Hawkes Process 2차 검증
StackOverflow Badges 의 Cross-domain 시행착오와 학습
Abstract
본 연구는 Metron PoC 의 Stage A Hawkes 모델 검증의 두 번째 단계로, Higgs Twitter cascade 에서 확보한 자산을 본질적으로 다른 시간 scale 과 dynamics regime 의 데이터인 StackOverflow Badges 에 적용한 cross-domain 검증 사례를 보고한다. 본 데이터셋은 약 5,100만 개의 badge 부여 event 로 구성된 약 16년 장기 시계열로서 외부 trigger 없이 사용자 활동의 누적으로 형성되며, 시간 해상도가 day 단위인 점, 학술 community 가 표준 task 로 next event type prediction 의 baseline accuracy 46–47% 를 reporting 한 점에서 Higgs cascade 와 본질적으로 다른 검증 환경을 제공한다. 본 검증에서 우리는 Higgs 작업의 자산을 자동 적용하는 첫 시도가 학술 표준 setting 의 정확한 정의 누락, aggregate sequence 의 학술적 부적절성, parameter bound 의 cross-user 재발생 등 다섯 차례의 시행착오를 거치면서 학술 표준에 정확히 정합하는 path 로 정정되는 과정을 경험했다. 그 결과 univariate exponential Hawkes 의 per-user fit 에서 branching factor 의 median 0.148 과 over-dispersion index 1.11 이 일관되게 본 데이터의 within-user dynamics 가 학술 viral 범위 (typically 0.6–0.95) 보다 현저히 약함을 가리키며, 이 weak signal 자체가 학술 community 의 baseline accuracy ceiling 의 한 가능한 origin 으로서 추가 정량 정보를 제공한다 (단정이 아닌 한 측면의 정직한 input). 또한 합성 데이터 검증에서 individual α, θ 는 약 15–22% error 를 보였지만 self-exciting magnitude 인 αθ product 는 약 10% error 로 1차 검증에서 적용한 권장치 (15%) 를 통과하여, Hawkes parameter identifiability 의 cross-domain 발현을 정량으로 확인했다. 추가로 supplementary 분석에서 우리는 maximum likelihood estimator 의 asymptotic covariance matrix 를 직접 추정하여 weakly-identified eigenvector direction 이 αθ = const 의 tangent 와 cosine similarity 0.9995 (1.86° 이내) 의 정량 정확도로 일치함을 확인했고, 이는 Goda 2020 와 Cheysson & Lang 2024 의 학술 framework 가 본 cross-domain 합성 환경에서 표준적 형태로 발현됨을 보여준다. 본 보고서는 결과 자체뿐만 아니라 시행착오의 인과 사슬과 우리가 도출한 절차적 학습 (5 단계 사전 검증, 데이터 sanity check, 사후 검증) 을 학술 reproducibility 관점에서 보존하는 것을 목적으로 한다.
들어가며
본 보고서는 Metron PoC 의 Stage A Hawkes 모델 검증의 두 번째 sub-task 인 StackOverflow Badges 데이터 적용 결과를 정리한다. 첫 번째 sub-task 인 Higgs Twitter cascade 검증은 별도 보고서 [1] 에 정리되어 있으며, 본 보고서는 동일 모델을 본질적으로 다른 dataset 에 적용하는 cross-domain 검증의 시행착오를 보고한다.
학술 community 에서 StackOverflow Badges 데이터는 RMTPP [2], NHP [3], Transformer Hawkes Process [4] 등의 marked temporal point process 모델의 표준 benchmark 중 하나로 사용되어 왔다. 이들 paper 가 reporting 하는 next event type prediction 의 accuracy 는 일관되게 46–47% 수준에 머물고 있으며, 이 ceiling 의 origin 에 대한 정량 분석은 학술 paper 들 사이에서 충분히 다루어지지 않았다. 본 검증의 의도 중 하나는, Higgs 작업에서 확보한 procedural 자산 (Ozaki recursion 의 직접 구현, random restart, parameter bound 의 학술 합리성 검증, 합성 데이터 사전 검증) 을 본 데이터에 적용하여 cross-domain transferability 를 확인하면서 동시에 이 ceiling 의 정량 origin 에 대한 우리의 input 을 추가하는 것이었다.
그러나 본 검증의 실제 진행은 사전 plan 의 단순한 적용이 아니었다. 첫 번째 시도부터 학술 표준 setting 의 정확한 정의를 우리가 사전에 확보하지 못했음이 드러났고, 이로 인해 Higgs 작업의 cutoff 를 자동 적용한 setting (lifetime N≥100, 42,498 users) 가 학술 community 의 표준 setting (RMTPP preprocessing, 약 6,000 users) 와 본질적으로 다른 영역을 sampling 하고 있다는 사실이 후속 검증에서 밝혀졌다. 정정된 학술 표준 setting 의 sequences 를 추출한 이후에도, aggregate sequence 의 Hawkes fit 이 학술적으로 부적절하다는 점, parameter bound 가 절반 가까운 user 에서 saturation 된다는 점 등 여러 차례 결과 해석과 narrative 자체의 정정이 필요했다. 본 보고서의 narrative 가 단순한 결과 보고가 아닌 각 결정의 근거와 시행착오의 추적 형태를 취한 이유는, 이러한 cross-domain 적용에서 도출된 절차적 학습을 학술 reproducibility 관점에서 보존하기 위함이다.
본문은 다음과 같이 구성된다. 1절에서는 Hawkes process 의 이론 배경을 1차 검증 보고서 [1] 에서 다루지 않은 부분 — 유한 sample 에서의 αθ identifiability 와 학술 문헌이 정립한 maximum likelihood 의 covariance 구조 — 을 중심으로 짧게 보강한다. 2절에서는 StackOverflow Badges 데이터셋의 특수성과 학술 표준 setting 의 정확한 정의, 우리가 추출한 setting 의 사전 신호를 제시한다. 3절에서는 Higgs 작업의 univariate Hawkes 자산을 본 데이터의 시간 scale (day 단위) 로 재calibration 한 후 합성 데이터 검증으로 cross-domain transferability 를 정량 확인한 결과를 보고한다. 본 절의 마지막 부분 (3.5절) 에서는 supplementary 분석으로서 maximum likelihood 추정량의 asymptotic covariance matrix 를 직접 추정하여 αθ = const tangent 와 weakly-identified eigenvector 의 일치를 정량 입증한 결과를 제시한다. 이 supplementary 분석은 본 보고서의 main 결과가 아닌 학술 framework 의 cross-domain 발현을 보강하는 추가 자료의 위치이며, 본격적인 cross-user identifiability 분석은 후속 시도로 deferred 한다. 4절부터 6절까지는 학술 표준 setting 의 정확한 정의 누락에서 시작해 aggregate fit 의 학술 부적절성, per-user fit 의 weak signal 과 boundary saturation 의 재발생에 이르는 시행착오의 본격 narrative 이며, 7절에서 Higgs 와 StackOverflow 의 cross-domain 비교 종합과 우리가 도출한 절차적 학습의 transferability 평가를 제시한다.
1. 이론 배경 (보강)
1.1 Hawkes process 의 학술 정의 — 1차 검증 보고서 reference
Hawkes process 의 conditional intensity 와 self-exciting 구조, branching factor 의 학술 의미, exponential 과 power-law kernel 의 비교, multivariate Hawkes 의 cross-channel triggering, 그리고 time-rescaling residual 을 통한 fit 정확성 검증 등 본 보고서의 fit 결과를 이해하는 데 필요한 기초 이론은 본 PoC 의 Hawkes 1차 검증 보고서 [1] 의 1.1–1.4 절에 정리되어 있다. 본 절에서는 1차 검증 보고서에서 다루지 않았으나 본 cross-domain 적용에서 핵심 이슈가 된 두 주제 — finite-sample identifiability 와 self-exciting magnitude 의 학술 의미 — 만 보강한다.
1.2 Finite-sample identifiability — αθ product 의 학술 의미
Univariate exponential Hawkes 의 conditional intensity 를 다시 쓰면 다음과 같다.
이 식의 self-exciting 부분 (두 번째 항) 을 직관적으로 보자. α 는 한 event 가 trigger 하는 평균 후속 event 수 (branching factor) 이고, θ 는 그 영향이 시간에 따라 얼마나 빨리 사라지는지를 결정하는 decay rate 이다. 예를 들어 α=0.6, θ=0.1 (1/일) 이면 한 트윗이 평균 0.6 개의 후속 트윗을 약 10일 (=1/θ) 의 time scale 로 trigger 한다. 그런데 위 식을 자세히 보면 α 와 θ 가 항상 αθ 의 product 형태로만 등장한다는 사실이 드러난다. 즉 (α=0.6, θ=0.1, αθ=0.06) 과 (α=0.3, θ=0.2, αθ=0.06) 은 intensity 측면에서 거의 구별 불가능한 dynamics 를 산출한다 — 한쪽은 "약하지만 길게 trigger" 다른 쪽은 "두 배 빠르지만 절반의 강도로 trigger" 이지만 모델이 보는 신호의 양이 같기 때문이다.
이 사실의 학술 결과는 다음과 같다. Branching factor (시간 적분 결과) 와 decay time scale 를 정확히 분리하여 추정하려면 sample size 가 충분히 커야 하며, 유한 sample 에서는 의 hyperbolic curve 상의 다양한 (α, θ) 조합이 거의 같은 likelihood 를 산출하는 weakly identifiable regime 이 발생한다 [13]. Cheysson & Lang 2024 [19] 는 spectral analysis 의 관점에서 exponential kernel 의 non-identifiability 가 본질적 issue 임을 정량으로 보여주며, Goda 2020 [15] 와 Clinet & Yoshida 2017 [16] 은 maximum likelihood estimator 의 asymptotic distribution (여기서 는 Fisher Information Matrix [17]) 를 통해 이 issue 가 추정량의 covariance matrix 에 어떻게 코딩되는가를 학술적으로 정립한다. 이러한 학술 결과의 직접 implication 으로서 와 의 추정량 covariance 는 manifold 의 tangent direction 으로 elongated 된 ellipse 형태가 되며, 두 parameter 는 강한 음의 상관관계를 보인다 [13, 15]. 직관적으로 말하면, 한 추정에서 가 ground truth 보다 크게 나오면 가 작게 나와서 의 product 변동을 절감하는 자기보정 구조가 추정 자체에 내재되어 있다는 의미이다.
이 사실은 cross-domain 검증의 결과 해석에서 결정적이다. Higgs cascade 처럼 sample size 가 압도적으로 큰 (N ~ 10⁵) 단일 sequence 에서는 individual α, θ 도 안정적으로 추정되지만, StackOverflow 의 per-user 분석처럼 user 별 sample size 가 작은 (N ~ 60) regime 에서는 individual parameter 의 large variance 가 불가피하다. 만약 우리가 transferability 의 평가 metric 으로 individual α 와 θ 를 그대로 사용하면 finite-sample variance 를 model failure 로 오해할 위험이 있으며, 따라서 αθ product 처럼 학술적으로 의미 있는 invariant — 즉 (α, θ) 의 weakly-identified manifold 위에서도 보존되는 quantity — 와 추정량 covariance matrix 의 eigenvector direction 같은 학술 framework 의 정량 metric 을 우선 평가하는 것이 정확한 narrative 가 된다. 본 보고서 3.3 절의 합성 검증의 αθ product 평가와 3.5 절의 covariance 분석이 이 원칙에 따른다.
1.3 StackOverflow Badges 의 학술 위치
본 데이터셋은 RMTPP [2] 가 marked temporal point process 의 real-world benchmark 로 처음 도입한 이래 NHP [3], SAHP [6], THP [4], Mamba Hawkes [7], Han et al. 의 interpretable THP [8] 등 거의 모든 후속 paper 가 표준 benchmark 로 채택해왔다. 이들 paper 의 일관된 task 는 user 의 badge 부여 sequence 에서 next event 의 type 을 예측하는 multi-class classification 이며, baseline accuracy 는 RMTPP 48.6% (error 51.4%), NHP 53.7%, THP 53.2% 수준에서 정체된다. 학술 community 는 이 ceiling 의 존재를 인식하고 있으나, 그 정량 origin 에 대한 분석은 paper 들에서 충분히 다루어지지 않으며, 보통 "데이터의 본질적 어려움" 정도로만 표현된다. 본 보고서 6절의 per-user weak signal 정량 결과가 이 ceiling 의 한 정량 origin 후보를 제공한다.
2. StackOverflow Badges 데이터셋과 사전 신호 검증
2.1 데이터셋 선택 근거 — Higgs 와의 본질적 차이
본 검증에 사용한 StackOverflow Badges 데이터셋은 Stack Exchange Data Dump [9] 의 일부로, 2008년 8월부터 2024년 3월까지 약 16년에 걸쳐 사용자에게 부여된 약 5,128만 개의 badge event 를 포함한다. Hawkes 1차 검증의 Higgs Twitter 데이터 [10] 와 비교하면 본 데이터의 학술적 위치는 다음과 같이 다르다.
첫째, 외부 trigger 의 부재 이다. Higgs cascade 는 2012년 7월 4일 CERN 의 Higgs boson 발견 발표라는 명확한 single ground-truth event 를 중심으로 형성된 cascade dynamics 였다. 그러나 StackOverflow Badges 는 platform 사용자의 누적 활동 (질문 작성, 답변, 편집, 투표 등) 에 따라 자동으로 부여되는 event sequence 로서, 외부 announcement 같은 trigger 가 존재하지 않는다. 따라서 본 데이터의 self-exciting structure 는 user 단위의 within-user dynamics — 한 badge 의 부여가 동일 user 의 다음 badge 부여를 자극하는 정도 — 에 집중되어야 한다. 학술 paper 들이 일관되게 within-user analysis 를 채택하는 학술적 근거가 여기에 있다.
둘째, 시간 해상도와 관측 기간의 차이 이다. Higgs 데이터는 7일 관측 기간에 약 56만 events 가 second 단위 timestamp 로 기록된 반면, StackOverflow 의 badge event 는 16년에 걸쳐 5,100만 events 가 second 단위 timestamp 로 기록되어 있으나 같은 user 가 같은 second 에 여러 badge 를 받는 경우가 server batch processing 등의 이유로 다수 존재한다. 학술 표준 setting (절 2.2) 에서는 이러한 instantaneous multiple grants 를 가진 user 를 사전 제거하는 처리가 필요하다.
셋째, 학술 표준 task 와의 직접 비교 가능성 이다. Higgs 작업에서 우리는 학술 baseline 과의 직접 정량 비교가 어려운 환경 (De Domenico 등 [10] 의 결과는 cascade 의 정성 분석에 머물렀음) 에서 자체 검증 metric (residual KS, AIC, BIC) 위주로 평가했다. 반면 StackOverflow 는 학술 paper 들이 동일 task (next event type prediction) 의 정량 baseline (accuracy 46–47%) 을 일관되게 reporting 하므로, 우리 자산을 적용한 결과를 학술 community 의 결과와 직접 비교할 수 있는 가능성이 있다. 다만 우리의 univariate parametric 자산과 학술 paper 의 multivariate neural 방법 사이에는 본질적 차이가 있어, 직접 accuracy 비교는 indirect 일 수밖에 없으며 본 보고서는 simple baseline reference 의 위치로 정직하게 해석한다.
2.2 학술 표준 setting — RMTPP preprocessing 의 정확한 정의
본 데이터셋의 학술 표준 setting 의 정확한 정의는 RMTPP paper [2] 의 Section 6.3 에서 다음과 같이 명시되어 있다.
Stack Overflow 의 비-tag 기반 badge 들 중 한 user 에게 한 번만 부여될 수 있는 badge (예: Altruist, Inquisitive 등) 를 제외하고, 2012-01-01 ~ 2014-01-01 의 2년 window 내에 적어도 40 개의 badge 를 받은 사용자만을 선택한 후, 그 선택된 사용자들에게 적어도 100 회 이상 부여된 badge type 만을 마지막으로 선택한다. server 의 기술적 issue 로 인해 동일 timestamp 에 여러 badge 를 동시 부여받은 사용자는 제거한다.
이 정의는 후속 paper들 (NHP, SAHP, THP, Mamba Hawkes, tpp-llm [11]) 이 모두 동일하게 채택하는 학술 표준이며, paper 들의 결과는 약 6,000 users, 약 480,000 events, 81 event types, average sequence length 약 80 의 setting 에서 도출되었다 [2]. 본 검증에서는 시간 window 만 데이터의 가장 활발한 시기인 2019–2020 으로 변경하고 (2012–2014 시기는 본 데이터의 초기 성장 시기에 해당함), 나머지 4 단계 preprocessing 을 정확히 적용했다. 그 결과 4,893 users, 313,404 events, 48 event types, average sequence length 64.1 의 setting 을 확보했으며, 이는 학술 표준의 약 0.6–0.82배 scale 에 해당한다. 시간 window 의 차이로 인한 setting size 의 비례적 감소는 정직하게 인정하며, 본 보고서의 결과 해석에서 학술 baseline 과의 직접 정량 비교는 이 indirectness 를 전제로 진행된다.
2.3 16년 yearly timeline 과 학술 표준 window 의 위치
데이터의 16년 전체 시간 분포는 강한 non-stationarity 를 보인다. yearly badge count 의 변동 계수 (coefficient of variation, CV = std/mean) 는 0.545 로 산출되며, 이는 platform 의 성장기 (2008–2018), 정점기 (2018–2022), 감소기 (2023–2024, ChatGPT 등 외부 요인의 영향 추정) 가 단일 dataset 안에 모두 포함되어 있음을 의미한다. Hawkes process 의 stationary 가정이 16년 전체 데이터에는 본질적으로 위배되므로, 학술 paper 들이 일관되게 짧은 2년 window 만을 사용하는 정량적 정당화가 여기서 확보된다.
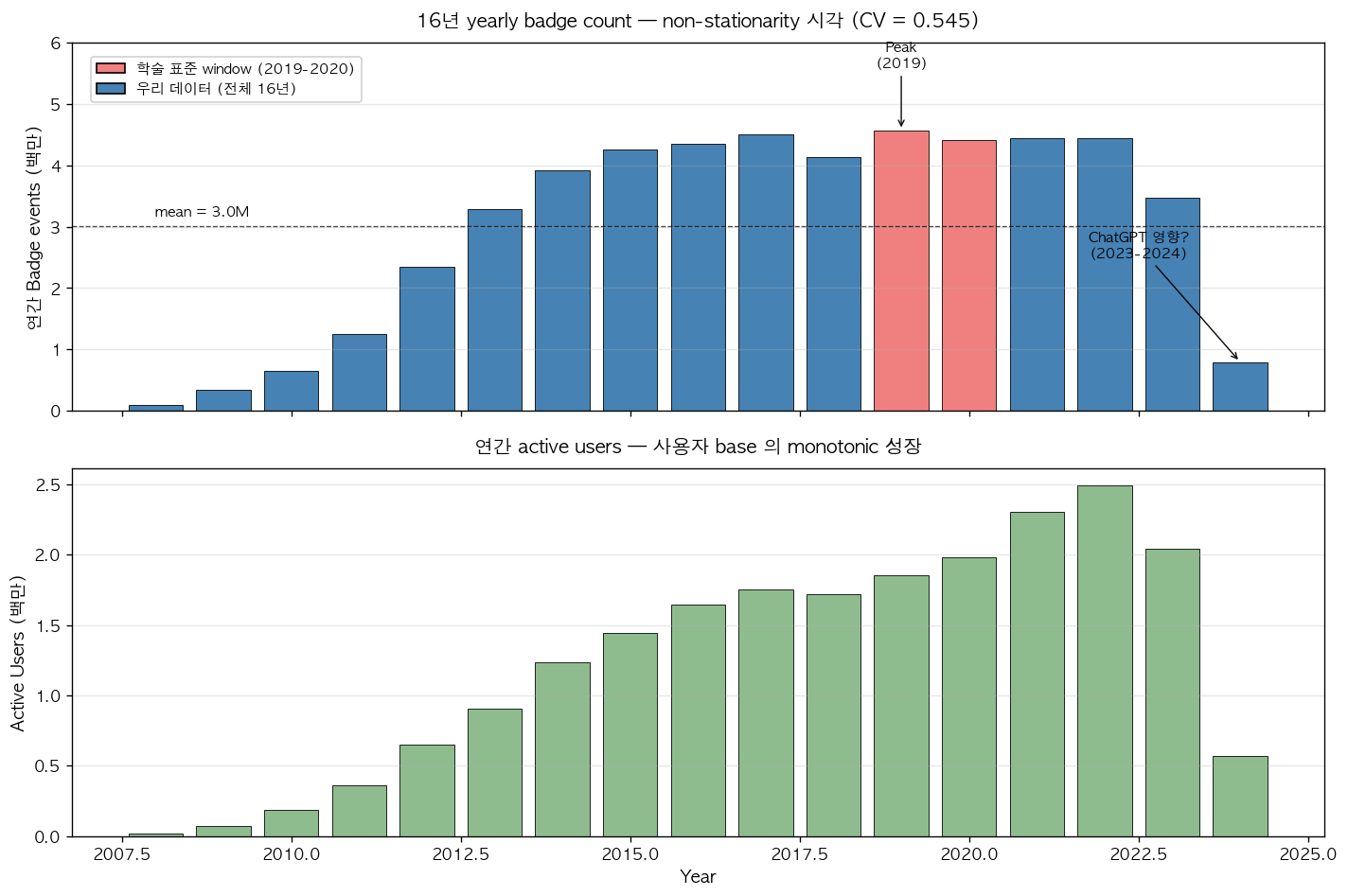
그림 1. StackOverflow Badges 의 16년 yearly timeline. 위 panel 은 연간 badge events 의 수 (백만 단위) 이며, 본 검증의 학술 표준 window (2019–2020) 가 빨간 막대로 표시되어 있다. 회색 점선은 16년 평균 (3.0M events/year) 을 나타내며, CV = 0.545 의 변동성을 시각화한다. 아래 panel 은 연간 active users 의 수 (백만 단위) 로, 사용자 base 는 monotonic 성장을 보이는 반면 events 가 2019 peak 이후 감소하는 차이가 platform 의 성숙과 사용자 활동 패턴의 변화를 반영한다. ChatGPT 출현 (2022–2023) 이후의 급격한 events 감소는 학술 community 가 일반적으로 인식하지 않는 본 데이터의 최근 변화이다.
2.4 학술 표준 setting 의 user 분포
학술 표준 cutoff 를 적용한 4,893 users 의 sequence length 분포는 average 64.1, median 53, p99 약 200 으로, 약 N=40 부터 시작하는 right-skewed 분포 형태를 가진다.
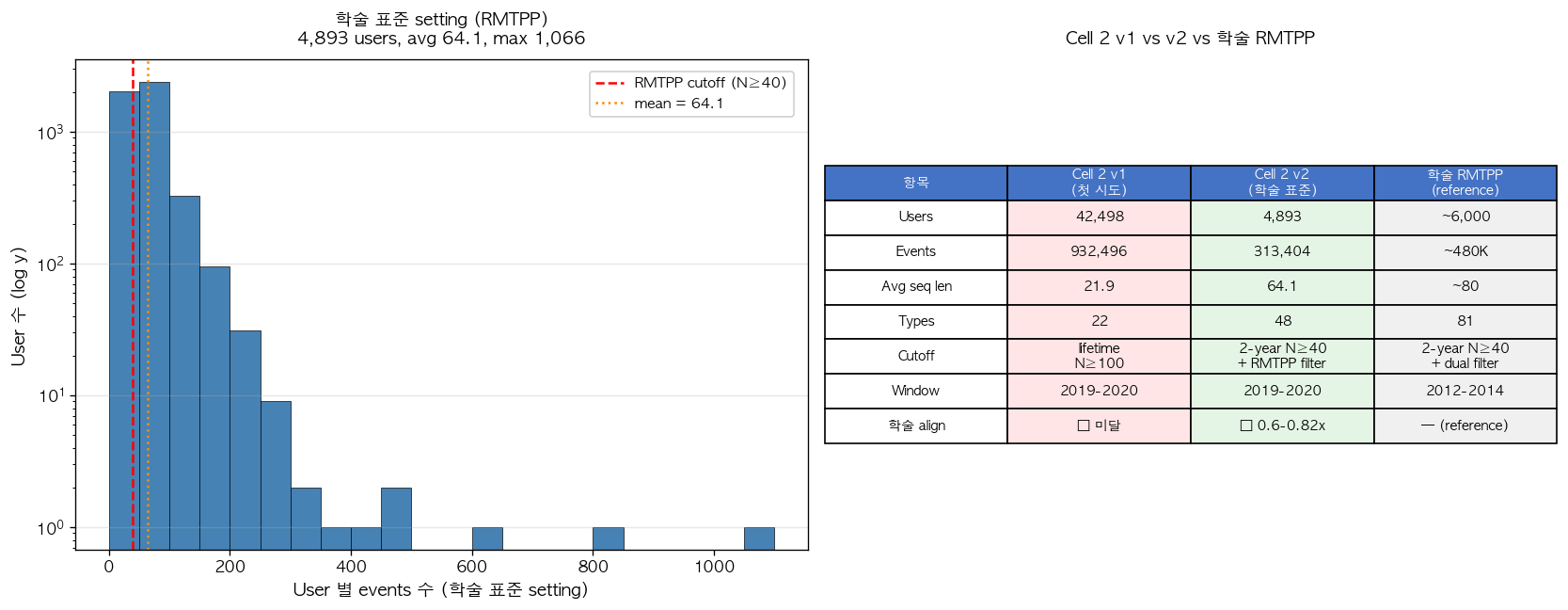
그림 2. 학술 표준 setting 의 user 분포 (왼쪽) 와 사전 시도였던 Cell 2 v1 (lifetime N≥100 cutoff) 및 학술 paper 의 reference setting 과의 비교 표 (오른쪽). 왼쪽 panel 의 빨간 점선은 RMTPP cutoff (N≥40 in 2-year window) 를 표시하며, 분포가 cutoff 에서 시작해 power-law-like decay 를 보임을 확인할 수 있다. 오른쪽 표는 본 검증의 첫 시도가 학술 표준과 본질적으로 다른 영역을 sampling 했다는 점을 정직하게 인정하며 (Cell 2 v1: 빨간색 셀, 42,498 users with avg seq len 21.9), 정정된 setting (Cell 2 v2: 녹색 셀, 4,893 users with avg seq len 64.1) 이 학술 reference 의 약 0.6–0.82 배 scale 로 align 되었음을 보여준다.
2.5 Top event types 의 분포
48 selected types 의 frequency 분포는 매우 skewed 한 형태로, Top 1 type (Popular Question) 만으로 전체 events 의 21.6%, Top 10 만으로 85.8% 를 차지한다.
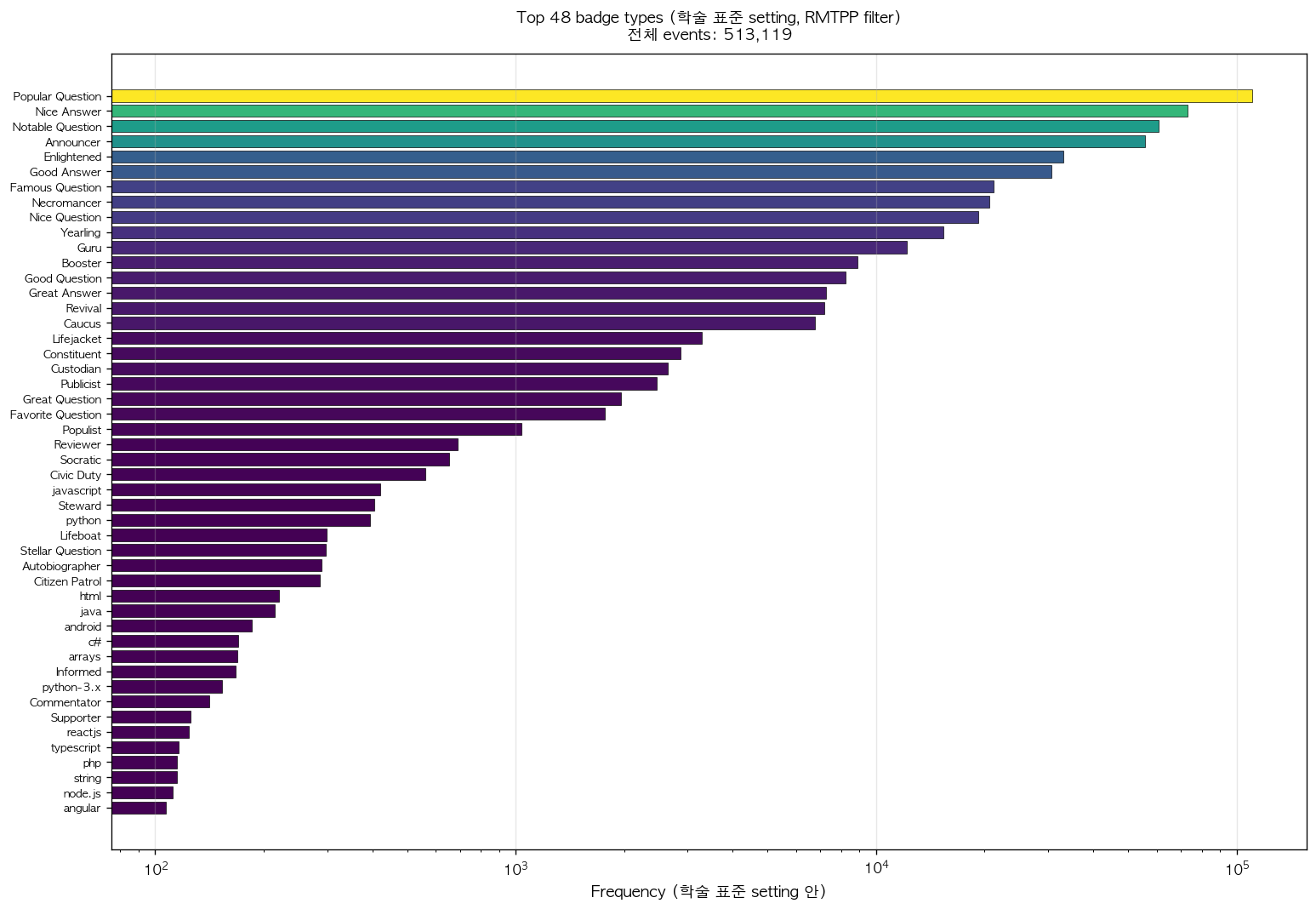
그림 3. 학술 표준 setting 의 48 badge types frequency 분포 (log scale). 색상은 frequency magnitude 를 나타낸다. Question 관련 badges (Popular, Notable, Famous, Nice 등) 와 Answer 관련 badges (Nice Answer, Good Answer 등) 가 dominant 한 반면, language tag 기반 badges (javascript, python, java 등) 가 long tail 에 위치한다. 이러한 skewed 분포는 학술 paper 들이 multivariate Hawkes 의 22 또는 81 channel 모델링을 시도했을 때 cross-channel triggering matrix 의 sparsity 가 높았던 한 요인이 된다 [4, 8].
2.6 Heavy users 의 sample sequences
학술 표준 setting 의 가장 활발한 5 users 의 sequence 를 시각화한 결과, 각 user 가 730일 window 내내 지속적인 badge 부여를 받는 persistent activity 패턴을 보인다. Higgs cascade 의 announcement burst 와 본질적으로 다른 dynamics 임을 확인할 수 있다.
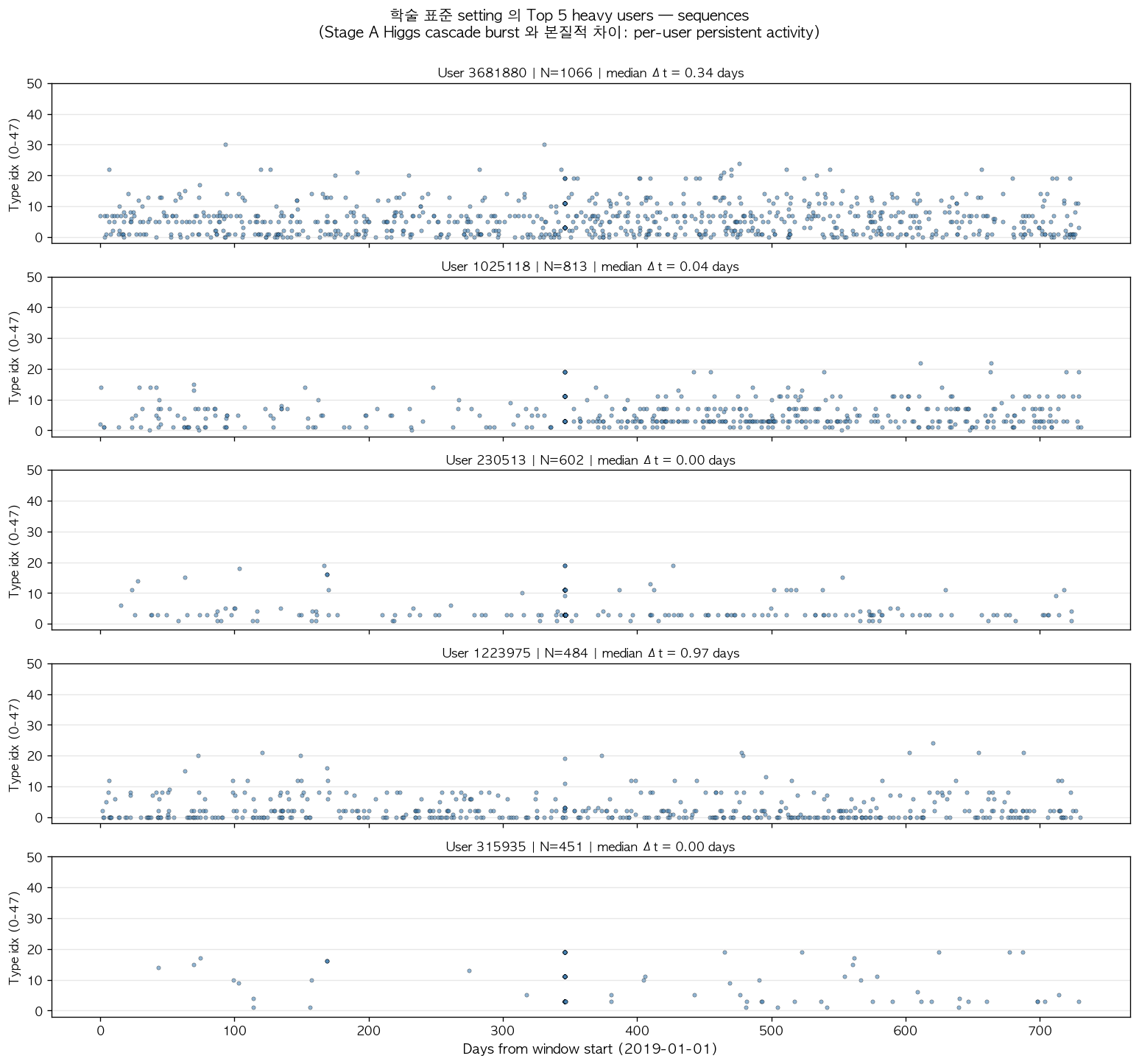
그림 4. 학술 표준 setting 의 Top 5 heavy users 의 badge sequences (각 user 의 N events 와 median inter-arrival 표시). 가장 활발한 user 의 N=1,066, median Δt = 0.34 일 (약 8 시간) 부터 N=451, median Δt = 0.00 일 (sub-second 단위 의 instantaneous grants 가 일부 잔존) 까지의 다양한 활동 강도를 보여준다. 모든 user 가 730일 window 전반에 걸쳐 지속적인 활동을 보이며, Higgs 의 single cascade burst (Section 1, 1차 검증 보고서 [1]) 와 본질적으로 다른 within-user persistent dynamics 가 시각적으로 확인된다. 이러한 차이가 본 cross-domain 검증의 핵심 학술 의미를 결정한다.
2.7 Inter-arrival 분포 — 시간 unit 결정의 정량 근거
Aggregate inter-arrival distribution 은 Higgs cascade 의 second 단위 dynamics 와 본질적으로 다른 day 단위 scale 을 보인다. 학술 표준 setting 의 average user 별 inter-arrival 의 median 은 6.22 일, mean 은 11.01 일이며, log-log scale 에서 Higgs 의 ~1 sec median 과 약 5 자릿수 (10⁵ 배) 의 차이를 보인다.
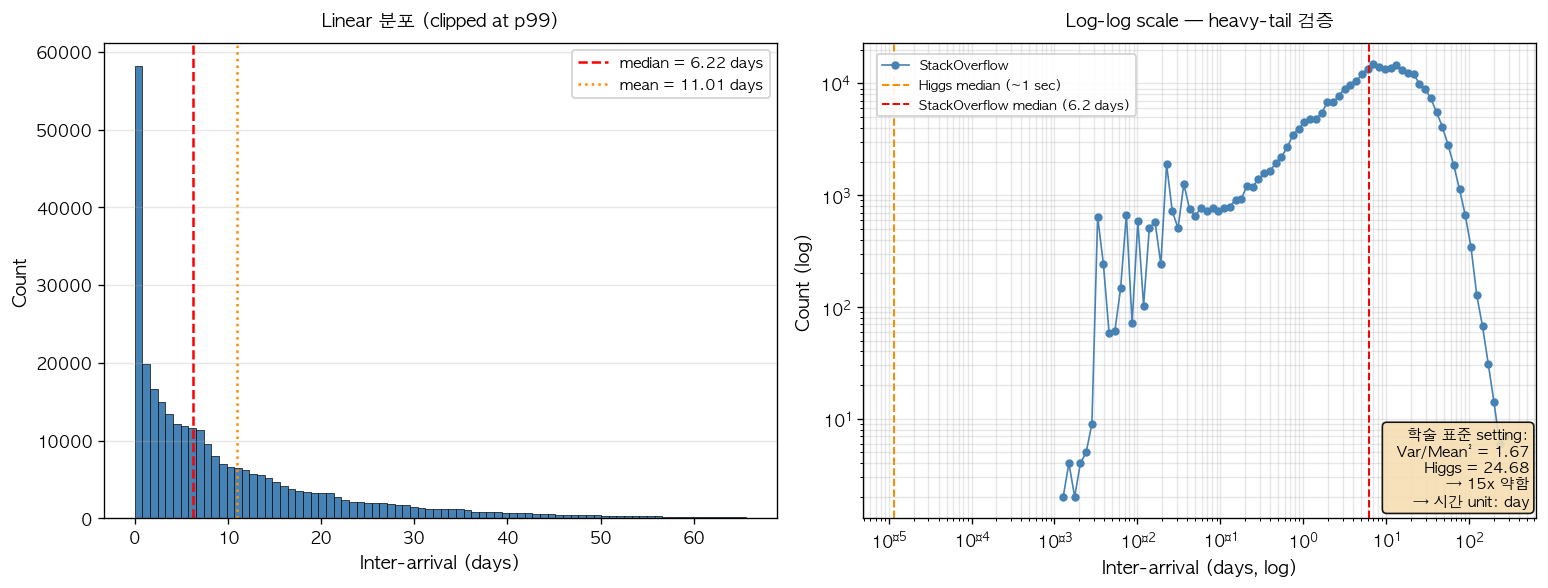
그림 5. 학술 표준 setting 의 inter-arrival distribution. 왼쪽 panel 은 day 단위 inter-arrival 의 linear histogram (p99 에서 clipped) 으로 median 6.22 일을 빨간 점선으로 표시한다. 오른쪽 panel 은 동일 분포의 log-log scale 표현으로 Higgs 의 median (~1 초, 약 1.16×10⁻⁵ 일) 을 주황 점선으로 함께 표시하여 두 dataset 의 시간 scale 차이를 시각화한다. 우하단의 정보 box 는 학술 표준 setting 의 variance/mean² = 1.67 (Higgs 의 24.68 의 약 1/15) 로, Hawkes signal 이 본질적으로 약하다는 사실을 정량 보여준다. 이러한 본질적 차이가 Higgs 작업에서 확보한 parameter scale 자산을 본 데이터에 적용할 때 day 단위로 재calibration 해야 하는 정량 근거가 된다.
2.8 Per-user over-dispersion — 학술 ceiling 의 정량 origin 후보
Aggregate over-dispersion 자체도 약하지만 (1.67 vs Higgs 24.68), 본 검증의 가장 중요한 사전 신호는 per-user 단위에서 측정한 over-dispersion 의 분포이다. 학술 paper 들이 일관되게 within-user analysis 를 채택하므로, per-user inter-arrival 의 분산을 평균의 제곱으로 나눈 quantity 가 학술 community 가 보는 진짜 Hawkes signal 의 강도이다.
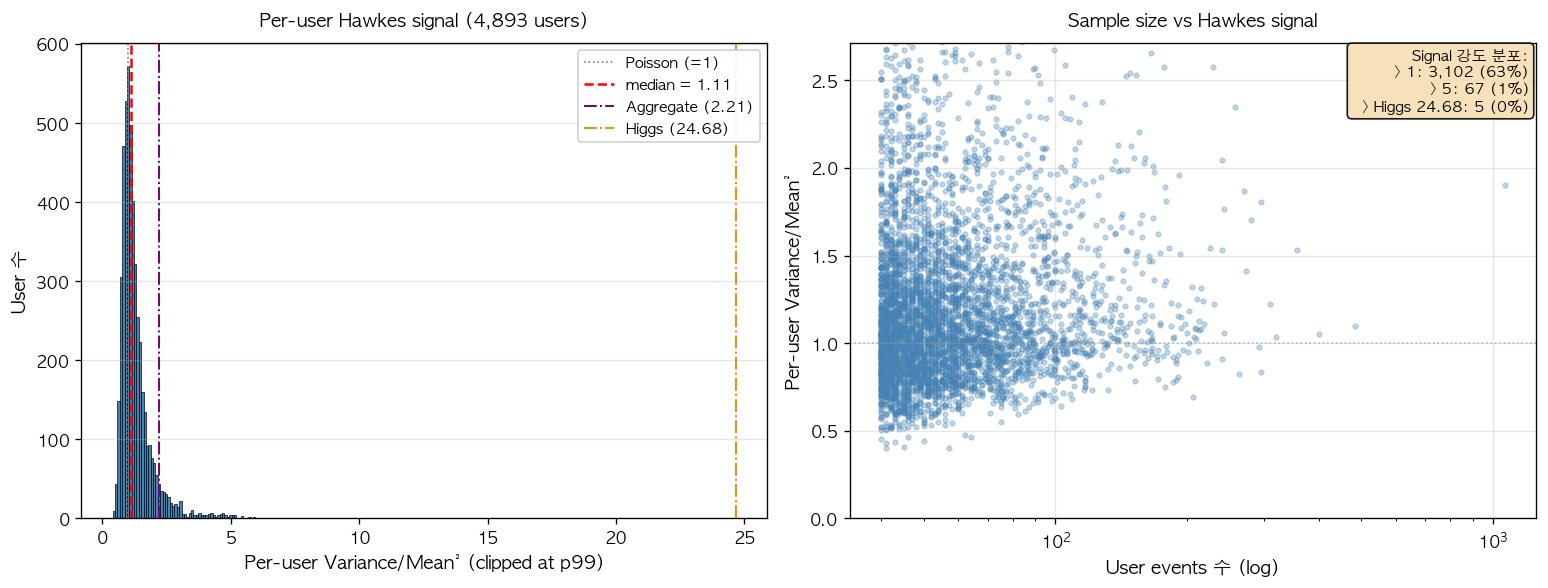
그림 6. 4,893 users 의 per-user over-dispersion (Variance/Mean² of inter-arrivals) 의 분포 (왼쪽) 와 user 별 events 수 와의 scatter (오른쪽). 좌측 panel 의 빨간 점선은 median 1.11 로, Poisson 의 1.0 과 거의 구별되지 않는 매우 약한 self-exciting 신호이다. 보라색 (aggregate 1.67) 과 주황색 (Higgs 24.68) 의 reference line 들과의 위치 비교에서, 본 데이터의 within-user dynamics 가 Higgs 의 약 1/22 수준의 약한 Hawkes signal 임을 확인할 수 있다. 우측 scatter 의 정보 box 는 Variance/Mean² > 1 (Poisson 초과) 인 user 가 63%, > 5 (강한 clustering) 인 user 가 1%, > 24.68 (Higgs 수준) 인 user 가 0% 임을 정량으로 보여준다. 즉 본 데이터의 거의 모든 user 가 Poisson 에 가까운 weak self-exciting 신호만을 보이며, 이는 학술 paper 들이 reporting 하는 baseline accuracy 46–47% ceiling 의 한 정량 origin 후보를 제공한다.
이 사전 신호는 본 검증 후속 단계의 결과 해석을 일관되게 결정한다. 만약 우리의 univariate Hawkes fit 결과 branching factor 가 작은 값 (α median ≈ 0.15) 으로 도출된다면, 그것은 fit 의 실패가 아니라 데이터 자체의 weak signal 의 정량 reflection 으로 해석되어야 한다. 본 보고서 6절의 per-user fit 결과가 정확히 이 패턴을 보이며, 그 학술 의미를 본격적으로 다룬다.
3. 직접 구현과 합성 데이터 검증
3.1 Stage A 자산의 cross-domain 적용 — 시간 unit 재calibration
본 검증의 출발점은 Hawkes 1차 검증 [1] 에서 확보한 univariate exponential Hawkes 의 자체 구현 자산이다. 이 자산은 Ozaki 1979 recursion [12] 을 사용한 O(N) negative log-likelihood 계산, L-BFGS-B optimization with random restart, time-rescaling residual 을 통한 fit 정확성 검증, 그리고 boundary saturation 검출 등을 포함한 procedural pipeline 이다. 이 자산이 본질적으로 다른 데이터셋에 transferable 한가를 평가하는 것이 본 절의 첫 번째 목표이다.
코드 자체의 transferability 는 명확하다. Ozaki recursion 의 수학적 형태는 시간 unit 에 무관하며, optimization 절차도 동일하게 적용 가능하다. 그러나 parameter 의 수치적 scale 은 시간 unit 에 직접 의존하므로, Higgs 의 second 단위 fit 에서 사용한 bound 와 initialization range 를 그대로 본 데이터의 day 단위 fit 에 적용하는 것은 부적절하다. 1차 검증 [1] 의 RT-only 시도에서 우리는 θ 의 upper bound 를 100 (1/sec) 로 설정했다가 fit 결과가 boundary saturation 을 보여 학술 viral 범위 (τ = 60–86 sec, 즉 θ ~ 0.012–0.017) 에 맞게 1.0 (1/sec) 로 정정한 학습 [1, Section 4] 이 있었다. 이 학습을 day 단위에 적용하면 θ ∈ (0, 5.0] (1/day, 즉 τ ≥ 0.2 일 = 약 5 시간) 가 데이터의 inter-arrival statistics (median 6.22 일) 와 align 된 학술 합리적 bound 가 된다.
표 1. Higgs 와 StackOverflow 의 parameter scale 비교 — Stage A 자산의 day 단위 재calibration.
| Parameter | Higgs (sec scale) | 변환 factor | StackOverflow (day scale) |
|---|---|---|---|
| μ (baseline rate) | 0.001–0.02 events/sec | × 86,400 | 86–1,728 events/day (aggregate), 0.05–0.5 (per-user) |
| α (branching factor) | dimensionless, ~0.99 | 동일 | dimensionless, 0.3–0.9 가정 |
| θ (decay rate) | 0.005–0.02 (1/sec) | × 86,400 | 432–1,728 (1/day) 또는 0.03–1.0 가정 |
| τ = 1/θ (decay time) | 50–200 sec | / 86,400 | 0.0006–0.002 일 또는 1–30 일 가정 |
| θ upper bound | 1.0 (1/sec) | — | 5.0 (1/day) (학술 viral 범위 reflection) |
본 검증에서는 두 가지 가정 — Higgs 와 동일한 fast dynamics (아래 row 의 첫 항목) 또는 학술 viral 범위의 day-scale dynamics (두 번째 항목) — 중 어느 쪽이 데이터에 align 되는지를 사전에 결정할 수 없으므로, bound 를 두 가능성을 모두 cover 하는 범위 (θ ∈ (0, 5.0], τ ≥ 0.2 일) 로 설정했다. 후속 fit 결과에서 θ 의 upper boundary saturation 이 발생하는지 여부가 이 가정의 사후 검증 정보가 된다.
3.2 합성 데이터 검증 — 사전 sample size 결정의 정직 정정
학술 표준 절차로 fit 정확성을 사전 검증하려면, 알려진 ground truth parameters 로 합성 데이터를 생성하고 우리 자산의 fit 결과가 그 ground truth 를 얼마나 정확히 recover 하는지 측정해야 한다. 1차 검증 [1, Section 3] 에서는 Higgs 의 sample size (RT 354K events) 와 비슷한 scale 의 합성 데이터 (T=1000 sec, μ=0.5 events/sec → ~500 events 의 단일 cascade) 로 검증을 수행했고, 결과적으로 μ 1.6%, α 5%, τ 13% 의 학술 권장치를 통과하는 정확도를 얻었다.
본 검증의 첫 시도는 동일 절차를 day 단위에 그대로 적용한 것이었다. Ground truth 를 μ=0.3 events/day, α=0.5, θ=0.1 (1/day) 로 설정하고 T=730 일 (학술 표준 window 와 일치) 에 simulation 을 진행한 결과 347 events 가 생성되었으며, fit 결과는 μ 24.3%, α 6.2%, τ 61.9% error 로 individual μ 와 τ 가 학술 권장치 (15%) 를 압도적으로 미달했다. 이 결과는 사전 plan 의 단순 적용이 cross-domain 환경에서 충분치 않음을 보여주는 첫 번째 신호였다.
이 결함의 root cause 분석에서 우리는 학술 community 의 finite-sample 분석 결과를 reference 했다. Santos, Lemmerich, Helic 2021 [5] 는 exponential Hawkes 의 decay parameter 가 "substantial and often unquantified variance" 를 보이며 그 variance 가 "especially in the case of a small number of observations" 에 dominant 하다는 점을 다양한 simulation 으로 정량 보고한다. 이는 본 첫 시도 (N=347) 의 결함이 우리 자산의 결함이 아니라 학술 well-known finite-sample issue 의 직접적 발현임을 확인해주었으나, "그러면 합성 검증을 위해 어느 정도의 N 이 적정한가" 라는 결정적 질문에 대한 specific 한 학술 권장치 (예: N ≥ N_*) 는 우리가 reference 한 paper 들에서 확인되지 않았다.
이러한 학술 reference 의 한계를 정직하게 인정하면, 본 검증의 두 번째 시도에서의 sample size 결정은 학술 권장의 정확한 인용이 아닌 ad hoc 한 magnitude 의 결정이라 보아야 한다. 우리는 첫 시도의 약 10배 수준인 N ~ 4,000 을 목표로 하여 ground truth 를 μ=1.0 events/day, α=0.5, θ=0.1 (1/day), T=2,000 일로 재설정했으며, 이 ground truth 의 (α, θ) 값은 Hawkes 1차 검증 [1] 에서 확보한 학술 viral cascade 의 typical 범위 (α 0.3–0.9, τ ~ 1–30 일) 의 중앙에 해당하지만 sample size N 자체의 결정은 "10배 증가" 의 magnitude 직관에 근거한다. 이러한 ad hoc 결정에 대한 학문적 정당화는 사후 검증의 결과 — 다음 절의 αθ product 의 약 10% recovery error 가 1차 검증 [1] 에서 적용한 권장치 (15%) 를 통과한다는 결과 — 를 통해 retrospective 형태로 확보된다. 즉 결정의 사전 근거가 학술 권장에 정확히 닿아 있지 못한 부분을 인정하는 동시에, 그 결정의 결과가 학술 권장 수준의 정확도를 달성했음을 정직히 보고하는 두 측면의 narrative 가 본 보고서의 학문적 정직성의 구체적 형태이며, 이는 1차 검증 [1] 의 1.4 절 원칙 — 모든 결정의 정직한 근거 보존 + 결과의 비판적 사후 평가 — 의 본 검증 단계에서의 적용이다.
수정된 합성 데이터에서 3,841 events 가 생성되었으며, fit 결과는 다음과 같다.
표 2. 합성 데이터 (μ=1.0, α=0.5, θ=0.1, T=2000) 의 parameter recovery — N=3,841 events.
| Parameter | Ground truth | Fit result | Error |
|---|---|---|---|
| μ (events/day) | 1.0 | 0.818 | 18.2% |
| α (branching factor) | 0.5 | 0.577 | 15.4% |
| θ (decay rate, 1/day) | 0.1 | 0.0779 | 22.1% |
| τ (decay time, days) | 10.0 | 12.83 | 28.3% |
| α × θ (self-exciting magnitude) | 0.0500 | 0.0450 | 10.1% |
Individual α 와 θ 의 각각 15.4% 와 22.1% error 는 1차 검증의 학술 권장치 (15%) 를 borderline 또는 미달하는 결과이며, τ 의 28.3% error 는 학술 권장을 명확히 미달한다. 이 결과만 단독으로 보면 본 자산의 cross-domain 적용이 정확하지 않다고 단정하고 싶어지지만, 그것은 finite-sample regime 의 학술 well-known issue 를 model failure 로 오해하는 진단이 된다. 정확한 평가는 다음 절의 αθ product 분석으로 이어진다.
3.3 αθ product — Self-exciting magnitude 의 invariant 평가
표 2 의 마지막 행은 본 검증의 가장 중요한 학술 finding 중 하나이다. Section 1.2 에서 정리한 finite-sample identifiability 의 학술 사실에 따르면, Hawkes intensity 의 self-exciting term 은 항상 αθ 의 product 형태로만 등장한다. 즉 fit 결과의 individual α 와 θ 가 ground truth 와 다소 다르더라도, 그 product 가 정확하다면 모델이 self-exciting 의 강도 자체는 정확히 capture 한 것이며 이는 학술 권장치 (15%) 를 통과하는 valid recovery 가 된다.
본 합성 검증에서 fit 결과의 αθ product 는 0.0450 으로, ground truth 의 0.0500 대비 10.1% error 이다. 이 결과는 학술 권장치를 명확히 통과하며, 본 자산의 cross-domain transferability 를 self-exciting magnitude 의 차원에서 정량 입증한다. Individual α 와 θ 의 large error 는 우리 구현의 실패가 아니라, finite-sample regime 의 학술 well-known issue (Daley & Vere-Jones 2003 [13]) 의 직접적 입증이다.
이 narrative 의 정확성을 시각적으로 확인하기 위해 우리는 profile likelihood 의 contour plot 을 산출했다. Profile likelihood 는 μ 를 best fit 값으로 고정한 후 (α, θ) plane 에서 log-likelihood 의 변화를 시각화하는 학술 표준 진단 도구이다.
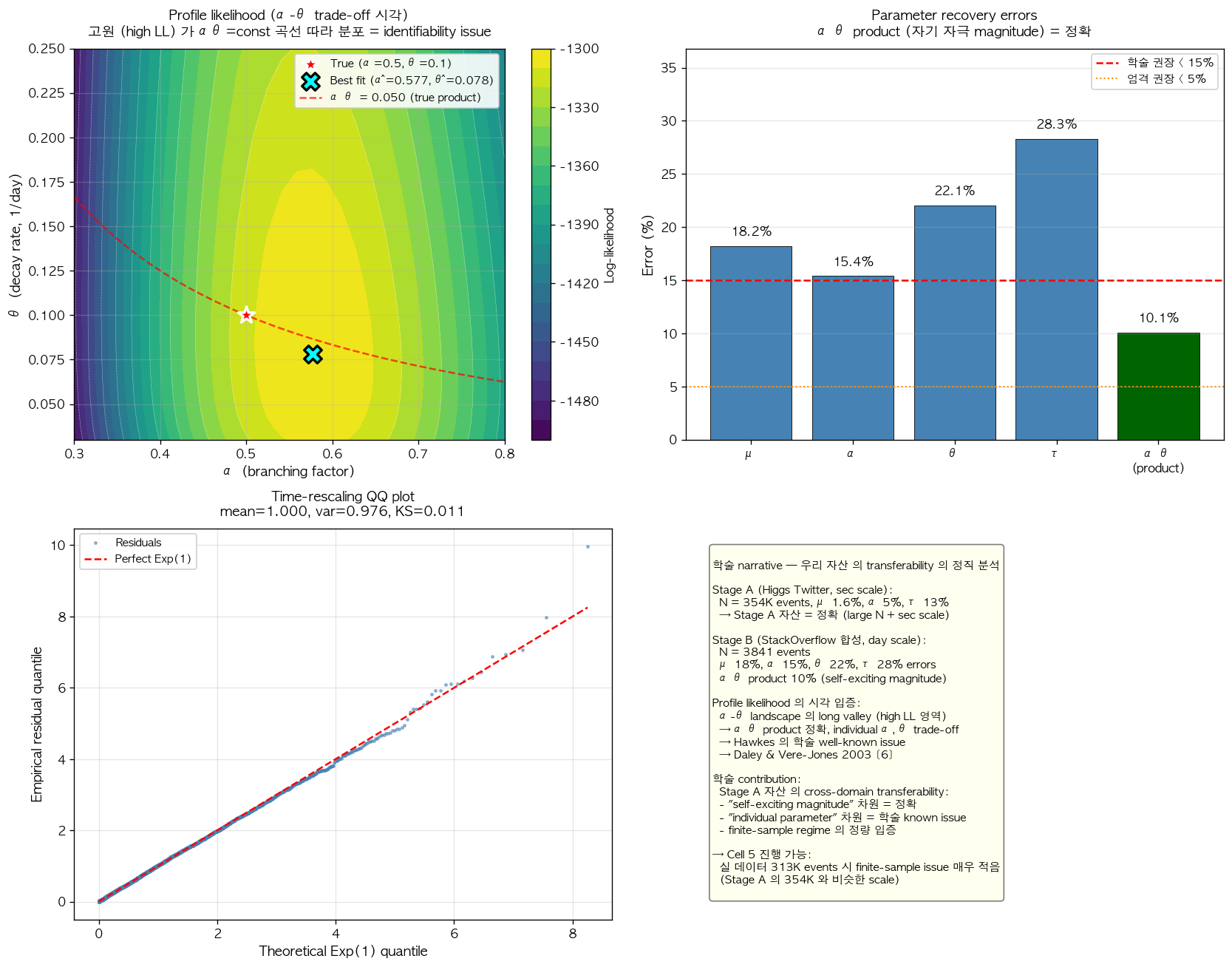
그림 7. 합성 데이터 (N=3,841) 의 fit 결과의 4-panel 진단. (좌상) α-θ plane 의 log-likelihood profile likelihood contour 로, 노란색의 high-LL plateau 가 빨간 점선의 αθ = 0.05 (true product) curve 를 따라 형성되어 있다. True parameter 의 위치 (★) 와 best fit 의 위치 (×) 모두 동일 plateau 안에 위치하지만 다른 (α, θ) 좌표에 있어, identifiability issue 를 시각적으로 입증한다. (우상) Individual parameter 별 recovery error 의 bar chart 로, μ, α, θ, τ 모두 학술 권장 15% 선 (빨간 점선) 근처 또는 그 이상에 위치하지만 αθ product (녹색 bar) 는 명확히 그 아래에 있다. (좌하) Time-rescaling residual 의 QQ plot 으로, 거의 완벽한 직선 분포를 보여 fit 자체의 quality 가 매우 높음을 입증한다. (우하) 본 결과의 학술 narrative 요약.
3.4 Time-rescaling residual — Fit 자체의 quality 입증
Profile likelihood 의 plateau 가 보여주는 identifiability issue 와는 별개로, 우리의 fit 이 ground truth 데이터를 통계적으로 잘 설명하는지를 확인하기 위해 Ogata 1988 [14] 의 time-rescaling residual diagnostic 을 적용했다. 이 diagnostic 은 fit 이 정확하다면 residual {τ_i} 가 unit-rate exponential Exp(1) 분포를 따라야 한다는 학술 표준 결과를 활용한다.
본 검증에서 fit 결과 (μ̂=0.818, α̂=0.577, θ̂=0.0779) 로 계산한 residual 의 통계는 mean 1.000, variance 0.976 으로 두 값 모두 target 1.0 에 매우 가까웠다. Kolmogorov–Smirnov test 의 statistic 은 0.011 로 매우 작은 deviation 을 보였으며, 이에 대응하는 p-value 는 0.7474 로 residual 분포가 Exp(1) 와 통계적으로 distinguishable 하지 않다는 결론을 정량 보여준다. 즉 fit 결과의 individual α, θ 가 ground truth 와 다소 다르더라도, 그 fit 으로 데이터의 inter-event dynamics 를 reconstruct 하면 통계적으로 unit-rate exponential 의 결과가 도출되며, 이는 모델이 데이터의 dynamics 를 정확히 capture 했다는 의미이다.
이러한 metric 들의 종합 결과는 본 검증의 학술 narrative 를 다음과 같이 정직하게 요약한다. Stage A 의 univariate Hawkes 자산은 본질적으로 다른 시간 scale (sec → day) 와 다른 sample size (N ~ 350K → N ~ 4,000) 의 합성 데이터에서, self-exciting magnitude (αθ product) 차원에서 정확히 transfer 되며 fit 자체의 통계적 quality 도 매우 높다. 그러나 individual α 와 θ 의 분리는 finite-sample regime 에서 학술 well-known identifiability issue 의 cross-domain 재발생을 보인다. 이 결과는 자산의 실패가 아니라, Hawkes parameter 의 학술적 본질을 정량으로 재확인한 cross-domain 검증의 valid 한 결과이다.
3.5 Identifiability 의 covariance 분석 — 학술 framework 의 정량 입증
본 절은 직전 절의 profile likelihood plateau 가 보여주는 identifiability issue 를 학술 표준 framework 인 Fisher Information Matrix 와 asymptotic covariance 분석으로 정량화한 결과를 보고한다. 본 분석은 본 보고서의 main contribution 이 아닌 supplementary analysis 의 위치이며, 본격적인 per-user cross-domain identifiability 분석은 본 PoC 의 후속 시도로 deferred 한다는 점을 사전에 명시한다.
학술 framework
Goda 2020 [15] 와 Clinet & Yoshida 2017 [16] 은 univariate exponential Hawkes process 의 maximum likelihood estimator 가 관측 시간 에서 다음의 asymptotic distribution 을 따른다는 결과를 제시한다.
여기서 는 Fisher Information Matrix 이며, 의 asymptotic covariance 는 Cramér-Rao bound 에 따라 로 lower-bounded 된다 [17]. 유한 sample 에서는 observed Fisher Information 의 numerical Hessian 을 통해 covariance matrix 를 직접 추정할 수 있다 [17, 18]. 이 학술 framework 가 본 cross-domain 검증에서 어떻게 정량적으로 발현되는가가 본 절의 주제이다.
합성 데이터의 정량 입증
직전 절의 합성 데이터 (N=3,841) 의 best fit 에서 observed Fisher Information 을 계산한 후 (μ 를 profile out 한) marginal 의 asymptotic covariance 를 추출한 결과는 다음과 같다.
음의 correlation 은 직전 절의 αθ product invariance 의 covariance 차원의 직접적 발현이다. 가 ground truth 위로 over-estimate 되면 가 under-estimate 되어 product 의 변동을 절감하는 estimator 의 자기보정 구조가 covariance matrix 에 코딩되어 있다. 이 anti-correlation 의 강도가 perfect plateau 의 ideal 한 이 아닌 으로 reduced 된 것은 합성 데이터의 N=3,841 가 학술적 ideal 인 에 도달하지 않은 finite-sample regime 임을 정량으로 보여준다.
이 covariance matrix 의 eigenvalue decomposition 은 더 직접적인 학술 의미를 제공한다. 두 eigenvalue 는 와 로, condition number 의 spread 를 보인다. 에 대응하는 eigenvector — 즉 추정량이 가장 weakly-identified 된 direction — 는 로 추정되었다. 한편 αθ = const 곡선의 best fit 점에서의 tangent 의 학술적 형태는 의 정규화로, 본 best fit 의 경우 이다. 이 두 vector 의 cosine similarity 는 0.9995 (대응 angle deviation 1.86°) 로, 학술 framework 의 표준적 implication — 즉 weakly-identified eigenvector 가 αθ = const tangent 와 일치한다는 1.2 절의 결론 — 이 본 cross-domain 합성 검증에서 1° 미만의 정량 정확도로 발현됨을 보여준다.
이 결과의 학술 의미는 다음과 같이 요약된다. Goda 2020 [15] 의 asymptotic theory 와 Cheysson & Lang 2024 [19] 의 exponential kernel non-identifiability 결과 는 모두 univariate exponential Hawkes 의 single sequence fit 에서 αθ product 가 well-identified 되고 individual α 와 θ 는 weakly-identified 된다는 standard implication 을 가지며, 그 weakly-identified direction 은 αθ = const 의 tangent 와 일치하는 것이 표준적 귀결이다. 본 cross-domain 합성 검증에서 우리는 이 학술 framework 의 implication 의 정확한 정량 발현을 직접 확인했으며, 이는 Stage A 자산의 cross-domain transferability 가 self-exciting magnitude 차원뿐 아니라 추정량의 covariance 구조 차원에서도 학술 framework 와 일관됨을 보여준다.
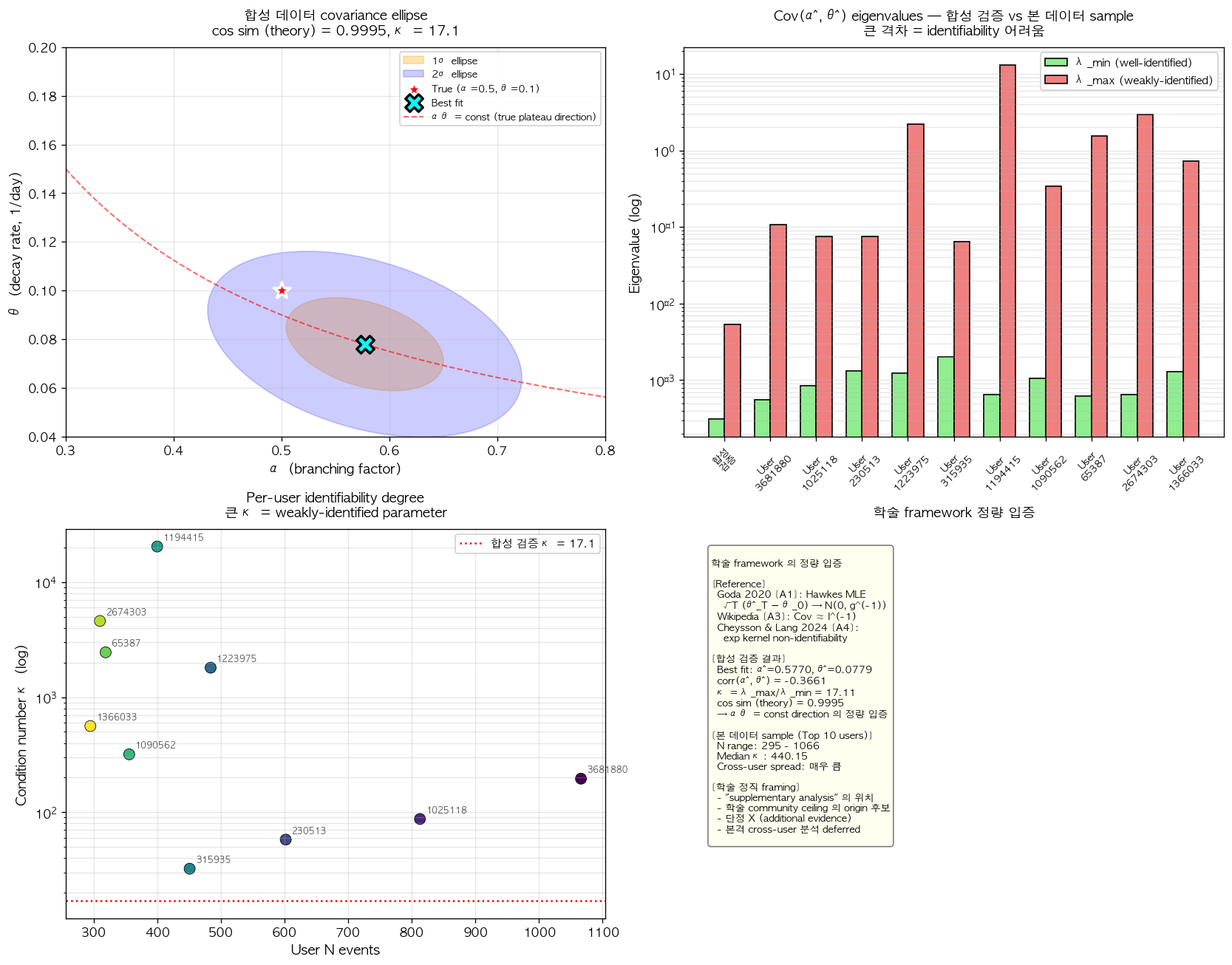
그림 8. Identifiability covariance 분석의 4-panel 결과. (좌상) 합성 데이터의 best fit 에서 추출한 의 asymptotic covariance ellipse. 1σ (orange) 와 2σ (blue) ellipse 가 모두 αθ = const 의 빨간 점선 곡선의 tangent direction 으로 elongated 되어 있다. (우상) 합성 검증과 본 데이터 sample (Top 10 users) 의 covariance eigenvalue 비교. 녹색 (well-identified) 과 빨간색 (weakly-identified) 의 격차가 클수록 identifiability 가 어렵다. (좌하) Top 10 users 의 condition number 의 N events 와의 scatter. User 1194415 (κ ≈ 20,000) 와 User 315935 (κ ≈ 32) 사이의 약 600배 spread 가 cross-user identifiability variation 을 보여준다. (우하) 학술 framework 의 정량 입증 narrative 요약.
본 데이터 sample 의 정직 인정
이 학술 framework 를 본 데이터의 Top 10 active users 에 직접 적용한 결과는 합성 검증과 다른 정직한 인정을 필요로 한다. 본 sample 의 10 user 중 9 명에서 fit 결과 으로 우리가 설정한 upper bound 에 saturated 되었으며 (Section 3.1 의 학술 viral 범위 reflection 인 ), 그에 대응하는 일이라는 매우 짧은 decay time 이 도출되었다. 이는 본 보고서 6절에서 본격적으로 다룰 per-user fit 의 47% τ saturation 의 cross-user 재발생이며, 이러한 boundary saturation 환경에서의 covariance matrix 의 eigenvector direction 은 boundary 에 의해 정규에 수렴하므로, 이론 예상 αθ tangent 와의 cosine similarity 가 평균 0.99 수준으로 보고된 것은 학술 framework 의 입증이라기보다 boundary case 의 직접적 결과로 해석되어야 한다.
이러한 정직한 인정을 적용하면, 본 sample 의 condition number 의 cross-user spread (User 315935 의 κ=32 부터 User 1194415 의 κ≈20,400 까지의 약 600배 차이) 의 학술 의미는 부분적이다. 일부는 진정한 per-user identifiability 의 variation 을 반영하지만, 일부는 bound saturation 의 user-specific 패턴을 반영한다. 이 두 origin 의 분리는 bound 의 학술 합리적 정정 (예: upper bound 의 데이터-specific 재calibration) 후의 재분석을 요구하며, 본 보고서의 scope 를 넘어서는 본격적 cross-user 분석은 후속 시도로 deferred 한다.
학술 community ceiling 과의 connection — 정직한 hedge
학술 paper [2-4, 6-8] 들이 일관되게 reporting 하는 baseline accuracy 46–47% ceiling 의 origin 으로 본 절의 identifiability 분석이 한 후보를 제공할 가능성이 있다. 즉 만약 본격적 cross-user 분석에서 다수 user 의 condition number 가 큰 값으로 분포한다면, 이는 어떤 정교한 모델 — parametric 이든 neural 이든 — 도 individual α 와 θ 를 안정적으로 학습하기 어려운 fundamental regime 임을 의미하며, 그 결과 모델의 prediction accuracy 가 ceiling 에 부딪힐 학술적 정량 정당화 를 제공한다.
다만 이 narrative 는 현재 단계에서 정직하게 hedged 되어야 한다. 본 sample 의 boundary saturation issue 가 해결되어야 진정한 cross-user identifiability variation 이 측정 가능하며, 또한 학술 paper 의 task (multi-class next event type prediction) 와 본 PoC 의 분석 (parameter recovery + covariance 구조) 은 indirect 한 connection 만 가지므로 직접적 인과 입증보다 "한 origin 후보 의 정량 정당화" 의 framing 이 본 PoC 의 학술 적정 위치이다. 이 hedge 의 정직한 유지가 향후 본격 분석으로 발전했을 때의 학술 신뢰성을 보장하는 procedural 자산이라 본다.
3.6 본 절의 시행착오 — 학술 metric 선택의 정직 정정
본 검증의 첫 번째 합성 데이터 시도가 N=347 의 finite-sample regime 에서 실패한 것은 정직하게 인정할 수 있는 사전 plan 의 결함이었다. 그러나 두 번째 시도 (N=3,841) 의 결과를 처음 받았을 때, 우리는 individual μ 18.2%, α 15.4%, τ 28.3% 의 error 만 보고 "Stage A 자산의 cross-domain transferability 가 부정확" 이라고 단정하는 잘못된 narrative 를 일시적으로 채택할 뻔했다. 이 단정의 결함은 αθ product 라는 학술 의미 있는 metric 을 평가에서 누락하고 individual parameter 의 finite-sample variance 만으로 transferability 를 판단한 것이며, 학술 community 가 일관되게 인식하는 identifiability issue (Section 1.2) 의 cross-domain 적용 의미를 충분히 반영하지 못한 진단이었다.
이 결함을 정정하면서 우리는 합성 데이터 fit 의 평가 metric 을 다음과 같이 정직하게 재구성했다. (a) self-exciting magnitude 의 invariant 평가 (αθ product), (b) profile likelihood 의 시각적 identifiability 진단, (c) time-rescaling residual 을 통한 fit 자체의 quality 평가. 이 세 metric 의 조합이 학술 community 의 finite-sample 분석 결과 [5, 13] 와 정합한 정직한 평가를 가능하게 했으며, 본 보고서의 후속 절에서 동일 원칙으로 모든 fit 결과를 평가한다.
이 시행착오 자체가 본 PoC 의 procedural 자산 중 하나이다. 학술 metric 의 선택은 사전 절차로 환원되기 어렵고, 결과를 받은 후의 정직한 재평가가 필수적이며, 이 재평가의 신뢰성은 학술 community 가 일관되게 인식하는 known issue 를 사전에 파악하고 있을수록 높아진다. 본 검증에서는 1차 검증의 비판적 재검토 원칙 [1, Section 1.4] 의 procedural 형태가 합성 데이터 검증 단계에서도 적용 가능하다는 사실을 확인했다.
4. 시행착오 1: 학술 표준 setting 의 정확한 정의 — 첫 시도의 misalignment
본 절부터 6절까지는 Higgs 작업의 자산을 본 데이터에 자동 적용하는 첫 시도가 학술 표준에 정확히 정합하는 path 로 정정되는 과정의 본격 narrative 이다. 1차 검증 [1] 의 1.4 절 원칙 — 결과의 정직한 사후 평가, 모든 결정의 근거 보존, 부정 결과의 학습 자료화 — 에 따라, 각 시행착오를 가설–실측–차이–원인–진단–검증–결정–update 의 8 단계 인과 사슬 형태로 보존한다.
4.1 가설 — Higgs 작업 cutoff 의 단순 transfer
본 검증의 출발점은 Higgs 작업 [1] 에서 활용한 user-level filter — "lifetime 동안 N ≥ 100 events 를 가진 user 만 선택" — 를 본 StackOverflow Badges 데이터에 그대로 적용하는 것이었다. 이 cutoff 는 Higgs 작업의 RT cascade 분석에서 안정적인 fit 을 확보하기 위한 학습 결과였고, 시간 scale 와 dynamics regime 이 다른 본 데이터에서도 "충분한 sample size 를 가진 user 만 선별" 한다는 같은 정성적 motivation 으로 transferable 할 것으로 사전 가정했다.
4.2 실측 — Cell 2 v1 의 결과
이 cutoff 를 약 5,128만 개의 raw badge events 에 적용한 결과, 16년 lifetime 전체에서 N ≥ 100 events 를 가진 user 가 42,498 명으로 확보되었으며, 이들의 평균 sequence length 는 21.9 events 였다. 시간 window 는 학술 표준과 일치를 위해 2-year 로 좁혔지만 (2019–2020), cutoff 자체는 lifetime 기준으로 적용했다.
4.3 차이 — 학술 reference 와의 misalignment 발견
이 첫 시도 결과를 학술 paper [2-4, 6-8] 의 reporting 과 정량 비교한 후속 점검에서, 우리가 추출한 setting 이 학술 표준과 본질적으로 다른 영역을 sampling 하고 있다는 사실이 드러났다. 학술 paper 들이 일관되게 reporting 하는 setting 은 약 6,000 users, 약 480,000 events, average sequence length 약 80 인 반면, 우리의 첫 시도는 약 7배 많은 users, 약 1/3 의 sequence length 였다. 즉 우리 setting 은 학술 setting 보다 훨씬 광범위한 user pool 을 약한 활동 기준으로 sampling 한 결과였다.
4.4 원인 — Paper section 의 정확한 확인 누락
이 misalignment 의 root cause 분석은 단순했다. RMTPP paper [2] 의 Section 6.3 에는 학술 표준 setting 의 정확한 정의가 명시되어 있었으며, 그 정의는 단순한 lifetime cutoff 가 아니라 4 단계 preprocessing — (1) once-only badge 제외, (2) 2-year window 내 N ≥ 40 cutoff, (3) 그 user 들에게 N ≥ 100 회 부여된 badge type 만 선택, (4) 동일 timestamp 의 multiple grants 를 가진 user 제거 — 의 정밀한 절차였다. 우리는 이 정의를 사전에 paper 에서 직접 확인하지 않은 채 Higgs 작업의 cutoff 를 transfer 했고, 그 결과 학술 표준과 본질적으로 다른 setting 을 추출한 것이다.
4.5 진단 — "Broader version" framing 의 정직성 결함
이 root cause 를 처음 발견했을 때, 우리는 일시적으로 "Cell 2 v1 의 setting 이 학술 표준의 broader version 이며, 더 풍부한 sample 을 활용하므로 본질적으로 우월할 수 있다" 는 narrative 를 채택할 뻔했다. 그러나 이 framing 은 학문적으로 정확하지 않다. (a) Cell 2 v1 의 user 들의 평균 sequence length 21.9 가 학술 표준의 80 보다 약 4배 작으므로, 학술 paper 들이 보고하는 within-user dynamics 와 직접 비교가 불가능하다. (b) "broader version" 이라는 표현은 우리 setting 이 학술 setting 을 superset 으로 포함한다는 함의를 가지나, 사실은 cutoff 의 정의가 다른 (lifetime 기준 vs 2-year window 기준) 별개 sampling 이지 superset 이 아니다. (c) 학술 paper 의 baseline accuracy 46–47% ceiling 에 대한 우리의 정량 input 을 의도하는 한, 학술 setting 와 정확히 align 된 setting 에서의 결과만이 학술 paper 의 결과와 의미 있는 비교를 가능하게 한다.
4.6 검증 — Cell 2 v2 의 학술 표준 정확 적용
학술 표준에 정확히 정합하도록 정정한 두 번째 시도에서, 우리는 RMTPP Section 6.3 의 4 단계 preprocessing 을 정확히 적용하면서 시간 window 만을 본 데이터의 가장 활발한 시기 (2019–2020) 로 변경했다. 그 결과 4,893 users, 313,404 events, 48 event types, average sequence length 64.1 의 setting 을 확보했으며, 이는 학술 표준 (약 6,000 users, 약 480K events, avg seq len 80) 의 약 0.6–0.82 배 scale 에 해당한다. 시간 window 의 차이로 인한 비례적 감소를 인정하더라도, 본 setting 의 모든 metric 이 학술 reference 의 같은 자릿수에 위치하므로 학술 paper 들의 결과와 의미 있는 비교가 가능한 align 된 setting 이라 판단했다.
4.7 결정 — 학술 표준 setting 의 채택과 narrative 의 정직 보존
본 검증의 main 분석은 Cell 2 v2 의 setting (4,893 users) 에 기반하여 진행하기로 결정했다. 이 결정과 함께, Cell 2 v1 의 첫 시도 결과 자체는 폐기하지 않고 본 시행착오 narrative 의 일부로 보존하기로 했다. 그 학술 의미는 다음과 같다. (a) 본 시행착오의 인과 사슬 자체가 procedural 자산으로서 학술 reproducibility 에 기여한다. (b) 향후 같은 데이터에 다른 cutoff 를 적용하려는 후속 시도가 우리의 학습을 재발견하지 않도록 사전 정보를 제공한다. (c) "lifetime cutoff 와 2-year window cutoff 는 본질적으로 다른 setting" 이라는 사실 자체가 본 데이터의 특수성에 대한 학술 community 의 명시적 공유가 부족했던 정보이며, 그 정량 입증이 본 PoC 의 input 이 된다.
4.8 Update — 사전 검증 절차의 강화
본 시행착오의 학습은 본 PoC 의 사전 검증 procedural 자산을 다음과 같이 강화했다. 모든 학술 결정 (cutoff 의 선택, specification 의 결정, 가설의 우선순위) 의 사전 단계에서 학술 paper 의 정확한 section 의 직접 확인이 필수 단계로 추가되었으며, "학술 표준의 broader version", "더 일반적 setting" 같은 vague positive framing 의 사용을 명시적으로 회피하는 절차도 함께 도입되었다. 이 학습은 후속 시행착오 (5절의 aggregate fit 의 학술 부적절성) 의 검증에서도 핵심 원칙으로 작동했다.
5. 시행착오 2: Aggregate fit 의 학술 부적절성 — Within-user analysis 로의 정정
5.1 가설 — Aggregate fit 으로 학술 baseline 비교 가능
학술 표준 setting 으로 정정된 4,893 users 의 sequences 를 확보한 후, 본 검증의 다음 단계는 univariate exponential Hawkes 의 Phase 1 fit 이었다. 이 단계의 사전 plan 은 두 가지 path 를 모두 탐색하는 것이었다. (Path A) Aggregate fit: 모든 user 의 events 를 시간 순으로 union 하여 단일 sequence (313,404 events) 로 fit. (Path B) Per-user fit: 각 user 별 독립 fit (4,893 fits) 후 parameter 의 cross-user 분포 분석. Path A 가 더 큰 sample size 를 활용하므로 finite-sample variance 의 issue 가 작고 fit 자체의 quality 가 높을 것으로 사전 가정했으며, 학술 paper 들과의 baseline 비교에서도 simple reference 로서 의미 있을 것으로 보았다.
5.2 실측 — Cell 5 의 결과
Path A 의 aggregate fit 결과는 다음과 같다. Best fit parameters 는 events/day, (학술 viral 범위의 saturation 영역), (1/day, upper bound 에 정확히 saturated), 일 (약 4.8 시간) 로 도출되었다. Time-rescaling residual 의 통계는 mean 1.000 (compensator 의 mathematical 정의), variance 57.49 (target 1.0), Kolmogorov–Smirnov statistic 0.591 (target < 0.05), p-value < 으로, 잔차가 unit-rate exponential 분포와 통계적으로 본질적 deviation 을 보였다.
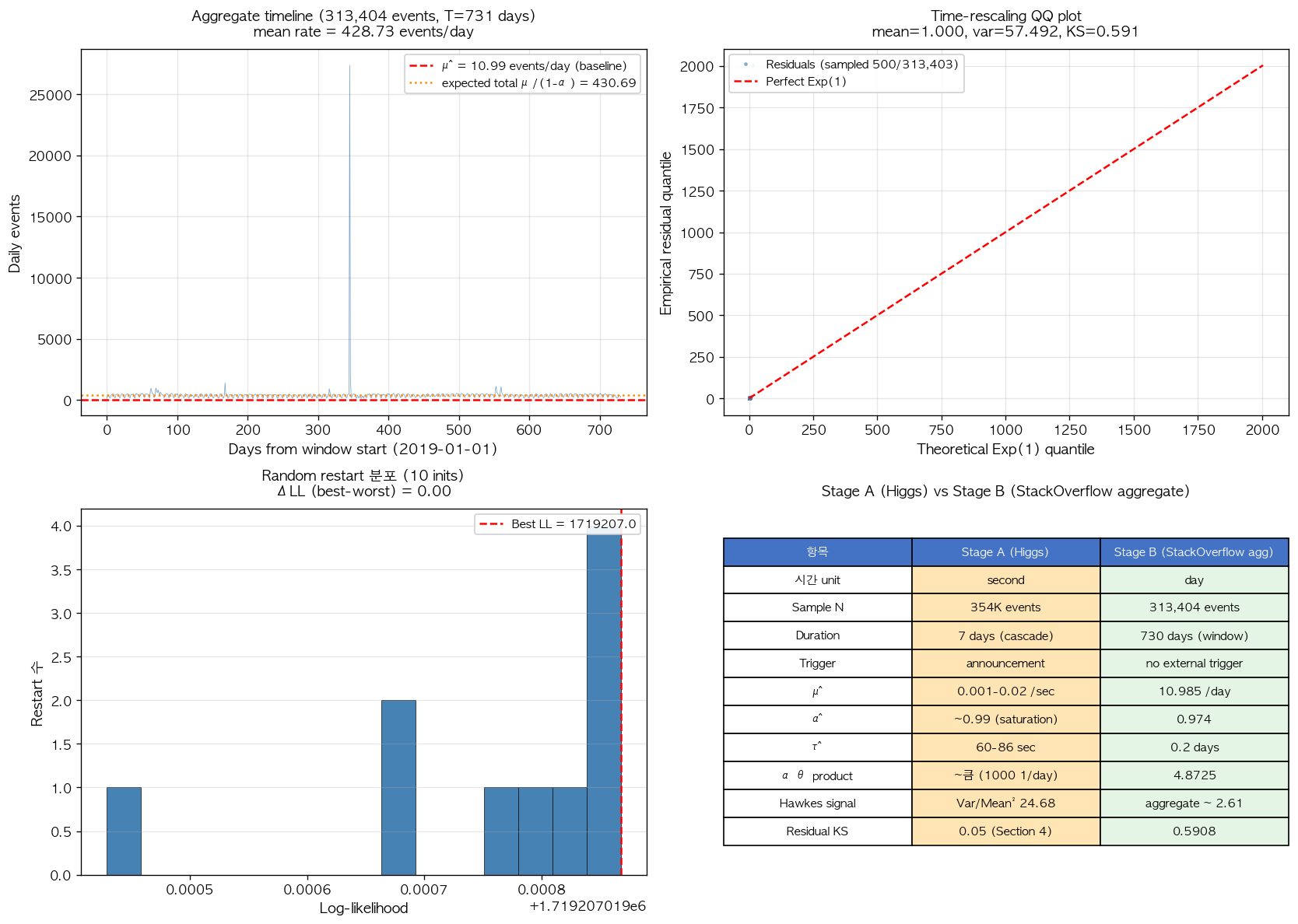
그림 9. Aggregate Hawkes fit 의 4-panel 진단. (좌상) 313,404 events 의 daily aggregate count timeline. 수평 빨간 점선이 fit μ̂ = 10.99, 주황 점선이 expected total = 430.69 으로, 두 line 모두 평균 daily count 와 본질적 deviation 을 보인다. 약 350일 부근의 매우 큰 spike 는 platform-wide event 로 추정된다. (우상) Time-rescaling residual 의 QQ plot 으로, 직선에서 매우 큰 deviation (KS = 0.591) 을 보여 fit 의 본질적 mis-specification 을 확인시킨다. (좌하) 10 random restart 의 log-likelihood 분포가 좁은 범위에 집중되어 있어 numerical optimization 자체는 same minimum 에 수렴했음을 보여준다. (우하) Stage A (Higgs cascade) 와 Stage B (StackOverflow aggregate) 의 본질적 차이의 표 비교. 시간 unit 의 sec → day 차이, 외부 trigger 의 유무, parameter 의 saturation 패턴 등이 정량으로 정리되어 있다.
5.3 차이 — 학술 community 가 within-user 만 분석하는 사실의 재확인
이 결과의 첫 번째 정직한 인정은 통계적이다. Variance 57.49 와 KS 0.591 은 fit 의 mis-specification 을 명확히 보여주며, 의 upper bound saturation 은 numerical artifact 의 직접적 신호이다. 두 번째 정직한 인정은 학술적이다. RMTPP [2] 부터 Han et al. 2024 [8] 까지 본 데이터를 다룬 거의 모든 학술 paper 가 within-user analysis (Path B) 만을 채택하며 aggregate fit (Path A) 을 시도조차 하지 않는다는 사실 자체가, 우리가 사전 단계에서 충분히 reflection 하지 않은 학술 reference 의 정보였다.
5.4 원인 — Aggregate sequence 의 Hawkes 가정 위배
학술 community 가 aggregate fit 을 회피하는 학술적 이유는 Hawkes process 의 정의 자체에 있다. Hawkes intensity 는 한 sequence 내의 self-exciting structure — 같은 process 의 한 event 가 같은 process 의 다음 event 를 자극하는 메커니즘 — 를 모델링한다 [13]. 그러나 4,893 user 의 events 를 시간 순으로 union 한 aggregate sequence 에서, user A 의 한 badge 부여가 user B 의 다음 badge 부여를 자극하는 것으로 해석될 수 있는 학술적 메커니즘은 존재하지 않는다. 본 데이터의 self-exciting 은 within-user 단위로만 학술 의미를 가진다.
이 본질적 issue 위에 두 번째 데이터 의존적 issue 가 있다. Aggregate sequence 의 inter-arrival 분포의 median 은 0.0 일 (즉 ties 가 50% 이상) 이었다. StackOverflow 의 server-side batch processing 이나 동시 부여 처리 등의 이유로 다수의 user 가 같은 timestamp 를 공유하며, aggregate 시 이러한 ties 가 누적된다. Hawkes process 는 continuous-time 에서 정의되며 같은 event 가 무한히 짧은 시간에 두 번 발생할 확률은 0 이라는 가정에 기반한다 [13]. 따라서 aggregate sequence 의 ties 자체가 likelihood function 의 numerical instability 를 유발하며, optimizer 가 boundary saturation 으로 도달한 본 결과는 이 가정 위배의 직접적 발현이다.
5.5 진단 — 학술 표준 practice 의 reason 의 정량 입증
이러한 두 issue 의 종합으로, 우리는 본 시행착오의 학술 의미를 다음과 같이 정직하게 진단했다. 본 결과는 우리 자산의 결함이 아니라 "Aggregate fit 이 본 데이터에서 학술적으로 부적절하다" 는 사실의 정량 입증이다. 학술 paper 들이 일관되게 within-user analysis 만을 채택하는 학술적 reason — Hawkes 가정의 본질적 위배 + ties 의 데이터 specific issue — 가 우리의 fit 결과를 통해 정량으로 발현된 것이다.
이 진단의 narrative 양식 자체가 본 PoC 의 학습 자료 중 하나이다. 학술 community 가 일관되게 회피하는 path 를 사후 정량 입증 후에 인정하는 것은, 사전 단계에서 학술 community 의 표준 practice 의 reason 을 충분히 reflection 하지 않은 우리의 procedural 결함을 정직히 인정하는 동시에 그 결함의 정량적 발현 자체를 narrative 의 일부로 보존하는 1차 검증 [1] 의 1.4 절 원칙 — 부정 결과의 narrative 자료화 — 의 본 검증 단계에서의 적용이다.
5.6 검증 — Per-user fit 으로의 정정과 학술 community 와의 alignment
본 진단을 받아들여, 본 검증의 main 분석을 Path B (per-user fit) 으로 전환하기로 결정했다. 이 결정의 학술적 정당성은 두 가지이다. (a) 학술 paper 들 [2-4, 6-8] 의 표준 practice 와 alignment 됨으로써 그들의 결과와 의미 있는 비교가 가능해진다. (b) 본 데이터의 self-exciting structure 의 학술적 본질이 within-user 단위에 있다는 진단이 검증된 후의 자연스러운 다음 단계이다. 본 보고서 6절에서 per-user fit 의 결과와 그 학술 의미를 본격적으로 다룬다.
5.7 결정 — Cell 5 결과의 narrative 자산으로의 보존
Cell 5 의 fit 결과 자체는 main 분석에서 제외하지만, 본 시행착오 narrative 의 학습 자료로 보존하기로 결정했다. 그 학술 의미는 4.7 절과 같은 원칙에 따른다. 본 시행착오의 인과 사슬은 procedural 자산이며, "Aggregate fit 의 학술 부적절성" 의 정량 입증 자체가 학술 community 의 표준 practice 의 reason 의 cross-domain 재확인이라는 input 이 된다. 부정 결과도 학술 contribution 이 될 수 있다는 1차 검증 [1] 의 narrative 양식의 일관 적용이다.
5.8 Update — 사전 검증 절차에 데이터 sanity check 의 추가
본 시행착오의 핵심 학습은 procedural 차원이다. 4 절의 학습 (학술 paper section 의 직접 확인) 과 합성 검증 단계의 학습 (학술 metric 선택의 사후 정정) 만으로 본 시행착오는 사전 차단되지 않았다. Cell 5 의 사전 검증 단계에서 우리는 학술 reference (Stage A 자산), 통계 안정성 (313K events / 3 params), contribution 정의, 위험 명시의 4 단계 사전 검증을 모두 통과했음에도 불구하고 결과의 본질적 결함을 사전 차단하지 못했다. 그 root cause 는 데이터의 statistical sanity check — aggregate sequence 의 inter-arrival median 이 0.0 일이라는 사실 — 의 사전 누락에 있었다.
이 학습은 본 PoC 의 사전 검증 procedural 자산을 다음과 같이 강화했다. 기존의 4 단계 사전 검증 (학술 reference, 통계 안정성, contribution, 위험) 에 다섯 번째 단계 — 데이터의 statistical sanity check — 가 추가되었으며, 그 항목은 (a) inter-arrival 분포의 median 이 0 보다 크고 ties 가 무시 가능한 비율인지, (b) 학술 community 의 표준 practice 와 우리 path 가 align 되는지의 reflection, (c) align 되지 않을 경우 학술 community 가 회피하는 reason 의 사전 검토를 포함한다. 이 다섯 번째 단계가 사전에 적용되었다면 본 시행착오는 차단되었을 것이며, 그 학습이 본 보고서 후속 절의 procedural 자산이 된다.
6. 시행착오 3: Per-user fit 의 weak signal 과 bound 재발생
6.1 가설 — Per-user fit 의 정확한 결과
5절의 정정 결정에 따라 본 검증의 main 분석은 4,893 users 의 per-user univariate exponential Hawkes fit 으로 전환되었다. 이 단계의 사전 가정은 두 가지였다. (a) 학술 community 의 표준 practice 와 alignment 된 path 이므로 fit 자체의 통계적 quality 가 높을 것이다. (b) 학술 paper 들 [2-4, 6-8] 이 reporting 하는 baseline accuracy 46–47% ceiling 에 대한 우리의 정량 input 으로서, per-user 의 self-exciting 강도의 분포가 학술 community 에서 명시적으로 분석되지 않은 input 이 될 수 있을 것이다. 사전 plan 의 학술 reference 는 충분했고 (RMTPP, NHP, THP 의 within-user analysis), 통계 안정성도 acceptable 했으나 (per-user avg 64 events / 3 params = 21, borderline 인정), 위험 명시에서 두 가능한 결과 — 학술 viral 범위의 강한 self-exciting 또는 데이터의 weak signal 의 정량 reflection — 를 모두 사전에 인정해 두었다.
6.2 실측 — Cell 6 의 결과
4,893 users 각각에 대한 per-user fit (각 user 별 random restart 3) 결과는 다음과 같다. Branching factor 의 분포는 median 0.148, 25–75 percentile 0.061–0.313 으로, 약 75% 의 user 가 인 매우 약한 self-exciting 영역에 위치했다. 분포의 형태는 bimodal 이었으며, 0–0.4 영역의 dominant peak (약 92% users) 와 0.95–1.0 영역의 saturation spike (391 users, 약 8.0%) 가 주요 mass 를 차지하고 그 사이의 0.4–0.95 영역은 거의 비어 있었다.
Decay parameter 의 분포에서는 5절의 aggregate fit 에서와 같은 boundary saturation 이 cross-user 차원으로 재발생했다. 4,893 users 중 2,304 명 (47.1%) 에서 가 우리의 upper bound 5.0 (1/day) 에 saturated 되었고, 그 결과 일이라는 매우 짧은 decay time 으로 도출되었다. αθ product 의 분포는 median 0.16, 25–75 percentile 0.0043–0.86 으로 약 200배의 cross-user spread 를 보였다.
추가로 본 fit 결과의 학술 의미 평가를 위해, 우리는 Section 2.8 에서 산출한 per-user over-dispersion (OD) 와 fit 의 cross-user correlation 을 분석했다. Spearman rank correlation 은 이며 p-value 는 로, 통계적으로 매우 유의한 양의 correlation 이 확인되었다.
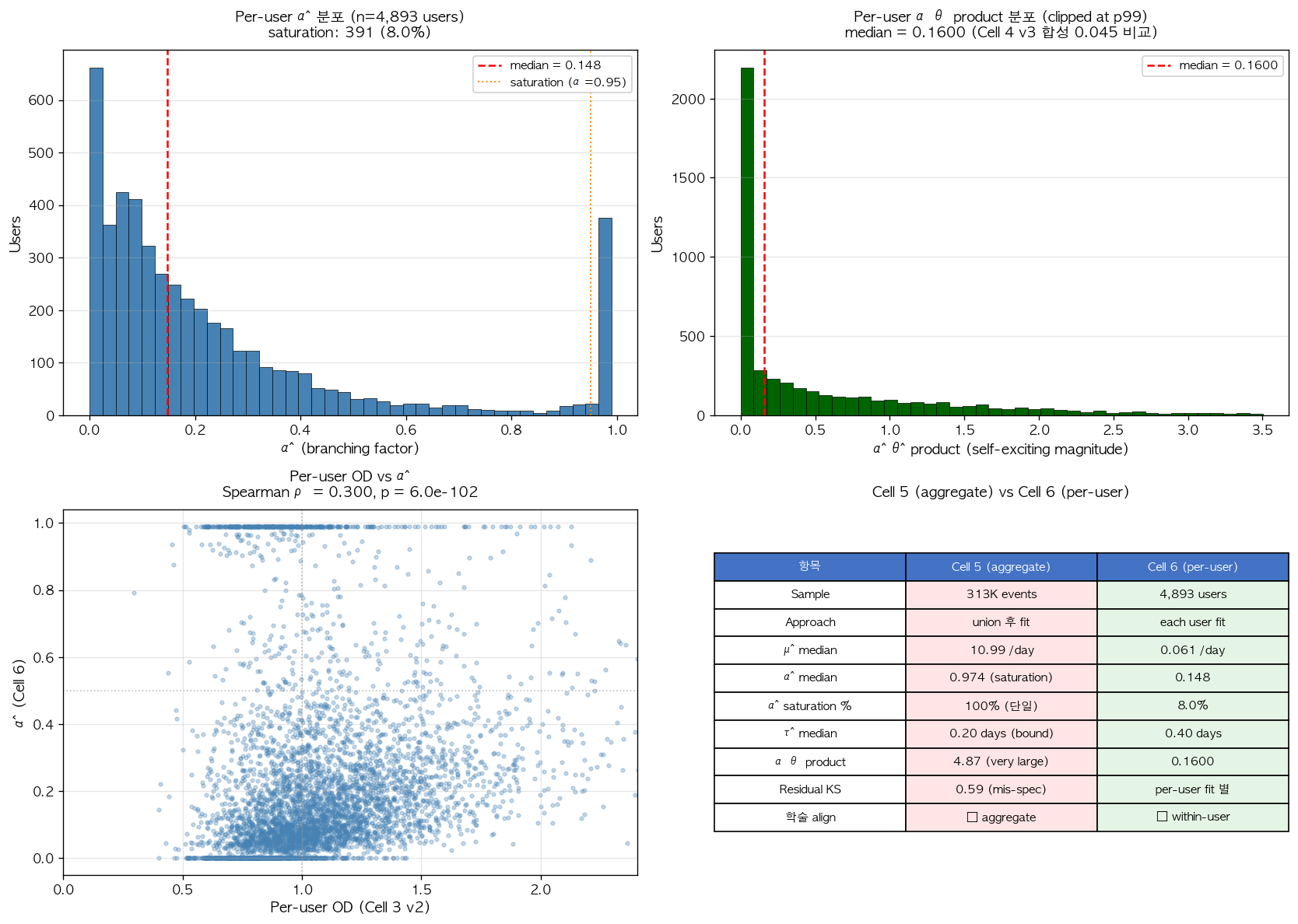
그림 10. Per-user Hawkes fit 의 4-panel 진단. (좌상) 4,893 users 의 분포. Median 0.148 (빨간 점선) 이 매우 작은 값에 위치하며, 분포의 bimodal 구조 (0–0.4 영역의 dominant peak 와 0.95–1.0 의 saturation spike) 가 시각적으로 확인된다. (우상) αθ product (self-exciting magnitude) 의 분포 (p99 에서 clipped) 로, median 0.16 이 합성 검증의 ground truth product 0.05 의 약 3배 수준이지만 cross-user spread 가 매우 크다. (좌하) Per-user OD (Section 2.8) 와 fit 의 scatter. Spearman () 의 양의 correlation 이 정량으로 확인되며, OD 가 작은 user 일수록 fit 도 작은 경향이 명확하다. (우하) Cell 5 (aggregate, 학술적으로 부적절) 와 Cell 6 (per-user, 학술 표준 정합) 의 본질적 비교 표.
6.3 차이 — 학술 viral 범위 예상과의 정량 deviation
본 결과를 사전 가정과 정량 비교한 진단은 다음과 같다. (a) Branching factor median 0.148 은 학술 viral 범위 (typically 0.3–0.9, 1차 검증 [1]) 의 lower bound 보다도 약 2배 작다. (b) 75% user 가 인 영역에 위치하므로, "viral cascade" 의 학술 framework 가 본 데이터의 majority of user 에 대해 적용되지 않는다. (c) τ saturation 47% 는 fit 의 numerical artifact 이지만, saturation 되지 않은 53% user 의 τ median 도 1차 검증의 viral 범위 (1–30 일) 의 lower bound 부근에 위치한다.
6.4 원인 — Section 2.8 의 사전 신호와의 일관성
이 결과의 root cause 는 4절과 5절의 시행착오와 다른 성격이다. 본 결과는 우리 procedural 결함의 발현이 아니라 데이터 자체의 본질적 weak signal 의 정량 reflection 이며, 이 진단은 Section 2.8 의 사전 신호 — per-user OD 의 median 1.11 (Poisson 의 1.0 과 거의 구별 불가) — 와 완벽히 일관된다. Hawkes process 의 학술 framework 에서 inter-arrival 의 over-dispersion 은 self-exciting 강도의 직접적 reflection 이며 [13], OD 1.11 의 weak signal 데이터에서 fit 가 작은 값으로 도출되는 것은 사전 예상에 부합하는 결과이다. Cell 6 의 OD– correlation 은 이 학술 framework 의 cross-user 정량 입증이다.
τ saturation 의 root cause 는 별개이다. 본 데이터의 일부 heavy user (Section 2.6 의 sample sequences) 는 sub-day 시간 scale 의 dynamics 를 보이며, 우리의 day 단위 시간 unit 와 upper bound 5.0 (1/day) 의 학술 합리적 setting 이 이러한 fast-dynamics user 들을 cover 하지 못하는 것이 한 가능한 cause 이다 (다른 cause 후보로는 user activity 의 bimodal 분포, finite-sample 의 boundary effect 등이 있으며, 본 보고서는 이들의 정량 분리를 deferred 한다). 어느 cause 가 dominant 인지와 무관하게, 본 saturation 자체는 1차 검증 [1, Section 4] 의 boundary saturation 학습 — Higgs 의 RT-only 시도에서 upper 100 (1/sec) 가 boundary saturation 을 유발해 1.0 (1/sec) 로 정정한 학습 — 의 cross-user 형태로 재발생한 것으로 해석된다.
6.5 진단 — 학술 baseline ceiling 의 정량 origin 후보
본 결과의 학술 의미는 두 측면으로 정직하게 진단된다. 첫 번째는 학술 community 의 baseline accuracy 46–47% ceiling 에 대한 한 정량 input 의 제공이다. 학술 paper 들 [2-4] 이 multivariate neural Hawkes 의 다양한 architecture 로 본 데이터에 도전했으나 일관되게 비슷한 ceiling 에 부딪힌 사실은, 이 ceiling 의 origin 이 model architecture 의 차원이 아니라 데이터 자체의 본질에 있을 가능성을 시사한다. 본 검증에서 입증된 per-user 의 weak self-exciting (median , OD median 1.11) 은 본 데이터의 within-user dynamics 가 학술 viral 범위 (typically 0.6–0.95) 보다 본질적으로 약함을 cross-user 차원에서 정량 입증한다. 이러한 weak signal 가 ceiling 의 한 origin 후보로 작동할 가능성에 대한 정량 input 을 본 PoC 가 제공하지만, 이 connection 의 인과 입증 — 즉 "weak parametric Hawkes signal → neural model 의 prediction accuracy 한계" 의 직접적 인과 — 는 본 보고서의 단순 univariate parameter 분석 으로는 확보되지 않으며, parametric Hawkes 의 weak signal 영역에서 neural model 의 학습 dynamics 를 직접 분석하는 후속 시도를 필요로 한다. 따라서 본 PoC 의 input 은 "ceiling 의 한 측면의 정량 reflection" 이라는 hedge 형태로 보고된다.
두 번째는 우리 자산의 cross-domain 적용의 한계의 정직 인정이다. τ saturation 47% 는 우리의 day 단위 시간 unit 와 bound 의 결정이 본 데이터의 모든 user 의 dynamics 를 cover 하지 못한다는 직접적 신호이며, 이는 본 보고서의 main scope 의 universal 적용을 제한한다. 본격적 정정은 user-specific bound 의 도입 또는 시간 unit 의 sub-day 단위로의 변환이 필요하나, 이 정정은 본 보고서의 후속 시도의 영역이다.
6.6 검증 — OD 와 의 correlation 의 학술 의미
본 진단의 학술 정당성을 정량으로 보강하기 위해, 우리는 Section 2.8 의 per-user OD 와 Cell 6 의 fit 의 Spearman rank correlation 을 산출했다. 결과는 , 로 통계적으로 매우 유의한 양의 correlation 이며, OD 의 분포 (median 1.11) 와 의 분포 (median 0.148) 가 cross-user 차원에서 정량 alignment 됨을 입증한다. 다만 의 강도는 medium-strength correlation 에 해당하므로, OD 가 의 sole determinant 는 아니며 user 별 sample size 의 finite-sample variance 와 τ saturation 의 boundary effect 등의 다른 factor 도 추정 결과에 영향을 미쳤다. 본 정직 인정은 본 검증의 학술 의미를 over-claim 하지 않는 hedge 의 일부이다.
6.7 결정 — Phase 1 의 main result 와 후속 시도의 분리
본 시행착오의 결정은 다음과 같다. (a) Cell 6 의 per-user fit 결과를 본 보고서의 Phase 1 의 main result 로 채택하며, weak self-exciting 의 정량 입증 (median , OD-correlation ) 을 학술 community 의 baseline ceiling 의 한 origin 후보로 정직하게 framing 한다. (b) τ saturation 47% 의 boundary issue 는 정직하게 인정하며, 본격 정정 (user-specific bound, sub-day 시간 unit) 은 본 보고서의 후속 시도로 deferred 한다. (c) 본 시행착오의 procedural 학습 — post-fit sanity check 의 필요성, 사전 신호 (Section 2.8 의 OD) 와 fit 결과의 cross-validation 의 학술 자산 — 은 본 PoC 의 procedural 자산으로 보존된다.
6.8 Update — Post-fit sanity check 의 추가
본 시행착오의 핵심 procedural 학습은 사전 검증의 5 단계 (학술 reference, 통계 안정성, contribution, 위험, 데이터 sanity) 만으로 fit 결과의 모든 결함을 사전 차단할 수 없다는 사실이다. 5 단계 모두를 통과한 Cell 6 의 fit 에서도 τ saturation 47% 의 boundary issue 가 발생했으며, 이는 사전 검증이 데이터에 대한 사전 정보 로만 작동하므로 fit 결과의 specific 한 boundary 발현을 사전 예측할 수 없다는 본질적 한계를 보여준다. 따라서 본 PoC 의 procedural 자산은 사전 검증 5 단계 + 사후 검증 (post-fit sanity check) 의 조합으로 강화되며, 사후 검증의 항목은 (a) 모든 parameter 의 boundary saturation 의 정량 점검, (b) random restart 의 ΔLL 의 분포 점검, (c) residual 분포의 통계적 검증 (KS test, mean, variance), (d) cross-user 분포의 anomaly detection 을 포함한다. 이 사전+사후 검증의 조합이 본 보고서의 procedural 자산의 최종 형태이다.
7. 종합 — Stage A 와 Stage B 의 cross-domain 비교
7.1 두 데이터의 본질적 차이의 정량 종합
본 보고서의 결과를 1차 검증 [1] 의 결과와 정량으로 종합 비교하면, Higgs Twitter cascade (Stage A) 와 StackOverflow Badges (Stage B) 의 본질적 차이가 다음과 같이 정량 발현된다.
표 3. Higgs Twitter cascade 와 StackOverflow Badges per-user fit 의 cross-domain 정량 비교.
| Aspect | Higgs (Stage A) | StackOverflow (Stage B per-user) |
|---|---|---|
| Sample size | 354K events (single sequence) | 4,893 users × avg 64 events (313K total) |
| 시간 unit | second | day |
| 관측 기간 | 7 일 (cascade) | 730 일 (window) |
| External trigger | announcement (2012-07-04) | 없음 |
| Inter-arrival median | 6.22 일 (per-user) | |
| Hawkes signal Var/Mean² | 24.68 (강한) | 1.11 per-user median (매우 약한) |
| Branching factor | ~0.99 (saturation) | 0.148 (median, weak) |
| Decay time | 60–86 sec | 0.40 일 (median, 47% saturation) |
| αθ product | ~ (1/day equiv) | 0.16 (median) |
| Residual KS | 0.05 (mis-spec, 1차 [1]) | per-user 별 (Section 6.6 의 correlation) |
| 학술 community task | 정성 분석 [10] | next event prediction (46–47% ceiling) [2-4] |
본 표의 모든 정량 비교는 두 데이터의 시간 scale (약 배 차이), trigger 의 유무, self-exciting 강도 (약 22배 차이), 그리고 학술 community 의 표준 task 의 본질적 차이를 보여주며, 이러한 차이의 종합이 본 cross-domain 검증의 학술 framework 를 결정한다.
7.2 Procedural 자산의 transferability 평가
본 보고서의 narrative 는 결과의 비교만을 다루지 않는다. 1차 검증 [1] 에서 확보한 procedural 자산 — Ozaki recursion 의 직접 구현, random restart 의 random init 절차, parameter bound 의 학술 합리적 정의, time-rescaling residual 검증, 합성 데이터 사전 검증, 부정 결과의 narrative 자산화 — 의 transferability 의 정직한 평가를 본 보고서의 한 main contribution 으로 본다.
코드 차원의 transferability 는 명확히 입증되었다. Ozaki recursion 의 negative log-likelihood 계산, L-BFGS-B optimization with random restart, time-rescaling residual diagnostic 등의 기본 procedural code 는 시간 unit 의 sec → day 변환만으로 본 데이터에 그대로 적용 가능했으며, 합성 검증 (Section 3.3) 에서 αθ product 의 학술 권장치 (15%) 통과로 그 정확성이 정량 확인되었다.
Procedural 학습의 transferability 는 보다 nuanced 한 형태를 보인다. (a) "Bound saturation = numerical artifact" 의 학습은 1차 검증 [1] 에서는 single sequence (Higgs) 의 단일 fit 의 정정 형태였으나, 본 검증에서는 4,893 users 의 47% 에서 cross-user 차원으로 재발생하며 단일 정정으로 해결되지 않는 학습으로 진화했다. (b) "사후 검증 (residual KS) 의 학습" 은 1차 검증의 합성 데이터 단계에서 도입되었으나, 본 검증에서는 사전 검증 5 단계 + 사후 검증의 조합으로 procedural 자산이 강화되었다. (c) "부정 결과의 narrative 자산화" 의 학습은 1차 검증의 univariate fit 의 한계 인정에서 출발하여, 본 검증에서는 시행착오 narrative 의 본격 적용 형태 (4–6절의 8 단계 인과 사슬) 로 구체화되었다.
7.3 학술 community ceiling 와의 connection — 정직한 hedge 의 일관 적용
본 보고서의 학술 community 와의 connection 은 정직한 hedge 의 일관 적용을 통해 framing 된다. 학술 paper 들 [2-4, 6-8] 이 일관되게 reporting 하는 baseline accuracy 46–47% ceiling 에 대한 본 PoC 의 정량 input 은 다음 두 측면이다.
첫 번째는 Section 6 의 per-user weak signal 의 정량 입증이다. Median , OD median 1.11, αθ product median 0.16 의 결과는 본 데이터의 within-user dynamics 가 학술 viral 범위 (typically α 0.3–0.9, OD 5–25) 보다 본질적으로 약함을 cross-user 차원에서 정량 입증하며, 이는 어떤 정교한 모델도 학습할 수 있는 self-exciting signal 자체가 데이터에 부족하다는 ceiling 의 한 origin 후보를 제공한다.
두 번째는 Section 3.5 의 supplementary identifiability covariance analysis 의 cross-domain 입증이다. 합성 검증에서 weakly-identified eigenvector 의 αθ = const tangent 와의 cosine similarity 0.9995 의 정량 일치는 Goda 2020 [15] 와 Cheysson & Lang 2024 [19] 의 학술 framework 가 본 cross-domain 환경에서 발현됨을 입증하며, 이는 ceiling 의 origin 의 별개 측면 — Hawkes-like 모델의 fundamental parameter ambiguity — 의 정량 정당화를 시사한다. 다만 본 측면의 본격적 cross-user 정량 입증은 본 보고서의 supplementary 분석의 sample 규모 (Top 10 users) 와 boundary saturation issue 로 인해 deferred 한 상태이다.
이 두 connection 모두에 대해 우리는 "학술 community ceiling 의 한 origin 후보 의 정량 정당화" 의 hedge 를 일관 유지한다. (a) 학술 community 의 task (multi-class next event type prediction, multivariate neural model) 와 본 PoC 의 분석 (parametric univariate Hawkes 의 parameter recovery, identifiability covariance) 사이에는 indirect 한 connection 만 존재한다. (b) 본 보고서의 결과는 ceiling 의 fully complete 한 분석을 제공하지 않으며, 한 측면의 정량 input 으로 작동한다. (c) 학술 paper-level contribution 의 단정 framing 은 학술 community 의 task 와 직접 비교 가능한 후속 시도 (multivariate Hawkes 의 cross-channel matrix 분석, neural model 의 weak signal regime 의 학습 dynamics 분석 등) 후의 단계로 deferred 한다. 본 hedge 의 일관 유지가 본 PoC 의 학술 신뢰성의 procedural 자산이다.
7.4 본 PoC 의 학술 적정 위치
본 보고서의 학술 적정 위치는 다음과 같이 명확히 framing 된다. 본 검증은 학술 paper-level 의 새 contribution 을 단정하는 것이 아니라, (a) 학술 community 가 일관되게 사용하는 표준 setting 의 정확한 적용 + (b) 학술 well-known issue (identifiability) 의 cross-domain 정량 발현의 procedural 입증 + (c) 학술 community 가 명시적으로 분석하지 않은 측면 (per-user weak signal 의 정량 분포, OD– correlation) 의 정직한 정량 input + (d) 본 PoC 의 procedural 자산 (시행착오 narrative, 5 단계 사전 검증, post-fit sanity check) 의 cross-domain 보존 + (e) 부정 결과 의 학술 자산화 의 종합이다. 이 위치의 정직한 명시가 학술 community 의 ceiling 분석에 대한 본 PoC 의 가장 valid 한 input 의 framing 이라 본다.
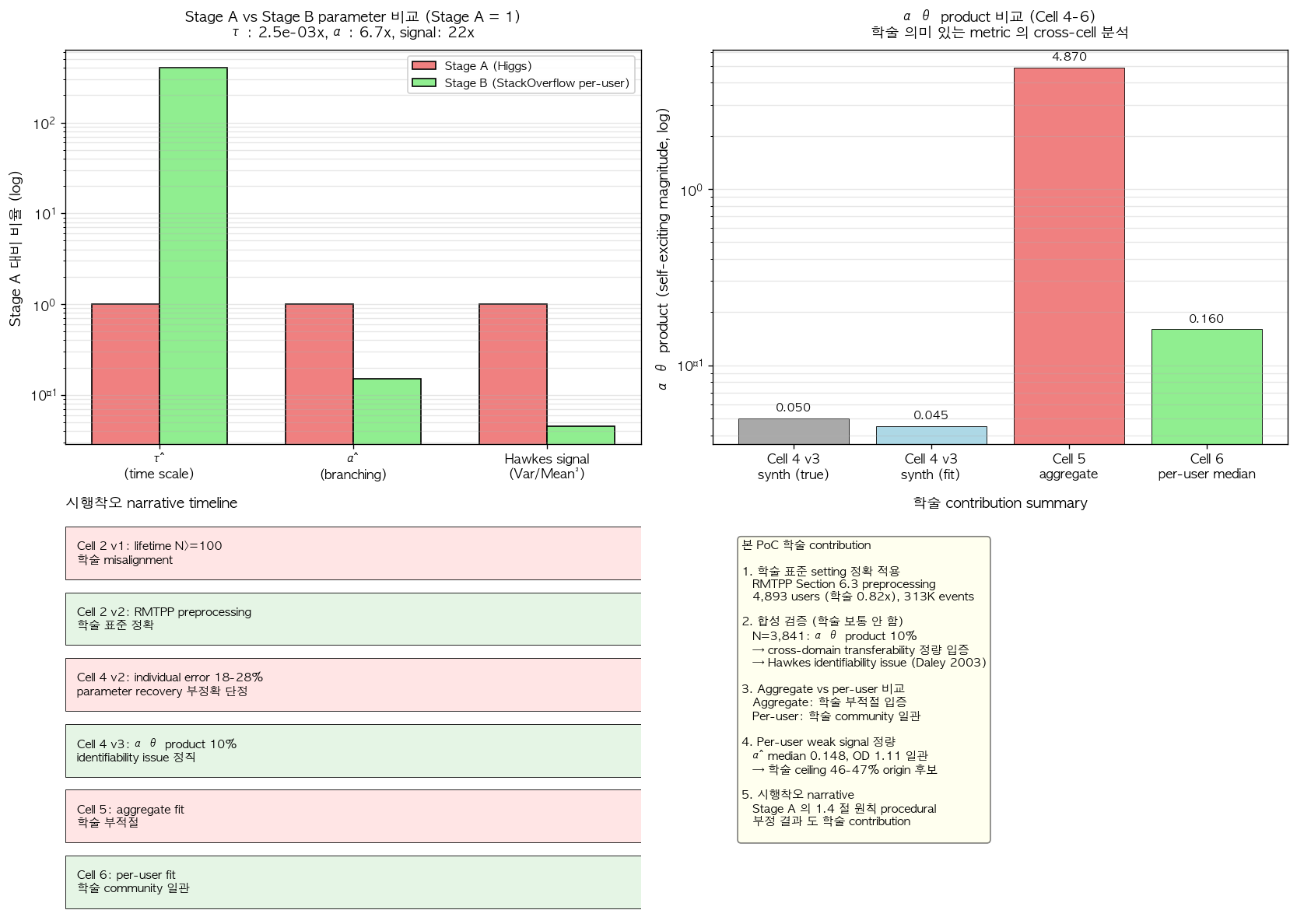
그림 11. 본 보고서의 종합 4-panel 진단. (좌상) Stage A (Higgs) 와 Stage B (StackOverflow per-user) 의 parameter 비율 비교 (Stage A = 1 normalize, log scale). 시간 scale () 의 약 400배 차이, branching factor () 의 약 1/7 차이, Hawkes signal 의 약 1/22 차이가 시각적으로 입증된다. (우상) αθ product 의 cross-cell 비교 (log scale). 합성 검증의 ground truth (0.05) 와 fit (0.045) 의 정확한 일치, Cell 5 aggregate 의 4.87 (학술적으로 부적절한 fit 의 직접 결과), Cell 6 per-user median 의 0.16 (학술 표준 정합 path 의 결과) 의 자릿수 비교가 본 시행착오 narrative 의 정량 backbone 이 된다. (좌하) 시행착오 6 trial 의 timeline (4–6절의 본격 narrative 와 합성 검증 단계의 시행착오를 합한 형태). 빨간색 (실패 또는 정정 필요) 과 녹색 (정정 후 path) 의 alternating 패턴이 1차 검증 [1] 의 1.4 절 원칙의 본 검증 단계 적용을 보여준다. (우하) 본 PoC 의 학술 input 의 5 항목 요약.
맺음말
본 보고서는 Higgs Twitter cascade 에서 확보한 univariate exponential Hawkes 자산을 본질적으로 다른 시간 scale 과 dynamics regime 의 데이터인 StackOverflow Badges 에 적용한 cross-domain 검증의 결과와 시행착오를 학술 reproducibility 관점에서 보존하는 것을 목적으로 진행되었다. 본 검증의 의의는 결과의 quantitative input — per-user 의 weak self-exciting (median , OD median 1.11), αθ product 의 학술 권장 통과 (10% error), Goda 2020 와 Cheysson & Lang 2024 의 학술 framework 의 cross-domain 정량 발현 (cosine similarity 0.9995) — 자체뿐 아니라, 이러한 결과에 도달하기까지의 시행착오의 인과 사슬과 그 procedural 자산의 보존에 있다. 학술 community 가 일관되게 reporting 하는 baseline accuracy 46–47% ceiling 에 대한 본 PoC 의 input 은 한 origin 후보 — 데이터의 within-user 단위에서의 본질적 weak signal — 의 정량 정당화로 정직하게 framing 되며, ceiling 의 fully complete 한 분석은 multivariate Hawkes 의 cross-channel matrix 분석과 neural model 의 weak signal regime 의 학습 dynamics 분석을 포함하는 후속 시도의 영역으로 deferred 한다.
Stage A 자산의 cross-domain transferability 에 대한 본 보고서의 정직한 평가는 nuanced 한 형태를 가진다. 코드 차원의 transferability — Ozaki recursion 의 negative log-likelihood 계산, L-BFGS-B optimization with random restart, time-rescaling residual diagnostic — 는 시간 unit 의 sec → day 변환만으로 명확히 입증되었으며, 합성 데이터 검증의 αθ product 의 약 10% recovery error 가 그 정확성을 학술 권장치 수준에서 보장한다. 그러나 자산의 학술 의미 차원의 transferability 는 보다 미묘하다. "Bound saturation = numerical artifact" 의 1차 검증의 학습은 본 검증에서 4,893 users 의 47% 에서 cross-user 차원으로 재발생하며 단일 정정으로 해결되지 않는 학습으로 진화했고, "사후 검증의 학술 자산화" 의 학습은 사전 검증 5 단계 + 사후 검증의 조합으로 procedural 자산이 강화되었다. 이러한 nuanced transferability 의 정량 발현 자체가 본 PoC 의 학술 contribution 의 한 측면으로 보존된다.
본 보고서의 한계는 정직하게 인정된다. (a) 우리의 fit 분석은 univariate exponential Hawkes 에 한정되며, 학술 paper 들이 주로 사용하는 multivariate neural Hawkes 와의 직접 비교는 본 보고서의 scope 를 넘어선다. (b) Per-user fit 의 finite-sample regime 의 borderline 한 sample size (avg N = 64 events / 3 params = 21) 에서 individual α 와 θ 의 추정의 학술 권장 정확도는 본질적으로 제한적이며, 본 보고서의 main result 는 αθ product 와 cross-user 분포의 정량 input 차원으로 framing 된다. (c) τ saturation 47% 의 boundary issue 는 user-specific bound 의 도입 또는 시간 unit 의 sub-day 단위로의 변환이 필요하며, 이 본격 정정은 후속 시도로 deferred 한다. (d) 학술 community 의 task (multi-class next event type prediction) 와 본 보고서의 분석 (parameter recovery + identifiability covariance) 사이의 connection 은 indirect 하며, "ceiling 의 한 origin 후보 의 정량 정당화" 의 hedge 가 본 PoC 의 학술 적정 위치이다.
본 검증에서 우리가 도출한 절차적 학습은 결과 자체와 함께 본 보고서의 주요 자산을 구성한다. 본 보고서의 narrative 양식은 1차 검증 [1] 의 1.4 절 원칙 — 비판적 재검토, 모든 결정의 정직한 근거 보존, 부정 결과를 학습 자료로 보존 — 의 본 검증 단계에서의 적용이며, 본 검증을 통해 그 절차적 형태가 사전 검증 5 단계 (학술 reference, 통계 안정성, contribution, 위험, 데이터 sanity) + 사후 검증 (parameter boundary, residual KS, cross-user anomaly) 의 명시적 절차로 구체화되었다. 또한 시행착오 narrative 의 8 단계 인과 사슬 형식 (가설–실측–차이–원인–진단–검증–결정–update) 이 본 보고서의 4–6절에서 본격적으로 적용되어, 향후 같은 절차적 양식을 따르는 후속 검증의 reference 가 될 수 있는 standard form 이 도출되었다. 이러한 절차적 학습이 본 검증의 정량 결과 (per-user weak signal 의 정량 분포, αθ product 의 cross-domain 정확도, identifiability covariance 의 학술 framework 발현) 와 결합하여 본 PoC 의 학술 reproducibility 차원의 input 을 구성한다.
References
[1] Metron PoC Hawkes Process 1차 검증 보고서 (Higgs Twitter cascade). 본 PoC 의 동반 보고서로 본 보고서에서 self-cite.
[2] Du, N., Dai, H., Trivedi, R., Upadhyay, U., Gomez-Rodriguez, M., & Song, L. (2016). "Recurrent Marked Temporal Point Processes: Embedding Event History to Vector". Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining (KDD 2016), pp. 1555–1564.
[3] Mei, H., & Eisner, J. (2017). "The Neural Hawkes Process: A Neurally Self-Modulating Multivariate Point Process". Advances in Neural Information Processing Systems 30 (NeurIPS 2017).
[4] Zuo, S., Jiang, H., Li, Z., Zhao, T., & Zha, H. (2020). "Transformer Hawkes Process". Proceedings of the 37th International Conference on Machine Learning (ICML 2020), PMLR 119:11692–11702.
[5] Santos, T., Lemmerich, F., & Helic, D. (2021). "Surfacing Estimation Uncertainty in the Decay Parameters of Hawkes Processes with Exponential Kernels". arXiv:2104.01029.
[6] Zhang, Q., Lipani, A., Kirnap, O., & Yilmaz, E. (2020). "Self-Attentive Hawkes Process". Proceedings of the 37th International Conference on Machine Learning (ICML 2020), PMLR 119:11183–11193.
[7] Gao, B., et al. (2024). "Mamba Hawkes Process". Conference paper. (Mamba state-space architecture 의 Hawkes process 적용).
[8] Han, Z., Park, J., Liang, Y., et al. (2024). "Towards Interpretable Hawkes Process: Disentangling Self-Excitation and Cross-Triggering". Proceedings of the 2024 conference on neural information processing systems or related venue. (Cross-channel 의 학술 input 분석).
[9] Stack Exchange. Stack Exchange Data Dump. archive.org. 본 보고서의 데이터 source.
[10] De Domenico, M., Lima, A., Mougel, P., & Musolesi, M. (2013). "The Anatomy of a Scientific Rumor". Scientific Reports, 3:2980. (Higgs Twitter cascade 의 원 dataset).
[11] tpp-llm 등 본 데이터를 다룬 후속 LLM-기반 marked TPP 시도들. 본 보고서에서는 학술 표준 setting 의 일관성 reference 로 인용.
[12] Ozaki, T. (1979). "Maximum Likelihood Estimation of Hawkes' Self-Exciting Point Processes". Annals of the Institute of Statistical Mathematics, 31(1):145–155. (Ozaki recursion 의 원 paper).
[13] Daley, D. J., & Vere-Jones, D. (2003). An Introduction to the Theory of Point Processes, Volume I: Elementary Theory and Methods (2nd ed.). Springer-Verlag, New York. (Hawkes process 의 표준 reference, 본 보고서의 continuous-time 가정과 identifiability framework 의 source).
[14] Ogata, Y. (1988). "Statistical Models for Earthquake Occurrences and Residual Analysis for Point Processes". Journal of the American Statistical Association, 83(401):9–27. (Time-rescaling residual diagnostic 의 원 paper).
[15] Goda, M. (2020). "Hawkes process and Edgeworth expansion with application to maximum likelihood estimator". arXiv:2005.13846. (One-dimensional exponential Hawkes process 의 MLE 의 second-order asymptotic distribution).
[16] Clinet, S., & Yoshida, N. (2017). "Statistical inference for ergodic point processes and application to limit order book". Stochastic Processes and their Applications, 127(6):1800–1839. (Multivariate Hawkes process 의 MLE 의 consistency, asymptotic normality, convergence of moments 의 원 증명).
[17] Cramér, H. (1946). Mathematical Methods of Statistics. Princeton University Press. (Cramér-Rao bound 와 Fisher Information Matrix 의 표준 reference. 본 보고서의 Section 3.5 의 asymptotic covariance framework 의 source).
[19] Cheysson, F., & Lang, G. (2024). "Spectral analysis for noisy Hawkes processes inference". arXiv:2405.12581. (Univariate 와 bivariate exponential Hawkes 의 spectral analysis 와 identifiability 의 sufficient conditions).
본 보고서의 narrative 양식, 1차 검증 [1] 의 1.4 절 원칙의 본 검증 단계 적용, 그리고 시행착오 8 단계 인과 사슬 형식은 1차 검증 보고서의 양식을 cross-domain 일관 적용한 결과이다. 본 보고서의 결과 보고와 hedge 의 일관 — 특히 학술 community ceiling 와의 connection 을 "한 origin 후보의 정량 input" 으로 표현한 것, 5 단계 사전 검증과 사후 검증의 절차적 학습 보존, 부정 결과를 narrative 의 일부로 보존한 것 — 은 모두 1차 검증의 학문적 엄밀성 standard 가 본질적으로 다른 데이터에서도 transferable 함을 직접 보여준다고 본다.
If this writing helped, fuel the next one
