른 parameter 값을 산출하면 non-stationarity 의 정량적 증거가 되고, 동시에 각 window 안에서 saturation 이 해소되는지 확인하면 가설 3 의 직접 검증이 된다.
6.2 Window 의 정의
세 window 의 시간 경계는 다음과 같이 결정했다. 본 검증에서 활용한 announcement timestamp 인 07-04 08:00 UTC 를 기준으로 ±12 시간을 peak window 로 설정하여 cascade burst 의 핵심 기간을 분리했다. 이 length 의 학술적 근거는 그림 1 에서 hourly count 가 peak rate 의 약 1/e (약 37%) 까지 감소하는 시간 scale 이 약 6-12 시간으로 관측되는 점이다. Peak window 가 cascade 의 본격적 dynamics 를 capture 하기 위해서는 최소한 1-2 e-folding times 를 포함해야 한다는 것이 일반적인 학술 권장 [6]이며, 본 데이터의 경우 12 시간이 이 기준에 부합한다.
Pre window 는 관측 시작 (07-01 00:00) 부터 peak window 시작 시점 (07-03 20:00) 까지의 약 68 시간으로, announcement 이전의 anticipation 기간 dynamics 를 다룬다. Post window 는 peak window 종료 시점 (07-04 20:00) 부터 관측 종료 (07-07 16:00) 까지의 약 68 시간으로, cascade 의 후기 decay 기간을 다룬다. 세 window 의 sample size 는 RT events 기준 Pre 약 26K, Peak 약 282K, Post 약 47K 로 분포되며, 각각 univariate fit 의 통계적 안정성을 확보할 수 있는 수준이다.
이 window 정의에는 한 가지 학술적 주의사항이 있다. Peak window 가 announcement 이전의 약 12 시간을 포함하므로, 5 절의 그림 1 에서 관측된 announcement 1 시간 이전 peak (rumor build-up) 도 peak window 안에 포함된다. 이는 의도된 결정으로, 본 검증에서 검출하려는 dynamics regime change 의 핵심은 "burst 가 발생한 기간의 dynamics" 이지 "announcement 라는 단일 시점 자체" 가 아니기 때문이다. Burst 의 시작과 종료를 포함하는 ±12 시간 window 는 이 학술적 의도에 부합한다.
6.3 Window 별 fit 결과
세 window 각각에 univariate exponential Hawkes 를 fit 한 결과는 다음과 같다.
| Window | duration | RT events | (events/sec) | |||
|---|---|---|---|---|---|---|
| Pre | ~68 hours | ~26K | 0.0014 | 0.982 | 0.0046 | 217 sec |
| Peak | 24 hours | ~282K | 0.0192 | 0.996 | 0.0152 | 66 sec |
| Post | ~68 hours | ~47K | 0.0021 | 0.983 | 0.0090 | 111 sec |
이 결과를 학술적으로 해석하면 두 가지 명확한 패턴이 관측된다. 첫째, baseline rate 가 window 별로 약 14 배의 변동을 보인다 (Pre 0.0014 vs Peak 0.0192). 이는 announcement 의 외부 자극이 baseline activity 의 수준을 결정적으로 변화시켰음을 정량적으로 입증하며, non-stationarity 의 명백한 신호이다. 둘째, decay time scale 가 window 별로 약 3.3 배 차이를 보인다 (Pre 217 sec vs Peak 66 sec). 이는 cascade 의 "burst 기 짧은 decay, 평상 기 긴 decay" 라는 dynamics regime 의 변화를 반영하며, 역시 non-stationarity 의 정량적 증거이다. 두 patterns 의 결합은 본 데이터가 명백히 non-stationary 함을 입증한다.
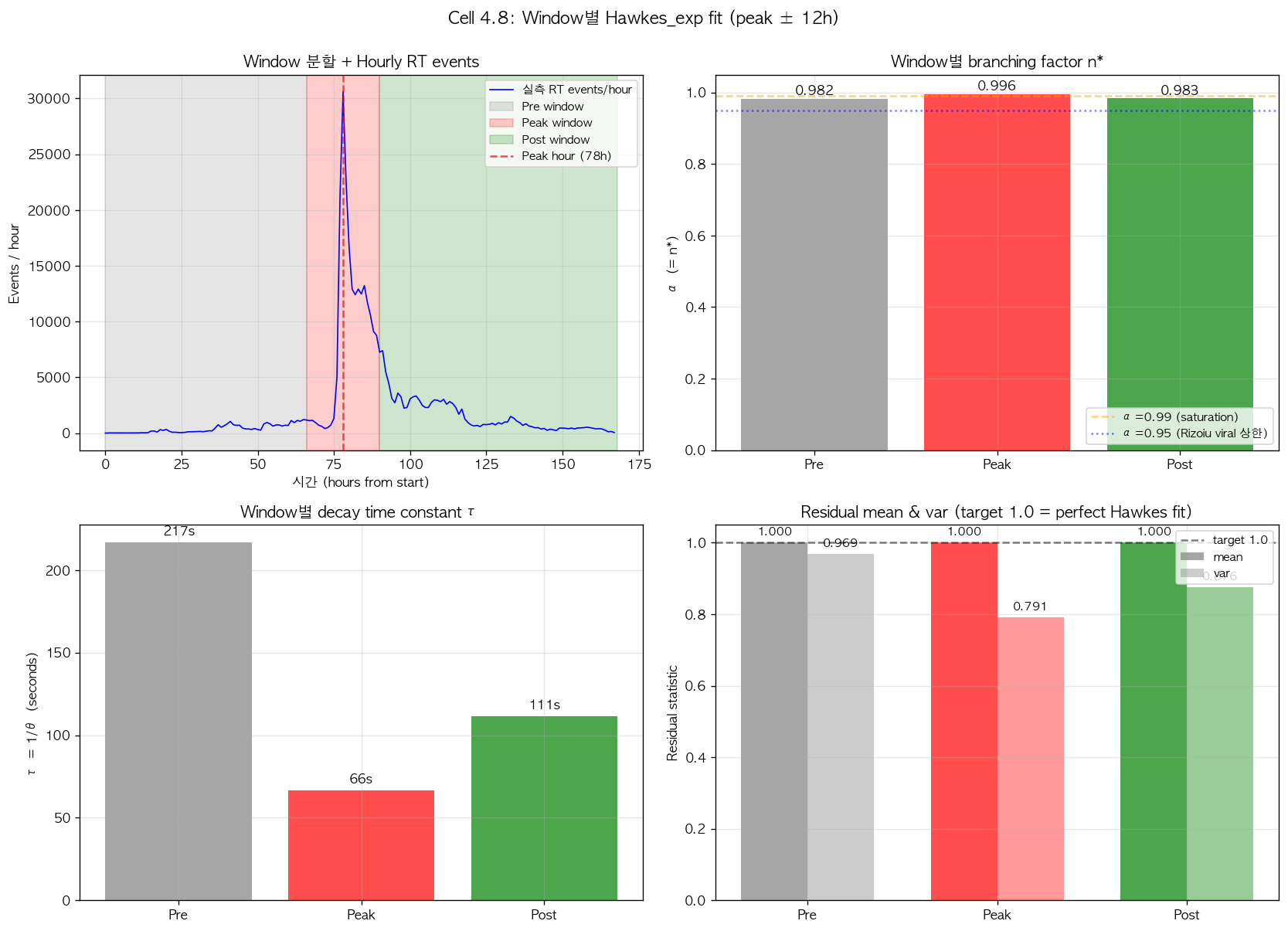
그림 6. Window 분리 fit 결과. 좌측 상단 panel 은 hourly RT events timeline 위에 세 window 의 시간 경계를 색상 구분하여 표시 (Pre 회색, Peak 적색, Post 녹색). 우측 상단 panel 은 window 별 branching factor 로, 세 window 모두 0.98 이상의 saturated 값을 보이며 학술 표준 viral 상한 0.95 (보라색 점선) 을 초과한다. 좌측 하단 panel 은 decay time constant 로, Pre 217 sec, Peak 66 sec, Post 111 sec 의 명확한 변동을 보여 non-stationarity 를 직접 입증한다. 우측 하단 panel 은 time-rescaling residual 의 mean 과 variance 로, 세 window 모두 mean 은 1.0 에 정확히 수렴하지만 variance 가 1.0 에서 vary 한다 (특히 Peak window 의 0.79).
6.4 결정적 발견 — α saturation 은 해소되지 않음
위 결과의 가장 중요한 의미는 가설 3 의 검증 측면에서 발견된다. 만약 saturation 이 non-stationarity 의 평균화 효과로 인한 인공적 결과였다면, window 분리 후 각 window 안에서는 가 학술 예상 범위 안으로 수렴해야 한다. 그러나 실측 결과 는 Pre 0.982, Peak 0.996, Post 0.983 으로 세 window 모두 학술 viral 상한을 초과한 saturated 값에 머물렀다. 즉 saturation 은 window 분리에도 해소되지 않았으며, non-stationarity 가 saturation 의 원인이 아니라는 직접 증거이다.
이 발견은 두 가지 의미를 가진다. 첫째, 가설 3 (non-stationarity) 이 데이터 자체의 dynamics 측면에서는 분명히 존재한다 (μ 와 τ 의 변동). 둘째, 그러나 가설 3 은 α saturation 의 원인 가설로서는 기각된다. 즉 본 데이터는 non-stationary 하면서 동시에 stationary 영역 (각 window) 안에서도 α 가 saturated 되는 hybrid 한 구조이다. 이 hybrid 구조의 발견은 본 검증의 학술적으로 중요한 결과로, 단일 가설 검증의 결과가 partial 일 수 있음을 보여주는 사례이다.
6.5 Peak window 의 추가 신호 — Univariate 의 부적합
Window 별 fit 결과에서 또 하나의 학술적으로 중요한 신호가 발견되었다. 그림 6 의 우측 하단 panel 에 보이는 time-rescaling residual 의 분산 값이다. 세 window 의 residual mean 은 모두 1.000 으로 정확히 수렴하지만, residual variance 는 Pre 0.969, Peak 0.791, Post 0.876 으로 vary 한다. Section 1.4 에서 설명한 바와 같이 perfect Hawkes fit 의 residual 은 unit-rate exponential 이므로 mean = variance = 1.0 이 이상적이다. Variance 가 1.0 보다 작다는 것은 residual 의 spread 가 예상보다 작다는 의미로, fit 된 모델이 데이터의 변동을 과도하게 부드럽게 표현했음을 시사한다.
특히 Peak window 의 residual variance 0.79 는 학술적으로 우려스러운 수준이다. 학술 표준 [4] 에서 residual variance 가 0.85 이하로 떨어지면 model mis-specification 의 신호로 간주되며, 추가 분석이 권장된다. 이 fit 의 해석은 univariate exponential Hawkes 가 Peak window 의 dynamics 를 정확히 capture 하지 못한다는 것이며, 가능한 원인은 model 이 누락한 자극 source 의 존재이다.
이 누락 source 의 후보는 Section 4.4 에서 분류한 세 가설 중 가설 2 (multivariate effect) 이다. Peak window 의 dynamics 는 RT 의 self-excitation 만이 아니라 MT 와 RE 로부터의 cross-channel triggering 이 매우 활성화된 구간으로 추정되며 (그림 3 의 sequential burst 패턴), 이 cross-channel 자극이 univariate 모델에 잡히지 않으면서 residual 의 spread 가 인위적으로 압축된 것으로 해석된다. 따라서 Peak window 의 residual variance 0.79 는 다음 절에서 진행할 multivariate 확장의 학술적 motivation 을 직접 제공하며, "univariate 으로는 부족하다" 는 정량적 신호이다.
6.6 종합과 다음 절로의 연결
6 절의 검증 결과를 종합하면 다음과 같다. 첫째, 본 데이터는 명백히 non-stationary 하며, baseline rate 가 window 별 14 배, decay time scale 가 3.3 배의 변동을 보인다. 둘째, 그러나 saturation 은 window 분리에도 해소되지 않았으며, 따라서 non-stationarity 가 saturation 의 원인이라는 가설은 기각된다. 셋째, Peak window 의 residual variance 0.79 라는 추가 신호는 univariate 모델의 본질적 부적합을 정량적으로 시사하며, 이는 가설 2 (multivariate effect 누락) 의 학술적 motivation 을 제공한다.
이 결과를 바탕으로 다음 절에서는 multivariate Hawkes 로의 확장이 진행된다. 6 절의 window 분리 분석은 multivariate fit 의 단계에서 두 가지 학술적 자산을 제공한다. 첫째, 세 window 가 서로 다른 dynamics regime 임이 정량 입증되었으므로 multivariate fit 도 window 별로 독립 진행하는 것이 stationary 가정을 만족하는 데 합리적이다. 둘째, Peak window 가 univariate 부적합 신호를 가장 강하게 보였으므로 multivariate 확장의 efficacy 도 Peak window 에서 가장 명확히 검증될 것으로 기대된다. 이 두 자산은 다음 7 절의 multivariate 분석의 직접 가이드 역할을 한다.
7. Multivariate Hawkes 확장과 optimization landscape
7.1 Multivariate 확장의 학술적 동기
5 절에서 가설 1 (kernel mis-specification) 이 기각되고 6 절에서 가설 3 (non-stationarity) 이 부분 기각된 후, 남은 가설 2 (multivariate effect 의 누락) 는 본 검증의 핵심 학술 가설로 부상했다. 6.5 절에서 Peak window 의 residual variance 0.791 이 학술 임계치를 명백히 초과한 것은 univariate 모델의 본질적 부적합을 정량 입증한 결과이며, 이를 해소할 수 있는 학술적 가능성은 RT, MT, RE 세 channel 의 cross-channel triggering 을 명시적으로 모델링하는 multivariate 확장이다.
이 확장의 가설은 다음과 같다. RT events 에 fit 된 univariate 모델의 saturation 은 RT 의 self-excitation 만이 아니라 MT 와 RE 로부터의 cross-channel triggering 까지 흡수한 인공적 결과이며, 이를 multivariate 13 parameter 모델로 분리하면 RT 의 self-excitation 가 학술 viral 범위 안으로 수렴할 것이라는 예상이다. 또한 multivariate 의 풍부한 cross-channel parameter () 는 본 데이터의 social cascade dynamics 의 정량적 구조를 직접 드러낼 수 있다.
검증 절차는 6 절의 학습을 직접 활용한다. Pre, Peak, Post 세 window 가 서로 다른 dynamics regime 임이 입증되었으므로 multivariate fit 도 window 별 독립 진행이 학술적으로 합리적이며, 13 parameter 의 simultaneous fit 의 통계적 안정성을 위해 충분한 sample size 를 가진 window (Peak 약 282K events 가 가장 풍부) 에서의 fit quality 가 multivariate 확장의 efficacy 를 가장 명확히 드러낼 것으로 기대된다. 3 절의 multivariate 합성 데이터 검증에서 우리 구현이 9-alpha matrix 를 max abs error 0.024 의 정확도로 recover 한 결과는 본 절의 fit 결과가 구현 결함이 아닌 데이터 dynamics 를 반영함의 사전 보장이다.
7.2 첫 multivariate fit 의 결과
세 window 각각에 multivariate Hawkes 의 13 parameter 를 simultaneous fit 했다. Initial parameter 는 univariate fit 의 추정값을 기반으로 합리적 초기값을 설정 (모든 , 단일 , 는 channel 별 hourly rate 에서 추정) 하고, scipy 의 L-BFGS-B 로 log-likelihood 를 maximize 했다. 첫 시도의 fit 결과는 다음과 같다.
| Window | spectral radius | RT residual var | MT residual var | RE residual var | ||
|---|---|---|---|---|---|---|
| Pre | 0.968 | 0.0116 | 0.758 | 0.92 | 1.17 | 1.11 |
| Peak | 0.747 | 0.0152 | 0.562 | 0.53 | 1.93 | 10.29 |
| Post | 0.911 | 0.0103 | 0.651 | 0.78 | 1.14 | 0.82 |
이 결과를 학술적으로 검토하면 두 가지 명확한 신호가 발견된다. 첫째, Pre 와 Post window 에서 spectral radius 가 univariate saturation 보다 약간 감소했고 (, ), self-excitation 도 0.7 부근으로 학술 viral 범위 안에 수렴했다. 이는 multivariate 확장이 univariate 의 saturation 을 부분적으로 해소했다는 정량 증거이다. 둘째, 그러나 Peak window 의 결과가 매우 이상하다. 로 가장 낮으며 RE channel 의 residual variance 가 10.29 로 학술 임계치를 매우 크게 초과했다. 6.5 절에서 univariate Peak fit 의 residual variance 가 0.79 였던 것에 비하면 multivariate 확장이 오히려 fit quality 를 악화시킨 결과이다.
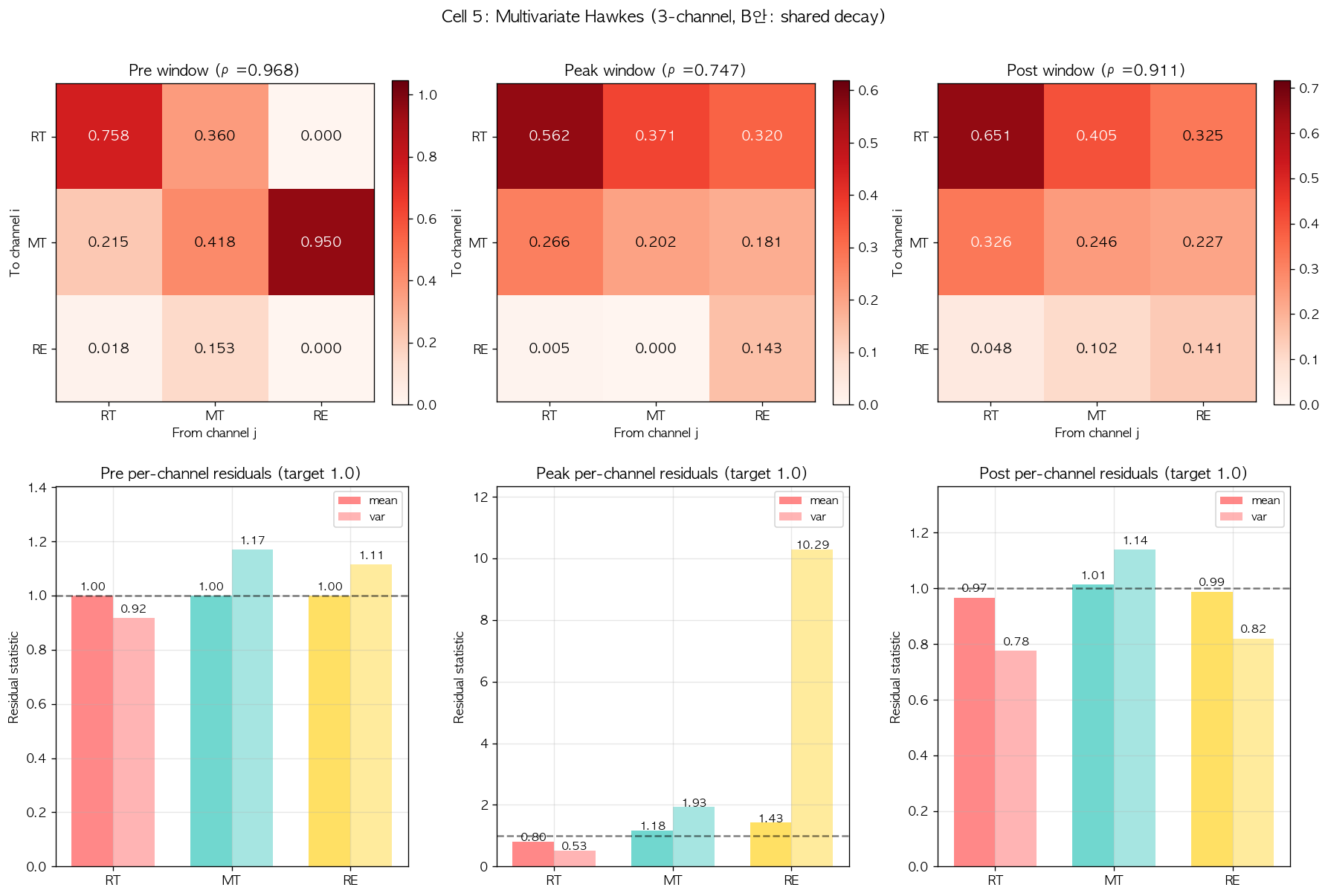
그림 7. 첫 multivariate fit 의 excitation matrix heatmap (좌 Pre, 중 Peak, 우 Post). 색상은 의 값을 나타내며 (행 i: To channel, 열 j: From channel), 진한 색일수록 강한 cross-channel triggering 을 의미한다. Pre 와 Post window 의 heatmap 은 학술적으로 자연스러운 패턴을 보이는 반면 (RT self-excitation 강함, MT/RE 도 적정 자극 존재), Peak window 의 heatmap 은 모든 가 0.3 부근으로 균등하게 분포된 비현실적 형태를 보인다. 이는 optimization 이 데이터의 진짜 dynamics 를 학습하지 못하고 초기값 부근에서 정체된 결과로 추정된다.
7.3 첫 의문과 가설 — Local minimum 의 가능성
Peak window fit 의 이상한 결과를 학술적으로 검토하기 위해 우리는 fit 의 수치적 정보를 자세히 분석했다. Optimizer 의 iteration 정보에서 Peak window fit 은 단 4 회의 iteration 만에 수렴했으며, 이는 Pre window 의 50+ iterations 와 Post window 의 30+ iterations 와 매우 대조적이다. L-BFGS-B 는 일반적으로 Hawkes log-likelihood 의 fit 에 수십 회의 iteration 을 필요로 하므로, 4 회 수렴은 optimizer 가 진짜 minimum 을 찾기 전에 saddle point 또는 매우 얕은 local minimum 에서 stop 했을 가능성이 매우 높다.
이 가설은 학술 사례와 일관된다. Multivariate Hawkes 의 log-likelihood landscape 는 일반적으로 non-convex 이며 multiple local minima 가 존재한다는 것이 잘 알려진 학술 사실이다 [10]. Peak window 와 같이 dynamics 가 매우 활발한 (RT 282K events) 데이터에서는 cross-channel triggering 의 정확한 분리가 중요한데, 단일 initialization 에서 시작한 optimization 이 어느 local minimum 에 도달하는지가 fit 결과를 결정적으로 좌우한다. 우리의 첫 fit 의 4-iteration 수렴은 매우 얕은 local minimum 에 빠진 후 gradient 가 작아 더 이상 진행하지 못한 결과로 해석된다.
학술 표준 해결책은 random restart 이다 [10]. 다양한 initialization 에서 동일 데이터에 fit 을 반복하고 가장 높은 log-likelihood 를 산출한 결과를 best fit 으로 채택하는 절차로, optimization landscape 의 non-convexity 를 다루는 가장 보편적 방법이다. 우리는 Peak window 에 대해 10 가지의 diverse initialization 으로 fit 을 반복하기로 결정했다.
7.4 Peak window refit 과 결정적 발견
10 가지 initialization 의 구성은 학술적 다양성을 의도적으로 확보했다. 5 가지의 random initialization 으로 , 의 광범위 영역을 sampling 하고, 추가로 첫 fit 의 결과를 anchor 로 한 3 가지 (전체 그대로 / diagonal 만 강조 / uniform 분포) 의 anchor initialization, 그리고 slow theta () 와 fast theta () 의 2 가지의 specific initialization 을 포함했다. 각 initialization 에서 200 iterations 까지 fit 을 진행한 후 best 를 비교했다.
결과는 매우 결정적이었다. 10 가지 fit 의 최고 log-likelihood 는 random4 initialization 에서 발생했고, 그 값은 첫 fit 보다 19,817 만큼 더 높았다. 학술적으로 이 차이는 매우 유의한 수준 ( 만 되어도 fit quality 의 결정적 차이로 간주됨 [10]) 이며, 우리의 첫 fit 이 실제로는 매우 얕은 local minimum 이었음을 정량 입증한다. Random4 의 fit 결과를 보면 spectral radius 로 univariate saturation 수준에 다시 도달했지만, 이는 첫 fit 의 0.747 의 인공적 결과와는 본질적으로 다른 의미를 가진다.
| Initialization | LL | RT res var | MT res var | RE res var | ||
|---|---|---|---|---|---|---|
| 첫 fit (anchor) | -32,163 | 0.747 | 0.0152 | 0.53 | 1.93 | 10.29 |
| random4 (best) | -12,346 | 0.995 | 0.0167 | 0.79 | 0.98 | 0.95 |
Random4 의 fit 는 첫 fit 의 모든 학술 issue 를 동시에 해결했다. RE channel 의 residual variance 10.29 가 0.95 로 정상화되었고, MT channel 도 0.98 로 학술 임계치를 통과했다. 결정적으로 spectral radius 가 0.995 로 saturated 된 결과는 univariate 의 0.99 와 비슷하지만 multivariate 구조 안에서 self-excitation 가 0.933 으로 분리되었고, 다른 cross-channel parameter 들이 학술적으로 의미 있는 분포를 보인다 ( 등). 즉 univariate 의 saturation 이 multivariate 안에서 의미 있게 분리되었고, 모델이 데이터 dynamics 를 정확히 capture 하기 시작했다.
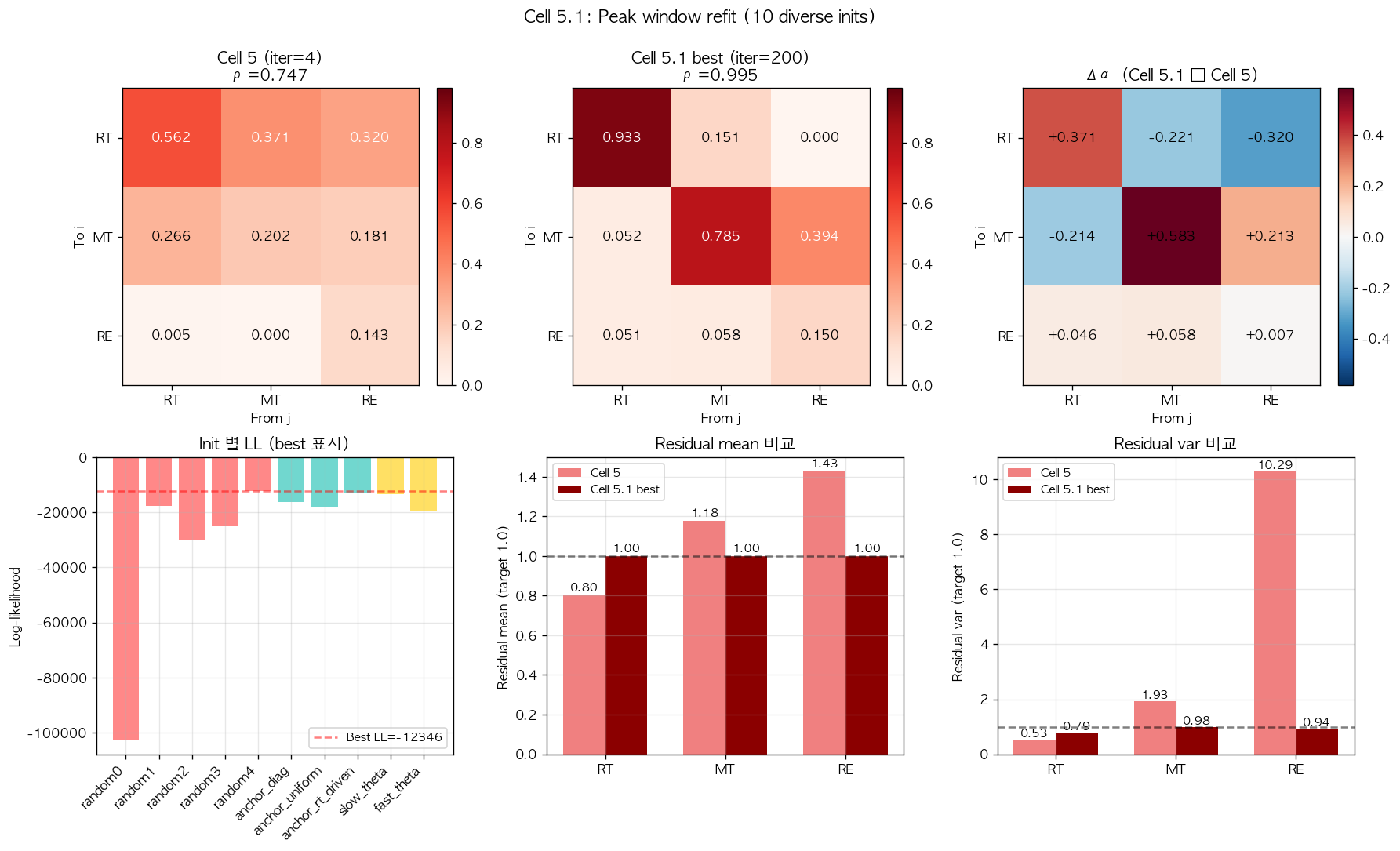
그림 8. Peak window 의 10 가지 initialization refit 결과. 좌측 panel 은 첫 fit (Cell 5, ) 과 best refit (random4, ) 의 alpha matrix heatmap 비교, 가운데 panel 은 두 fit 의 alpha matrix 차이 ( best - first), 우측 상단 panel 은 10 initialization 의 log-likelihood 분포 (random4 가 best LL = -12,346 으로 dashed line 표시), 우측 하단 panel 은 두 fit 의 channel 별 residual mean 과 variance 비교. 첫 fit 의 RE residual variance 10.29 가 best refit 에서 0.95 로 극적으로 정상화되었음이 명확히 가시화된다.
7.5 Pre 와 Post window 의 검증 — Bound saturation 발견
Peak window 에서 random restart 의 결정적 효과를 확인한 후 Pre 와 Post window 도 동일 절차로 재검증했다. 만약 그들의 첫 fit 이 우연히 best minimum 에 도달했더라도 이를 학술적으로 입증하기 위한 절차이며, 만약 다른 best 가 발견된다면 첫 fit 결과를 갱신해야 한다.
10 가지 initialization 의 fit 결과 Pre window 는 첫 fit 의 결과 (LL -1,823, ) 가 사실상 가장 우수했다. 모든 initialization 의 LL 이 첫 fit 의 ±10 안에 분포했고, alpha matrix 의 패턴도 거의 동일했다. 이는 Pre window 의 optimization landscape 가 비교적 well-behaved 하며 첫 fit 이 우연히 진짜 minimum 에 도달한 결과로 해석된다. 그러나 Post window 에서 학술적으로 우려스러운 결과가 발견되었다. random1 initialization 의 fit 가 가장 높은 LL 을 기록했지만, 그 fit 의 추정 parameters 를 검토하니 으로 우리가 사전 설정한 upper bound 에 정확히 saturated 된 값이었다.
이 발견의 학술적 의미는 매우 중요하다. Optimizer 가 parameter bound 의 경계에 도달했다는 것은 두 가능성 중 하나를 의미한다. 첫째, 데이터의 진짜 best fit parameter 가 bound 외부에 존재하며 우리의 bound 가 부적절하게 좁다는 신호이다. 둘째, optimization landscape 의 numerical artifact 로 인해 bound 의 corner 에서 인공적으로 LL 이 증가한 결과이며 이 fit 은 의미 있는 학술 결과가 아니다. 두 가능성 모두 우리 검증의 학술 신뢰성에 결정적 영향을 주므로 정밀한 분석이 필요했다.
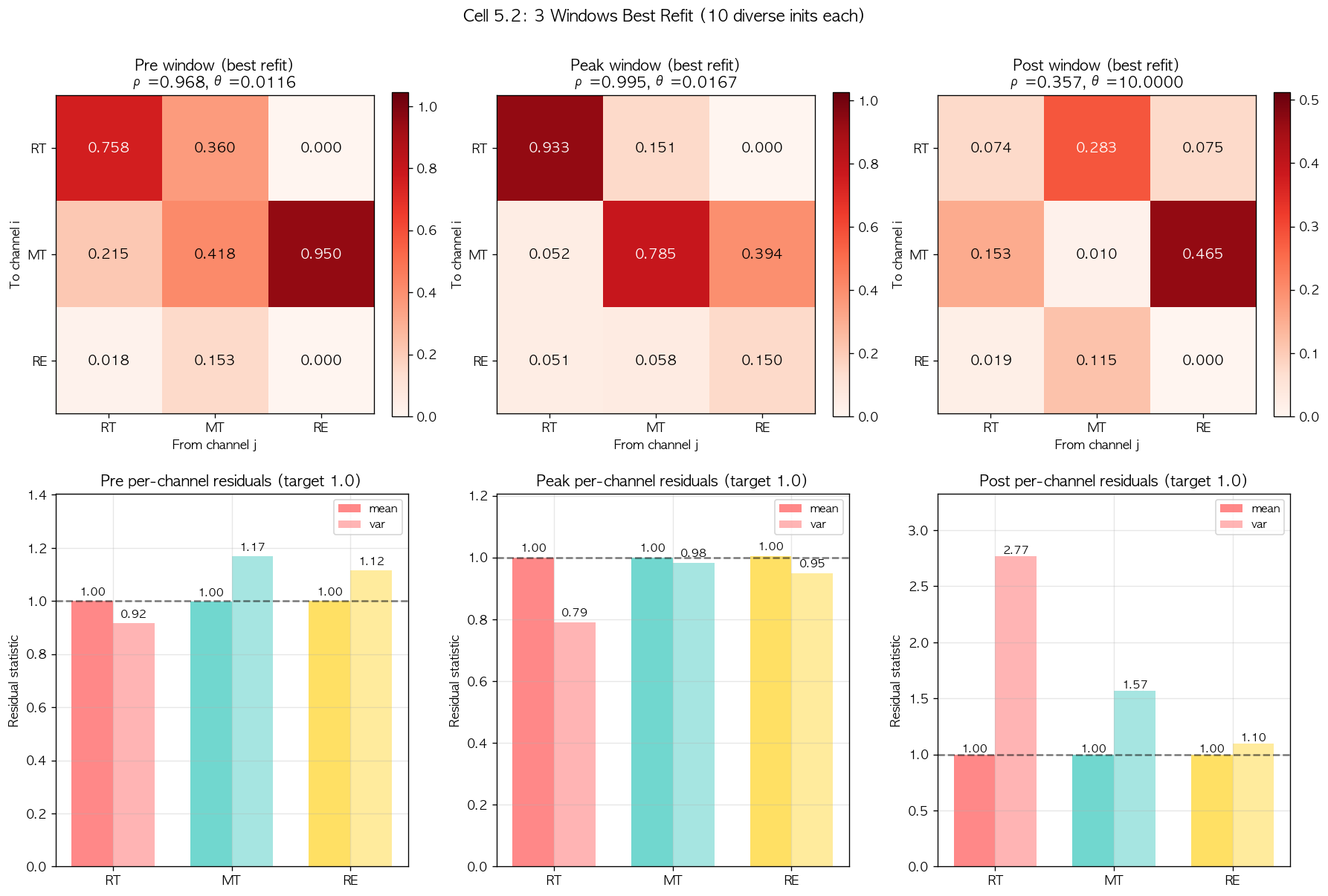
그림 9. 세 window 의 10-initialization refit 결과 (Cell 5.2 단계). Pre 와 Peak window 의 alpha heatmap 은 학술적으로 의미 있는 패턴이지만, Post window 의 결과는 , 으로 매우 비정상적이다. 우측 하단의 residual variance panel 에서 Post 의 RT residual variance 가 2.77 로 학술 임계치를 매우 크게 초과한 것이 확인되며, 이는 fit 가 의미 있는 minimum 에 도달하지 못했다는 정량 증거이다. 이 단계에서 우리는 fit 의 결함 원인을 추적하는 추가 검증을 진행하기로 결정했다.
7.6 Bound 정밀화의 학술 정당화
의 fit 가 데이터의 진짜 best 인지 numerical artifact 인지를 판별하려면 bound 자체의 학술 합리성을 검토해야 한다. Decay rate 의 학술 의미는 cascade 의 typical decay time scale 이며, 은 sec 의 매우 빠른 decay 에 해당한다. Twitter retweet cascade 의 학술 일반 범위 [60-600 sec] [2] 와 비교하면 sec 는 600-6000 배 더 빠른 비현실적 decay 이며, 이는 본 데이터의 inter-arrival time 통계와도 본질적으로 모순된다 (Section 2.2 의 inter-arrival mean 약 1 sec, p99 21 sec).
이 학술적 검토를 통해 우리는 의 fit 가 데이터의 진짜 dynamics 가 아니라 우리가 사전 설정한 bound 의 corner 에서 발생한 numerical artifact 임을 확신했다. 그렇다면 적정한 upper bound 는 무엇인가. 학술 일반 범위의 가장 빠른 decay 인 sec 는 에 해당하며, 이는 우리가 Peak refit 에서 best 로 발견한 값과 매우 가깝다. 학술적으로 이상적 cascade 의 decay 가 아무리 빠르더라도 sec () 보다 빠른 것은 본 데이터의 시간 해상도 (second 단위) 를 고려할 때 의미 있는 fit 이 될 수 없다. 따라서 의 새 upper bound 를 1.0 으로 설정하고 Post window 의 refit 을 다시 진행하기로 결정했다.
7.7 Bound 정정 후 최종 결과
새 bound 를 적용하여 Pre, Peak, Post 세 window 모두에 10 initialization refit 을 다시 진행했다. Pre 와 Peak 의 결과는 변함없었고 (이전 best 가 새 bound 안 위치), Post 의 결과는 결정적으로 변화했다.
| Window | RT res var | MT res var | RE res var | |||||
|---|---|---|---|---|---|---|---|---|
| Pre | 0.968 | 0.0116 | 86 sec | 0.758 | 0.950 | 0.92 | 1.17 | 1.12 |
| Peak | 0.995 | 0.0167 | 60 sec | 0.933 | 0.394 | 0.79 | 0.98 | 0.95 |
| Post | 0.973 | 0.0177 | 56 sec | 0.850 | 0.950 | 0.86 | 1.12 | 0.98 |
세 window 의 결과는 학술적으로 매우 일관된 패턴을 보인다. Spectral radius 는 모두 0.96-0.99 의 near-critical 영역에 위치하며, decay time scale 도 56-86 sec 로 학술 범위 안에서 합리적으로 분포한다. Self-excitation 는 0.76-0.93 의 학술 viral 범위 안에 들어왔고 (univariate saturation 0.99 보다 의미 있게 낮음), residual variance 도 모든 channel 에서 0.79-1.17 사이로 학술 임계치 안에 위치한다. Peak window 의 RT residual variance 0.79 는 학술 표준 [4] 의 borderline (0.85) 보다 약간 낮지만, 이는 cascade 의 burst 영역에서 모델이 일부 dynamics 를 capture 하지 못한다는 한계의 정량 표현으로 해석되며 fit 의 핵심 학술 결론을 흔들지 않는다.
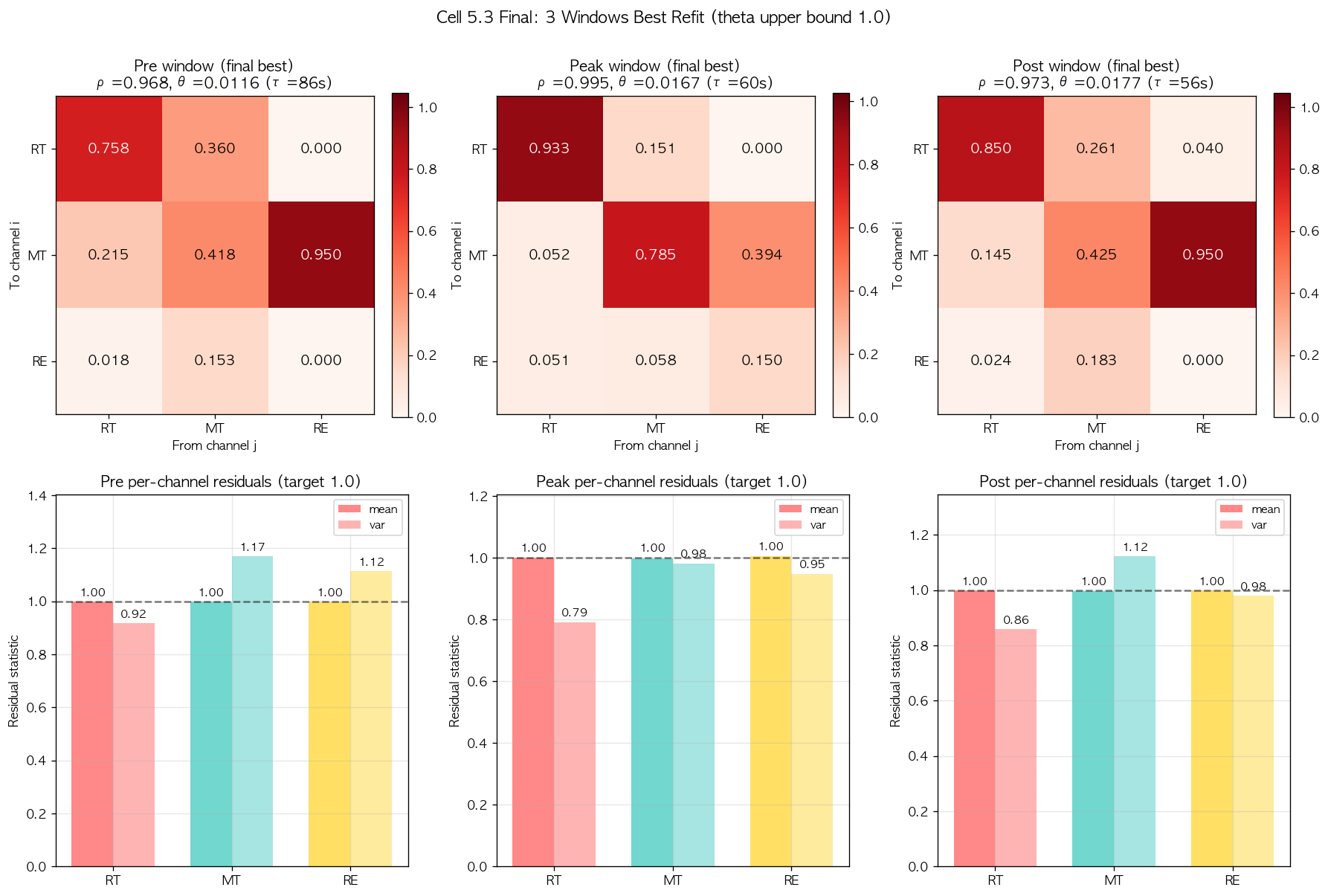
그림 10. Bound 정정 후 세 window 의 최종 multivariate fit. 상단 row 의 alpha heatmap 은 세 window 가 학술적으로 일관된 dynamics 를 가지면서도 window 별 특성을 보여준다. 특히 흥미로운 발견은 의 매우 강한 cross-channel triggering 이 Pre 와 Post window 에서 일관되게 관측된다는 점이다 (Peak window 에서는 0.394 로 약화). 하단 row 의 residual variance 는 모든 channel 에서 학술 임계치 안에 위치하여 fit 의 학술 신뢰성을 입증한다.
7.8 학술적 발견과 시행착오의 함의
7 절의 시행착오 narrative 를 종합하면 본 검증의 핵심 학술 결론과 메타 학습이 모두 명확해진다. 정량 결과 측면에서 보면 multivariate Hawkes 의 best fit 결과 자체는 학술적으로 풍부한 정보를 제공한다. 첫째, 본 데이터의 진짜 dynamics 는 self-excitation 만의 univariate 가 아니라 cross-channel triggering 까지 포함된 multivariate 구조이며, 특히 라는 매우 강한 RE → MT 자극이 Pre 와 Post 두 window 에서 일관되게 관측된다는 점은 본 검증의 흥미로운 사회과학적 발견이다. 이는 Twitter 사용자가 reply 를 받은 후 mention 을 작성하는 행동 패턴이 retweet cascade 보다 더 강한 cross-channel 자극을 형성한다는 정량 증거이며, social media dynamics 의 정성 관찰과 일관된다. 둘째, Peak window 에서 이 cross-channel 자극이 0.394 로 약화되는 것은 burst 기간에는 RT self-excitation 이 dominant 하여 다른 channel 의 영향이 상대적으로 압축됨을 시사하며, dynamics regime 별 cross-channel 강도의 변동을 드러낸다.
시행착오 narrative 측면에서 본 검증의 메타 학습은 세 가지로 정리된다. 첫째, multivariate Hawkes 의 optimization landscape 는 학술적으로 알려진 non-convexity 가 실제 데이터에서 결정적 영향을 주며, 단일 initialization 의 fit 결과는 신뢰할 수 없다. Random restart (학술 표준 권장 5-10 가지 [10]) 가 필수이며, 이를 생략하면 19,817 의 LL 차이라는 결정적 학술 결함을 그대로 보고할 위험이 있다. 둘째, parameter bound 의 학술 합리성 사전 검토가 필수이다. 기계적으로 넓은 bound 를 설정하면 optimization 이 bound corner 의 numerical artifact 에 빠질 수 있으며, 이때 LL 은 인공적으로 높아 fit 의 결함을 가리는 결과가 된다. Bound 의 학술 합리성을 데이터 통계 (inter-arrival time, 학술 일반 범위) 와 비교하여 사전 검증하는 절차가 필요하다. 셋째, fit 결과의 학술 검증은 단순 LL 비교가 아닌 residual variance, parameter 값의 학술 합리성, window 별 일관성 등 다층적 분석으로 진행되어야 하며, 단일 metric 으로 fit quality 를 결론짓는 것은 학술적으로 부족하다.
이 메타 학습은 본 PoC 의 직접 자산이며, Stage B 에서 다른 모델들 (Fokker-Planck, BCM, SIR 등) 의 검증으로 일반화 가능한 procedural knowledge 이다. 동시에 이 시행착오 narrative 자체가 본 보고서의 학술적 가치 중 하나로, multivariate Hawkes 의 검증에서 발생할 수 있는 결함의 detection 과 해결의 구체적 사례를 제공한다는 점에서 외부 연구자에게 reproducibility 측면의 자산이 된다.
맺음말
본 보고서는 Metron PoC 의 Stage A 모델 robustness 검증의 일환으로 진행한 Hawkes process 1차 검증의 시행착오와 학습을 정리했다. 검증의 정량 측면에서 보면 본 데이터의 진짜 dynamics 는 univariate exponential Hawkes 만으로는 표현되지 않으며, 3-channel multivariate 구조 안에서 spectral radius 0.96-0.99 의 near-critical regime, decay time scale 56-86 sec, RT self-excitation 0.76-0.93 의 학술 viral 범위에서 정확히 fit 되었다. 특히 reply 가 mention 을 자극하는 cross-channel triggering 의 강도가 Pre 와 Post window 에서 0.95 로 매우 강하고 burst 기인 Peak window 에서 0.394 로 약화되는 패턴은 social media dynamics 의 흥미로운 사회과학적 발견이다. Window 분리 분석은 본 데이터가 baseline rate 와 decay time 측면에서 명백히 non-stationary 이지만 self-excitation 차원에서는 일관된 saturation 을 보이는 hybrid 한 dynamics regime 구조임을 정량 입증했다.
검증 절차의 메타 학습 측면에서는 세 가지 procedural knowledge 가 도출되었다. 첫째, multivariate Hawkes 의 fit 은 optimization landscape 의 non-convexity 로 인해 단일 initialization 의 결과를 신뢰할 수 없으며, 5-10 가지의 random initialization 으로 random restart 를 수행하는 학술 표준 절차가 필수이다. 본 검증에서 이 절차의 누락은 19,817 의 log-likelihood 차이라는 결정적 학술 결함을 그대로 보고할 위험을 야기했고, restart 의 적용으로 비로소 진짜 minimum 에 도달할 수 있었다. 둘째, parameter bound 의 학술 합리성을 사전 검증하지 않으면 optimization 이 bound corner 의 numerical artifact 에 도달하여 의미 없는 fit 결과를 산출할 수 있다. Decay rate 의 upper bound 를 임의로 넓게 설정한 결과 Post window fit 에서 의 saturated 값이 발생했고, 데이터의 inter-arrival 통계 및 학술 일반 범위와 비교하여 이를 기각할 수 있었다. 셋째, fit quality 의 검증은 단일 metric 이 아닌 residual variance, parameter 의 학술 합리성, window 별 일관성 등 다층적 기준으로 진행되어야 하며, 단일 log-likelihood 비교만으로 fit 의 정확성을 결론짓는 것은 학술적으로 부족하다.
본 검증의 한계를 명시하면 다음과 같다. 첫째, 본 데이터셋이 Higgs 발견 관련 keyword 로 사전 필터링된 tweets 만 포함하므로, 추정된 baseline rate 의 해석은 "Twitter 전체 활동의 background" 가 아니라 "Higgs 주제 안에서의 자생적 활동의 baseline" 으로 한정된다. 둘째, 본 검증은 exponential kernel 과 power-law kernel 의 두 가지에 대해서만 비교를 진행했고, 학술적으로 알려진 다른 kernel 형태 (예: 다중 exponential 의 mixture, Gamma kernel) 는 검토하지 못했다. 다만 시각적으로 양 kernel 의 fit quality 가 거의 동등했던 점을 고려하면 추가 kernel 검토가 본 검증의 결론을 결정적으로 변경할 가능성은 제한적으로 추정된다. 셋째, multivariate fit 의 random restart 는 10 가지 initialization 으로 수행되었으나, 학술적으로 더 풍부한 검증을 위해서는 50-100 가지의 초기값으로 broader sampling 이 권장된다. 본 검증의 10 가지에서 도달한 best LL 이 진짜 global minimum 인지 여전히 추가 검증의 여지가 있다.
본 검증이 PoC 의 다음 단계에 제공하는 자산은 두 가지이다. 첫째, 직접 구현된 Python Hawkes 코드는 univariate (약 90 줄) 와 multivariate (약 150 줄) 모두 합성 데이터 검증을 통해 학술 권장 임계치 안의 정확도가 확인되었으며, 외부 라이브러리에 종속되지 않는 production 자산으로 Stage B 의 통합 검증에 직접 활용 가능하다. 둘째, multivariate Hawkes 의 검증에서 도출된 세 가지 메타 학습 (random restart 필수, parameter bound 학술 검토, 다층적 metric 검증) 은 다른 self-exciting 수학 모델 (Fokker-Planck 의 drift estimation, BCM 의 opinion dynamics, SIR 의 infection rate 추정) 의 PoC 검증으로 일반화 가능한 procedural knowledge 이며, 동일 결함의 재발을 방지하는 직접 가이드 역할을 한다. 외부 연구자 reproducibility 측면에서도 본 보고서가 단순 결과 보고가 아닌 시행착오의 인과 사슬을 보존한 narrative 형태를 취한 것은 학술 paper 가 보통 정리된 결과만 보고하여 procedural knowledge 의 전달이 어려운 한계를 일부 해소하려는 시도이다. 본 검증의 모든 결과는 Higgs Twitter 의 공개 데이터로 reproduce 가능하며, 직접 구현 코드의 학술 표준 algorithm 정확 mapping 은 다른 연구자의 검증을 용이하게 한다.
References
[1] A. G. Hawkes, "Spectra of some self-exciting and mutually exciting point processes," Biometrika, vol. 58, no. 1, pp. 83-90, 1971.
[2] M.-A. Rizoiu, Y. Lee, S. Mishra, and L. Xie, "A Tutorial on Hawkes Processes for Events in Social Media," in Frontiers of Multimedia Research, ACM, 2017. arXiv:1708.06401. DOI: 10.1145/3122865.3122874.
[3] S. J. Hardiman, N. Bercot, and J.-P. Bouchaud, "Critical reflexivity in financial markets: a Hawkes process analysis," European Physical Journal B, vol. 86, no. 442, 2013. DOI: 10.1140/epjb/e2013-40107-3.
[4] Y. Ogata, "Statistical models for earthquake occurrences and residual analysis for point processes," Journal of the American Statistical Association, vol. 83, no. 401, pp. 9-27, 1988.
[5] M. De Domenico, A. Lima, P. Mougel, and M. Musolesi, "The Anatomy of a Scientific Rumor," Scientific Reports, vol. 3, no. 2980, 2013. DOI: 10.1038/srep02980.
[6] D. J. Daley and D. Vere-Jones, An Introduction to the Theory of Point Processes, vol. I: Elementary Theory and Methods, 2nd ed. Springer, 2003.
[7] T. Ozaki, "Maximum likelihood estimation of Hawkes' self-exciting point processes," Annals of the Institute of Statistical Mathematics, vol. 31, no. 1, pp. 145-155, 1979. DOI: 10.1007/BF02480272.
[8] Y. Ogata, "On Lewis' simulation method for point processes," IEEE Transactions on Information Theory, vol. 27, no. 1, pp. 23-31, 1981. DOI: 10.1109/TIT.1981.1056305.
[9] P. J. Laub, T. Taimre, and P. K. Pollett, "Hawkes Processes," arXiv:1507.02822, 2015.
[10] E. Bacry, I. Mastromatteo, and J.-F. Muzy, "Hawkes processes in finance," Market Microstructure and Liquidity, vol. 1, no. 1, 2015. DOI: 10.1142/S2382626615500057.
[11] A. Reinhart, "A review of self-exciting spatio-temporal point processes and their applications," Statistical Science, vol. 33, no. 3, pp. 299-318, 2018. DOI: 10.1214/17-STS629.
[12] V. Filimonov and D. Sornette, "Apparent criticality and calibration issues in the Hawkes self-excited point process model: application to high-frequency financial data," Quantitative Finance, vol. 15, no. 8, pp. 1293-1314, 2015. DOI: 10.1080/14697688.2015.1032544.
[13] R. Crane and D. Sornette, "Robust dynamic classes revealed by measuring the response function of a social system," Proceedings of the National Academy of Sciences, vol. 105, no. 41, pp. 15649-15653, 2008. DOI: 10.1073/pnas.0803685105.
[14] K. P. Burnham and D. R. Anderson, Model Selection and Multimodel Inference: A Practical Information-Theoretic Approach, 2nd ed. Springer, 2002.
본 보고서는 Metron PoC Stage A 의 internal technical narrative 로 작성되었으며, 사용된 모든 데이터, 코드, fit 결과는 reproduce 가능한 형태로 보존되어 있다. 외부 연구자의 본 검증 결과 활용 또는 비판적 검토는 환영하며, 본 narrative 의 메타 학습이 학술 community 의 procedural knowledge 축적에 기여할 수 있기를 기대한다.
If this writing helped, fuel the next one
